


Xilinx удваивает Alveo HBM, добавляет кластеризацию для рабочих нагрузок высокопроизводительных вычислений и больших данных
На конференции по суперкомпьютерам SC21 на этой неделе компания Xilinx представила свою плату ускорителя для центров обработки данных Alveo U55C и новое основанное на стандартах решение кластеризации на основе API для массового развертывания ПЛИС. Компания заявила, что, позволяя кластеризовать сотни карт Alveo и обеспечивая высокоуровневое программирование как приложения, так и кластера, эта новая карта упрощает и повышает эффективность горизонтального масштабирования вычислительных возможностей Alveo для рабочих нагрузок высокопроизводительных вычислений (HPC), чем раньше.
Xilinx сказал, что карта Alveo U55C специально создана для рабочих нагрузок высокопроизводительных вычислений и больших данных, предлагая самую высокую плотность вычислений и емкость HBM (память с высокой пропускной способностью) в портфеле ускорителей Alveo. Вместе с новым решением кластеризации на основе Xilinx RoCE v2 широкий спектр заказчиков с крупномасштабными вычислительными рабочими нагрузками теперь может реализовать мощную кластеризацию высокопроизводительных вычислений на основе FPGA с использованием существующей инфраструктуры и сети центра обработки данных. С точки зрения архитектуры ускоритель на основе ПЛИС утверждает, что обеспечивает наивысшую производительность при минимальных затратах для многих рабочих нагрузок с интенсивными вычислениями. Компания представляет основанную на стандартах методологию, которая позволяет создавать кластеры Alveo HPC с использованием существующей инфраструктуры и сети заказчика.
Компания заявила, что это большой шаг вперед для более широкого внедрения Alveo и адаптивных вычислений во всех центрах обработки данных.

В интервью embedded.com Натан Чанг, менеджер по продуктам HPC для центров обработки данных в Xilinx, сказал:«Мы начинаем понимать, что вычислительные ресурсы не всегда являются узким местом. На самом деле, чаще всего это связано с пропускной способностью памяти. Все больше и больше вычислительных проблем ограничивают пропускную способность памяти. Итак, мы уменьшили размер нашей карты до одного слота, а также удвоили HBM на этой карте. Но что еще более важно, мы предоставили возможность масштабирования по этим картам с возможностью создания больших кластеров с сотнями карт и нацеливания на все HBM на этих картах ».
Он продолжил:«Разблокирование пропускной способности для кластеров карт Alveo всегда было большим делом для нашего сообщества. Разработчикам приходилось создавать команды, а затем создавать собственные схемы кластеризации для удовлетворения своих потребностей. Теперь мы предлагаем пакет кластеризации на основе открытых стандартов - это означает, что мы будем использовать RoCE v2 и мосты для центров обработки данных по всему Ethernet с пропускной способностью 200 Гбит / с на каждой карте ».
«Это означает, что в существующей инфраструктуре центров обработки данных вы сможете установить эти карты в существующие серверы, использовать их в существующих сетях Ethernet и конкурировать с InfiniBand по производительности и задержкам».
«Еще один ключевой момент заключается в том, что мы не только создаем пространство для больших рабочих нагрузок, но и делаем Vitis более доступным для сообщества разработчиков. Вам больше не нужно понимать RTL или Verilog. Вы можете программировать карты Alveo и настраивать платы Alveo с помощью существующих языков высокого уровня, таких как C, C ++ и Python ».
Возможности Alveo U55C для высокопроизводительных вычислений и больших данных
Плата Alveo U55C сочетает в себе множество ключевых функций, необходимых для современных рабочих нагрузок высокопроизводительных вычислений. По словам Xilinx, он обеспечивает больший параллелизм конвейеров данных, превосходное управление памятью, оптимизированное перемещение данных по конвейеру и самую высокую производительность на ватт в портфеле Alveo. Карта представляет собой однослотовый форм-фактор полной высоты и половинной длины (FHHL) с небольшой максимальной мощностью 150 Вт. Он предлагает превосходную вычислительную плотность и удваивает HBM2 до 16 ГБ по сравнению с его предшественником, двухслотовой картой Alveo U280. Следовательно, новый U55C обеспечивает больше вычислений в меньшем форм-факторе для создания плотных кластеров на основе ускорителей Alveo. Это нацелено на потоковую передачу данных с высокой плотностью, математику с большим объемом операций ввода-вывода и большие вычислительные проблемы, требующие масштабирования, такие как аналитика больших данных и приложения искусственного интеллекта.
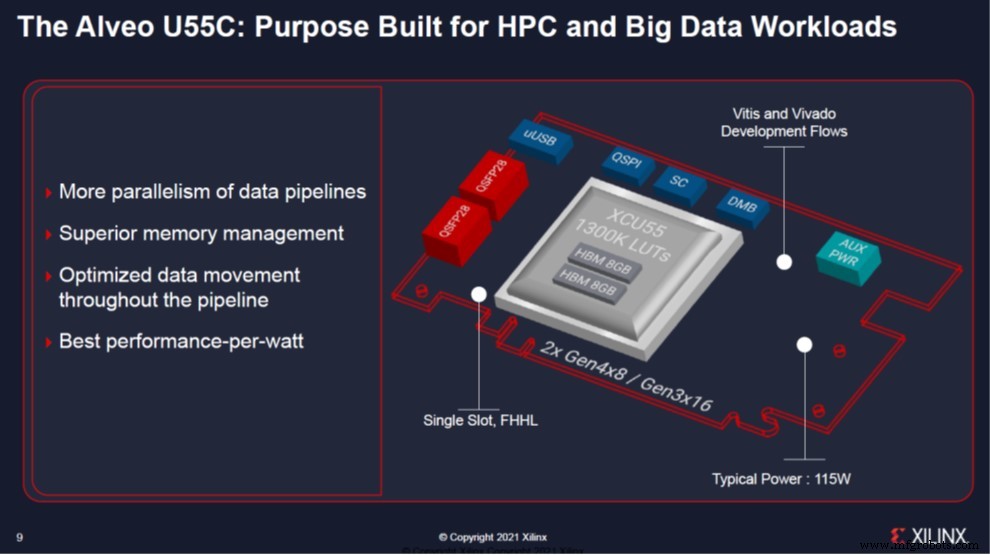
Благодаря использованию RoCE v2 и мостов для центров обработки данных в сочетании с пропускной способностью 200 Гбит / с решение кластеризации на основе API позволяет создать сеть Alveo, которая конкурирует с сетями InfiniBand по производительности и задержкам без привязки к поставщику. Интеграция MPI позволяет разработчикам HPC масштабировать конвейерную обработку данных Alveo с унифицированной программной платформы Xilinx Vitis. Компания заявила, что, используя существующие открытые стандарты и фреймворки, теперь возможно горизонтальное масштабирование для сотен карт Alveo независимо от серверных платформ и сетевой инфраструктуры, а также с общими рабочими нагрузками и памятью.
Разработчики программного обеспечения и специалисты по обработке данных могут получить преимущества Alveo и адаптивных вычислений за счет высокоуровневого программирования как приложения, так и кластера, использующего платформу Vitis. Xilinx заявила, что вложила значительные средства в платформу разработки и поток инструментов Vitis, чтобы сделать адаптивные вычисления более доступными для разработчиков программного обеспечения и специалистов по обработке данных, не имеющих опыта в области аппаратного обеспечения. Поддерживаются основные фреймворки AI, такие как Pytorch и Tensorflow, а также языки программирования высокого уровня, такие как C, C ++ и Python, что позволяет разработчикам создавать решения предметной области с использованием определенных API-интерфейсов и библиотек или использовать комплекты разработки программного обеспечения Xilinx для легкого ускорения ключевых HPC. рабочие нагрузки в существующем центре обработки данных.
Кто использует карты?
Чанг сказал, что компания работает с несколькими организациями над экспериментальными проектами с использованием карт U55C.

Одна из них - это CSIRO, национальная исследовательская организация Австралии вместе с крупнейшей в мире радиоастрономической антенной решеткой, которая использовала U55C, а не графические процессоры, поскольку карта Alveo позволяет использовать однослотовую карту и не требует NIC (сетевой интерфейсной карты). CSIRO использует карты Alveo U55C для обработки сигналов в решетчатых радиотелескопах с квадратными километрами. Развертывание карт Alveo в качестве сетевых ускорителей с HBM обеспечивает высокую пропускную способность в масштабах всего кластера обработки сигналов HPC. Кластер на основе ускорителя Alveo позволяет CSIRO решать масштабную вычислительную задачу по агрегированию, фильтрации, подготовке и обработке данных с 131 000 антенн в реальном времени. 460 Гбит / с полосы пропускания HBM2 в кластере обработки сигналов обслуживается 420 картами Alveo U55C, полностью объединенными в сеть через коммутаторы 100 Гбит / с с поддержкой P4. Кластер Alveo U55C обеспечивает производительность обработки с общей пропускной способностью 15 Тбит / с при компактном энергопотреблении и экономичной занимаемой площади. CSIRO в настоящее время завершает разработку эталонного проекта Alveo, чтобы помочь другим радиоастрономическим или смежным отраслям достичь такого же успеха.
Другой пример использования - программное обеспечение для моделирования аварий ANSYS LS-DYNA, которое используется почти каждой автомобильной компанией в мире. Проектирование систем безопасности и структурных систем зависит от характеристик моделей, поскольку они снижают затраты на физические краш-тесты с помощью моделирования методом конечных элементов (МКЭ) компьютерного проектирования. Решатели FEM - это основные алгоритмы, управляющие моделированием с сотнями миллионов степеней свободы, эти огромные алгоритмы можно разбить на более элементарные решатели, такие как PCG, Sparse matrices, ICCG. Благодаря горизонтальному масштабированию на многих картах Alveo с гиперпараллельной конвейерной обработкой данных LS-DYNA может повысить производительность более чем в 5 раз по сравнению с процессорами x86. Это приводит к увеличению объема работы за такт в конвейере Alveo, при этом клиенты LS-DYNA получают выгоду от времени моделирования, меняющего правила игры. «В духе неустанных инноваций мы рады сотрудничеству с Xilinx для значительного ускорения решателей конечных элементов, которые могут составлять 90% вычислительной нагрузки для неявной механики, в нашем приложении для моделирования LS-DYNA», - сказал Вим Слагтер. , директор по стратегическому партнерству Ansys. «Мы надеемся, что ускорение Xilinx поможет нам в нашей миссии по поддержке новаторов в разработке того, что нас ждет впереди».
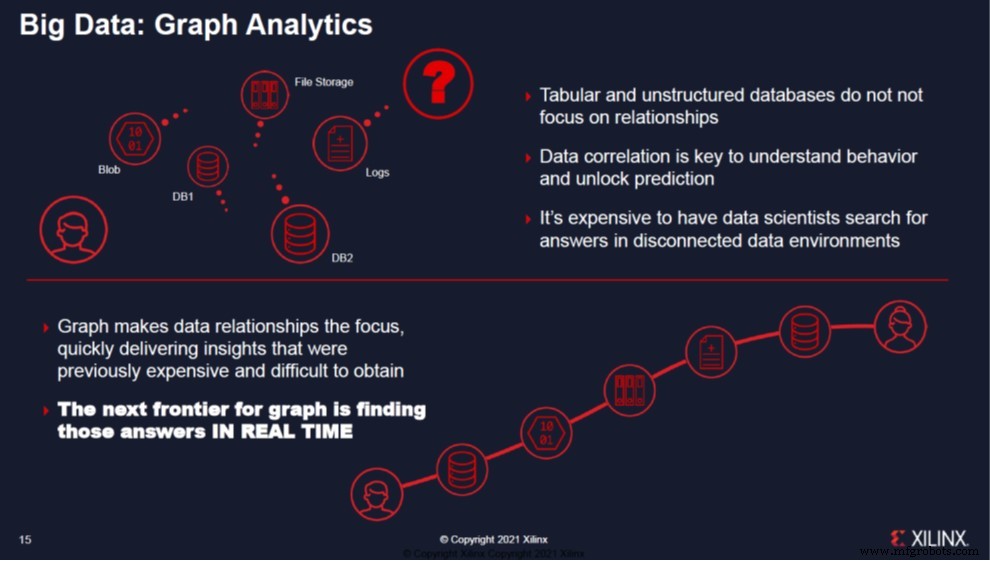
Xilinx привел третий пример - TigerGraph, поставщика ведущей платформы графической аналитики. Компания использует несколько карт Alveo U55C для кластеризации и ускорения двух наиболее эффективных алгоритмов, которые управляют механизмами рекомендаций и кластеризации на основе графиков. Графические базы данных - революционная платформа для специалистов по данным. Графики берут данные из разрозненных хранилищ и акцентируют внимание на взаимосвязях между данными. Следующим этапом развития графа является поиск ответов в режиме реального времени. Alveo U55C ускоряет запросы и прогнозы для механизмов рекомендаций с минут до миллисекунд. За счет использования нескольких карт U55C для масштабирования аналитики, превосходной вычислительной мощности и пропускной способности памяти скорость выполнения графических запросов увеличивается до 45 раз по сравнению с кластерами на базе ЦП. Качество оценок также повышается на 35 процентов, что приводит к большей достоверности и значительному снижению количества ложных срабатываний до однозначных цифр.
Карта Alveo U55C в настоящее время доступна на веб-сайте Xilinx и у официальных дистрибьюторов Xilinx. Он также доступен для оценки через общедоступных облачных провайдеров FPGA-as-a-service, а также через отдельные центры обработки данных для частных предварительных просмотров. Кластеризация доступна для частных предварительных просмотров, а общедоступность ожидается во втором квартале следующего года.
Встроенный
- Siemens добавляет в Veloce беспроблемную аппаратную проверку
- TI:резонаторная технология BAW прокладывает путь для коммуникаций следующего поколения
- DATA MODUL:новая технология склеивания для крупномасштабных проектов
- Cervoz:прочный твердотельный накопитель военного уровня для критически важных приложений
- CEVA:AI-процессор второго поколения для глубоких рабочих нагрузок нейронных сетей
- Kontron:новый стандарт встроенных вычислений COM HPC
- Acceed:модули ввода-вывода для масштабируемой передачи данных
- Четыре большие проблемы для промышленного Интернета вещей
- Могут ли большие данные стать панацеей от скудных бюджетов здравоохранения?
- Большие данные против искусственного интеллекта