


Что такое Hadoop? Обработка больших данных Hadoop
Эволюция больших данных породила новые проблемы, требующие новых решений. Как никогда раньше, серверам необходимо обрабатывать, сортировать и хранить огромные объемы данных в режиме реального времени.
Эта проблема привела к появлению новых платформ, таких как Apache Hadoop, которые могут легко обрабатывать большие наборы данных.
В этой статье вы узнаете, что такое Hadoop, каковы его основные компоненты и как Apache Hadoop помогает в обработке больших данных.
Что такое Hadoop?
Программная библиотека Apache Hadoop – это платформа с открытым исходным кодом, позволяющая эффективно управлять большими данными и обрабатывать их в распределенной вычислительной среде.
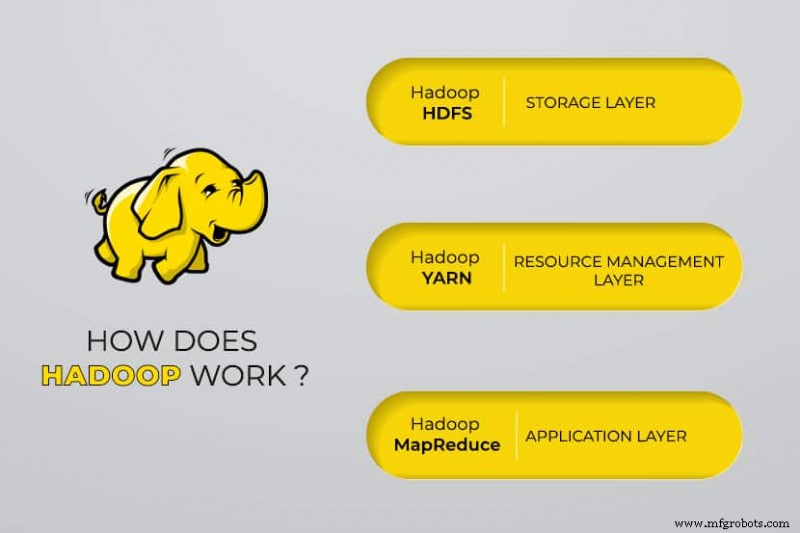
Apache Hadoop состоит из четырех основных модулей. :
Распределенная файловая система Hadoop (HDFS)
Данные находятся в распределенной файловой системе Hadoop, которая похожа на локальную файловую систему на обычном компьютере. HDFS обеспечивает лучшую пропускную способность по сравнению с традиционными файловыми системами.
Кроме того, HDFS обеспечивает отличную масштабируемость. Вы можете легко масштабировать от одной машины до тысяч на обычном оборудовании.
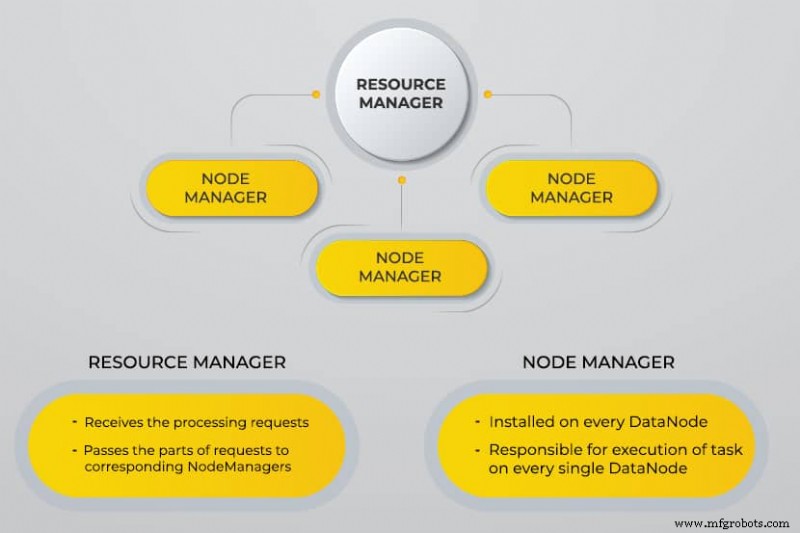
Еще один переговорщик ресурсов (YARN)
YARN упрощает выполнение запланированных задач, полное управление и мониторинг узлов кластера и других ресурсов.
Сокращение карты
Модуль Hadoop MapReduce помогает программам выполнять параллельные вычисления данных. Задача Map MapReduce преобразует входные данные в пары ключ-значение. Задачи сокращения потребляют входные данные, агрегируют их и выдают результат.
Общие решения для Hadoop
Hadoop Common использует стандартные библиотеки Java в каждом модуле.
Зачем был разработан Hadoop?
За последнее десятилетие Всемирная паутина росла в геометрической прогрессии и теперь состоит из миллиардов страниц. Поиск информации в Интернете стал затруднен из-за ее значительного количества. Эти данные стали большими данными, и у них две основные проблемы:
- Сложность хранения всех этих данных эффективным и удобным для извлечения способом.
- Сложность обработки сохраненных данных.
Разработчики работали над многими проектами с открытым исходным кодом, чтобы быстрее и эффективнее возвращать результаты веб-поиска, решая вышеуказанные проблемы. Их решение заключалось в распределении данных и расчетов по кластеру серверов для обеспечения одновременной обработки.
В конце концов, Hadoop стал решением этих проблем и принес множество других преимуществ, в том числе снижение затрат на развертывание сервера.
Как работает обработка больших данных Hadoop?
С помощью Hadoop мы используем возможности хранения и обработки кластеров и реализуем распределенную обработку больших данных. По сути, Hadoop обеспечивает основу для создания других приложений для обработки больших данных.
Приложения, которые собирают данные в разных форматах, сохраняют их в кластере Hadoop через API Hadoop, который подключается к NameNode. NameNode фиксирует структуру каталога файлов и размещение «фрагментов» для каждого созданного файла. Hadoop реплицирует эти фрагменты между узлами данных для параллельной обработки.
MapReduce выполняет запросы данных. Он отображает все узлы данных и сокращает задачи, связанные с данными в HDFS. Само название «MapReduce» описывает, что он делает. Задачи сопоставления выполняются на каждом узле для предоставленных входных файлов, а редукторы запускаются для связывания данных и организации окончательного вывода.
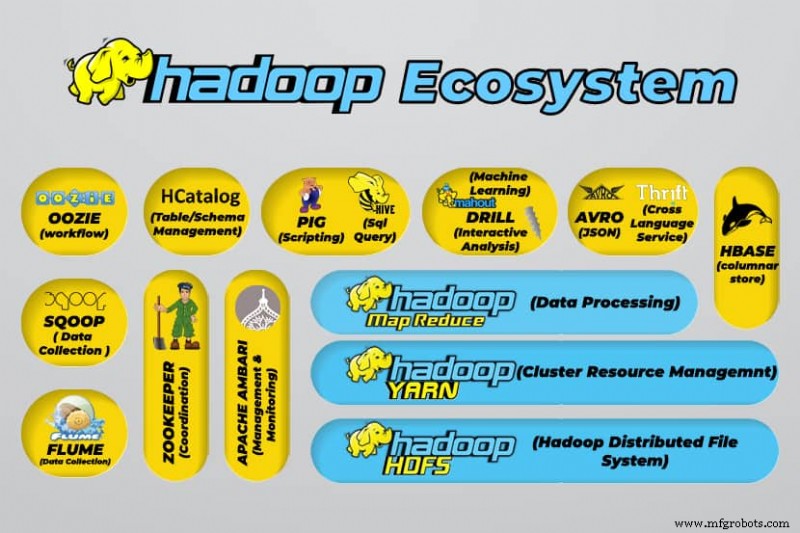
Инструменты больших данных Hadoop
Экосистема Hadoop поддерживает множество инструментов для работы с большими данными с открытым исходным кодом. Эти инструменты дополняют основные компоненты Hadoop и повышают его способность обрабатывать большие данные.
К наиболее полезным инструментам обработки больших данных относятся:
- Улей Apache
Apache Hive — это хранилище данных для обработки больших наборов данных, хранящихся в файловой системе Hadoop.
- Apache Zookeeper
Apache Zookeeper автоматизирует аварийное переключение и снижает влияние отказа NameNode.
- Apache HBase
Apache HBase — это несвязанная база данных с открытым исходным кодом для Hadoop.
- Apache Flume
Apache Flume – это распределенная служба для потоковой передачи больших объемов данных журнала.
- Apache Sqoop
Apache Sqoop – это инструмент командной строки для переноса данных между Hadoop и реляционными базами данных.
- Свинья Apache
Apache Pig — это платформа разработки Apache для разработки заданий, которые выполняются в Hadoop. Используемый язык программного обеспечения — Pig Latin.
- Апач Узи
Apache Oozie – это система планирования, упрощающая управление заданиями Hadoop.
- Каталог Apache HC
Apache HCatalog – это инструмент управления хранилищем и таблицами для сортировки данных из различных инструментов обработки данных.
Преимущества Hadoop
Hadoop — это надежное решение для обработки больших данных, которое является важным инструментом для предприятий, работающих с большими данными.
Основные функции и преимущества Hadoop подробно описаны ниже:
- Более быстрое хранение и обработка больших объемов данных
Объем хранимых данных резко увеличился с появлением социальных сетей и Интернета вещей (IoT). Хранение и обработка этих наборов данных имеют решающее значение для компаний, которым они принадлежат. - Гибкость
Гибкость Hadoop позволяет сохранять неструктурированные типы данных, такие как текст, символы, изображения и видео. В традиционных реляционных базах данных, таких как РСУБД, вам нужно будет обработать данные перед их сохранением. Однако в Hadoop предварительная обработка данных не требуется, поскольку вы можете хранить данные как есть и решать, как их обрабатывать позже. Другими словами, она ведет себя как база данных NoSQL. - Вычислительная мощность
Hadoop обрабатывает большие данные с помощью модели распределенных вычислений. Эффективное использование вычислительной мощности делает его быстрым и эффективным. - Сниженная стоимость
Многие команды отказались от своих проектов до появления таких фреймворков, как Hadoop, из-за высоких затрат, которые они понесли. Hadoop – это платформа с открытым исходным кодом, которую можно использовать бесплатно, и для хранения данных в ней используется дешевое аппаратное обеспечение. - Масштабируемость
Hadoop позволяет быстро масштабировать систему без особого администрирования, просто изменив количество узлов в кластере. - Отказоустойчивость
Одним из многих преимуществ использования модели распределенных данных является ее способность выдерживать сбои. Hadoop не зависит от оборудования для поддержания доступности. Если устройство выходит из строя, система автоматически перенаправляет задачу на другое устройство. Отказоустойчивость возможна, поскольку избыточные данные поддерживаются за счет сохранения нескольких копий данных в кластере. Другими словами, высокая доступность поддерживается на программном уровне.
Три основных варианта использования
Обработка больших данных
Мы рекомендуем Hadoop для больших объемов данных, обычно в диапазоне петабайт и более. Он лучше подходит для больших объемов данных, требующих огромной вычислительной мощности. Hadoop может быть не лучшим вариантом для организации, которая обрабатывает небольшие объемы данных в диапазоне нескольких сотен гигабайт.
Хранение разнообразного набора данных
Одним из многих преимуществ использования Hadoop является его гибкость и поддержка различных типов данных. Независимо от того, состоят ли данные из текста, изображений или видеоданных, Hadoop может эффективно их хранить. Организации могут выбирать способ обработки данных в зависимости от своих требований. Hadoop обладает характеристиками озера данных, поскольку обеспечивает гибкость в отношении хранимых данных.
Параллельная обработка данных
Алгоритм MapReduce, используемый в Hadoop, организует параллельную обработку хранимых данных, что означает, что вы можете выполнять несколько задач одновременно. Однако совместные операции не допускаются, поскольку это запутывает стандартную методологию в Hadoop. Он включает параллелизм, если данные независимы друг от друга.
Для чего Hadoop используется в реальном мире
Компании со всего мира используют системы обработки больших данных Hadoop. Ниже перечислены некоторые из множества практических применений Hadoop:
- Понимание требований клиентов
В настоящее время Hadoop оказался очень полезным для понимания требований клиентов. Крупные компании в финансовой индустрии и социальных сетях используют эту технологию, чтобы понять требования клиентов, анализируя большие данные об их деятельности.
Компании используют эти данные для предоставления клиентам персонализированных предложений. Возможно, вы столкнулись с этим из-за рекламы, отображаемой в социальных сетях и на сайтах электронной коммерции в зависимости от наших интересов и активности в Интернете. - Оптимизация бизнес-процессов
Hadoop помогает оптимизировать производительность бизнеса за счет лучшего анализа данных о транзакциях и клиентах. Анализ тенденций и прогнозный анализ могут помочь компаниям настроить свои продукты и запасы для увеличения продаж. Такой анализ будет способствовать лучшему принятию решений и приведет к увеличению прибыли.
Кроме того, компании используют Hadoop для улучшения своей рабочей среды, отслеживая поведение сотрудников и собирая данные об их взаимодействии друг с другом. - Улучшение медицинского обслуживания
Учреждения медицинской отрасли могут использовать Hadoop для мониторинга огромного количества данных о проблемах со здоровьем и результатах лечения. Исследователи могут анализировать эти данные, чтобы выявлять проблемы со здоровьем, прогнозировать лекарства и принимать решения о планах лечения. Такие улучшения позволят странам быстро улучшить свои медицинские услуги. - Финансовая торговля
Hadoop обладает сложным алгоритмом сканирования рыночных данных с предопределенными настройками для выявления торговых возможностей и сезонных тенденций. Финансовые компании могут автоматизировать большинство этих операций благодаря надежным возможностям Hadoop. - Использование Hadoop для Интернета вещей
Устройства IoT зависят от доступности данных для эффективной работы. Производители и изобретатели используют Hadoop в качестве хранилища данных для миллиардов транзакций. Поскольку IoT — это концепция потоковой передачи данных, Hadoop — подходящее и практичное решение для управления огромными объемами данных, которые он охватывает.
Hadoop постоянно обновляется, что позволяет нам улучшать инструкции, используемые с платформами Интернета вещей.
Другое практическое применение Hadoop включает в себя повышение производительности устройств, улучшение персонального количественного анализа и оптимизацию производительности, совершенствование спортивных и научных исследований.
Какие проблемы возникают при использовании Hadoop?
Каждое приложение имеет как преимущества, так и проблемы. Hadoop также представляет несколько проблем:
- Алгоритм MapReduce не всегда является решением
Алгоритм MapReduce поддерживает не все сценарии. Он подходит для простых информационных запросов и вопросов, которые можно разделить на независимые блоки, но не для повторяющихся задач.
MapReduce неэффективен для расширенных аналитических вычислений, так как итерационные алгоритмы требуют интенсивного взаимодействия и создают несколько файлов на этапе MapReduce. - Полностью развитое управление данными
Hadoop не предоставляет комплексных инструментов для управления данными, метаданными и управлением данными. Кроме того, в нем отсутствуют инструменты, необходимые для стандартизации данных и определения качества. - Недостаток талантов
Из-за крутой кривой обучения Hadoop может быть трудно найти программистов начального уровня с навыками Java, достаточными для продуктивной работы с MapReduce. Эта интенсивность является основной причиной того, что провайдеры заинтересованы в размещении технологии реляционных (SQL) баз данных поверх Hadoop, потому что гораздо легче найти программистов с хорошими знаниями SQL, а не с навыками MapReduce.
Администрирование Hadoop — это и искусство, и наука, требующие базовых знаний об операционных системах, оборудовании и настройках ядра Hadoop. - Безопасность данных
Протокол аутентификации Kerberos — важный шаг к обеспечению безопасности сред Hadoop. Безопасность данных имеет решающее значение для защиты систем больших данных от проблем с безопасностью фрагментированных данных.
Заключение
Hadoop очень эффективно справляется с обработкой больших данных при эффективном внедрении с шагами, необходимыми для преодоления его проблем. Это универсальный инструмент для компаний, работающих с большими объемами данных.
Одним из его основных преимуществ является то, что он может работать на любом оборудовании, а кластер Hadoop может быть распределен между тысячами серверов. Такая гибкость особенно важна в средах с инфраструктурой как кодом.
Облачные вычисления
- Большие данные и облачные вычисления:идеальное сочетание
- Что такое облачная безопасность и почему она требуется?
- Какая связь между большими данными и облачными вычислениями?
- Использование больших данных и облачных вычислений в бизнесе
- Чего ожидать от платформ Интернета вещей в 2018 г.
- Профилактическое обслуживание - что вам нужно знать
- Что такое оперативная память DDR5? Возможности и доступность
- Что такое Интернет вещей?
- Большие данные против искусственного интеллекта
- Построение больших данных из малых данных