


Как создать вариационный автоэнкодер с TensorFlow
Изучите ключевые части автокодировщика, узнайте, как вариационный автокодировщик улучшает его, и как построить и обучить вариационный автокодировщик с помощью TensorFlow.
На протяжении многих лет мы видели, как во многих областях и отраслях возможности искусственного интеллекта (ИИ) расширяют границы исследований. Сжатие и реконструкция данных не является исключением, когда применение искусственного интеллекта может быть использовано для создания более надежных систем.
В этой статье мы рассмотрим очень популярный вариант использования ИИ для сжатия данных и восстановления сжатых данных с помощью автоэнкодера.
Приложения автоэнкодера
Автоэнкодеры привлекли внимание многих специалистов по машинному обучению, что стало очевидным благодаря усовершенствованию автоэнкодеров и изобретению нескольких вариантов. Они принесли многообещающие (если не самые современные) результаты в нескольких областях, таких как нейронный машинный перевод, открытие лекарств, шумоподавление изображений и некоторых других.
Части автоэнкодера
Автоэнкодеры, как и большинство нейронных сетей, обучаются, распространяя градиенты в обратном направлении для оптимизации набора весов, но самое разительное различие между архитектурой автоэнкодеров и архитектурой большинства нейронных сетей - это узкое место. Это узкое место является средством сжатия наших данных в представление более низких измерений. Двумя другими важными частями автоэнкодера являются кодировщик и декодер.
Объединение этих трех компонентов вместе образует "ванильный" автокодер, хотя более сложные из них могут иметь некоторые дополнительные компоненты.
Давайте рассмотрим эти компоненты по отдельности.
Кодировщик
Это первый этап сжатия и восстановления данных, и он фактически отвечает за этап сжатия данных. Кодер - это нейронная сеть с прямой связью, которая принимает функции данных (например, пиксели в случае сжатия изображения) и выводит скрытый вектор с размером, меньшим, чем размер функций данных.
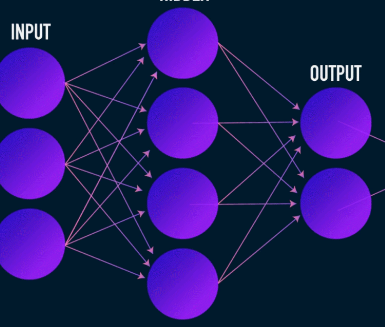
Изображение предоставлено Джеймсом Лоем
Чтобы сделать реконструкцию данных надежной, кодировщик оптимизирует свои веса во время обучения, чтобы сжать наиболее важные особенности представления входных данных в скрытый вектор небольшого размера. Это гарантирует, что декодер имеет достаточно информации о входных данных для восстановления данных с минимальными потерями.
Скрытый вектор (узкое место)
Узкое место или скрытый векторный компонент автоэнкодера является наиболее важной частью, и это становится еще более важным, когда нам нужно выбрать его размер.
Выходные данные кодировщика - это то, что дает нам скрытый вектор и, как предполагается, содержит наиболее важные представления функций наших входных данных. Он также служит входом для части декодера и передает полезное представление декодеру для восстановления.
Выбор меньшего размера для скрытого вектора означает, что мы получаем представление функций входных данных с меньшим количеством информации о входных данных. Выбор гораздо большего размера скрытого векторного размера преуменьшает саму идею сжатия с помощью автокодировщиков, а также увеличивает вычислительные затраты.
Декодер
На этом этапе завершается процесс сжатия и восстановления данных. Как и кодировщик, этот компонент также является нейронной сетью с прямой связью, но внешне немного отличается от кодировщика. Это различие связано с тем, что декодер принимает в качестве входных данных скрытый вектор меньшего размера, чем выходной вектор декодера.
Функция декодера состоит в том, чтобы генерировать выходной сигнал из скрытого вектора, который очень близок к входному.
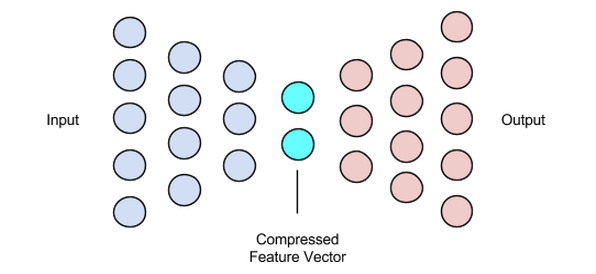
Изображение предоставлено Чиман Кван
Обучение автоэнкодеров
Обычно при обучении автоэнкодеров мы собираем эти компоненты вместе, а не по отдельности. Мы обучаем их от начала до конца с помощью алгоритма оптимизации, такого как градиентный спуск или оптимизатора ADAM.
Функции потерь
Одна часть процедуры обучения автоэнкодера, которую стоит обсудить, - это функция потерь. Реконструкция данных - это задача генерации, и, в отличие от других задач машинного обучения, где наша цель - максимизировать вероятность предсказания правильного класса, мы заставляем нашу сеть производить выходные данные, близкие к входным.
Мы можем достичь этой цели с помощью нескольких функций потерь, таких как l1, l2, среднеквадратичная ошибка и некоторые другие. Что общего у этих функций потерь, так это то, что они измеряют разницу (т.е. насколько далеко или идентичны) между вводом и выводом, что делает любую из них подходящим выбором.
Сети автоэнкодера
Все это время мы использовали многослойный перцептрон для разработки как кодировщика, так и декодера, но оказалось, что мы можем использовать более специализированные структуры, такие как сверточные нейронные сети (CNN), для сбора более пространственной информации о наших входных данных в случай сжатия данных изображения.
Удивительно, но исследования показали, что повторяющиеся сети, используемые в качестве автокодировщиков для текстовых данных, работают очень хорошо, но мы не собираемся углубляться в это в рамках данной статьи. Концепция кодировщика-скрытого векторного декодера, используемого в многослойном персептроне, все еще актуальна для сверточных автокодировщиков. Единственная разница в том, что мы проектируем декодер и кодировщик со сверточными слоями.
Все эти сети автокодировщиков вполне подходят для задачи сжатия, но есть одна проблема.
Обсуждаемые нами сети не обладают творческим потенциалом. Под нулевым творчеством я подразумеваю то, что они могут генерировать только те результаты, которые они видели или которым научили.
Мы можем повысить уровень творчества, немного изменив дизайн нашей архитектуры. Результат известен как вариационный автокодировщик.
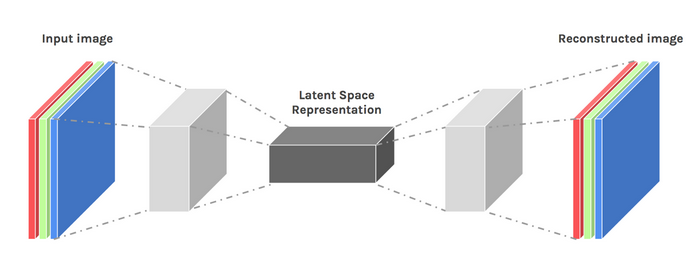
Изображение предоставлено Давидом Копчиком
Вариационный автоэнкодер
В вариационный автоэнкодер внесены два основных конструктивных изменения:
- Вместо преобразования входных данных в скрытую кодировку мы выводим два вектора параметров:среднее значение и дисперсию.
- Дополнительный член потерь, называемый потерями из-за дивергенции KL, добавляется к начальной функции потерь.
Идея вариационного автоэнкодера заключается в том, что мы хотим, чтобы наш декодер реконструировал наши данные с использованием скрытых векторов, выбранных из распределений, параметризованных вектором среднего и вектором дисперсии, сгенерированным кодировщиком.
Функции выборки из распределения предоставляют декодеру контролируемое пространство для генерации. После обучения вариационного автоэнкодера всякий раз, когда мы выполняем прямой проход с входными данными, кодировщик генерирует вектор среднего и дисперсии, ответственный за определение распределения, из которого следует производить выборку скрытого вектора.
Средний вектор определяет, где должно быть сосредоточено кодирование входных данных, а дисперсия определяет радиальное пространство или круг, в котором мы хотим выбрать кодировку, чтобы сгенерировать реалистичный вывод. Это означает, что при каждом прямом проходе с одними и теми же входными данными наш вариационный автокодировщик может генерировать различные варианты выходных данных с центром вокруг среднего вектора и в пределах пространства дисперсии.
Для сравнения:когда мы смотрим на стандартный автокодировщик, когда мы пытаемся сгенерировать результат, на котором сеть не обучена, он генерирует нереалистичные результаты из-за разрыва в скрытом векторном пространстве, создаваемом кодировщиком.
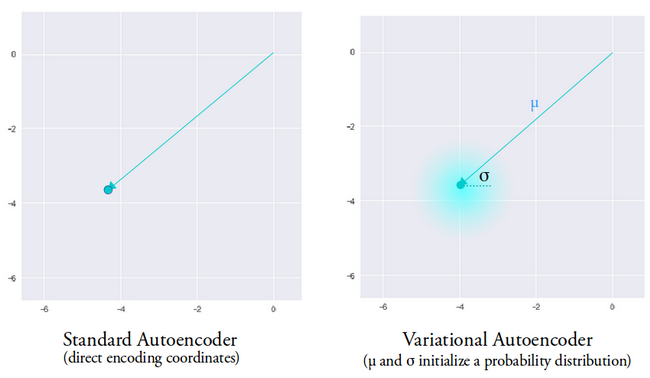
Изображение предоставлено Ирхумом Шафкатом
Теперь, когда у нас есть интуитивное понимание вариационного автокодировщика, давайте посмотрим, как его создать в TensorFlow.
Код TensorFlow для вариационного автоэнкодера
Мы начнем наш пример с подготовки нашего набора данных. Для простоты мы будем использовать набор данных MNIST.
(train_images, _), (test_images, _) =tf.keras.datasets.mnist.load_data ()
train_images =train_images.reshape (train_images.shape [0], 28, 28, 1) .astype ('float32')
test_images =test_images.reshape (test_images.shape [0], 28, 28, 1) .astype ('float32')
# Нормализация изображений до диапазона [0., 1.]
train_images / =255
test_images / =255
# Бинаризация
train_images [train_images> =.5] =1
train_images [train_images <.5] =0
test_images [test_images> =.5] =1
test_images [test_images <.5] =0.
TRAIN_BUF =60000
BATCH_SIZE =100
TEST_BUF =10000
train_dataset =tf.data.Dataset.from_tensor_slices (train_images) .shuffle (TRAIN_BUF) .batch (BATCH_SIZE)
test_dataset =tf.data.Dataset.from_tensor_slices (test_images) .shuffle (TEST_BUF) .batch (BATCH_SIZE)
Получите набор данных и подготовьте его для выполнения задачи.
класс CVAE (tf.keras.Model):
def __init __ (self, latent_dim):
super (CVAE, self) .__ init __ ()
self.latent_dim =latent_dim
self.inference_net =tf.keras.Sequential (
[
tf.keras.layers.InputLayer (input_shape =(28, 28, 1)),
tf.keras.layers.Conv2D (
filters =32, kernel_size =3, strides =(2, 2), activate ='relu'),
tf.keras.layers.Conv2D (
filters =64, kernel_size =3, strides =(2, 2), activate ='relu'),
tf.keras.layers.Flatten (),
# Без активации
tf.keras.layers.Dense (latent_dim + latent_dim),
]
)
self.generative_net =tf.keras.Sequential (
[
tf.keras.layers.InputLayer (input_shape =(latent_dim,)),
tf.keras.layers.Dense (единицы =7 * 7 * 32, активация =tf.nn.relu),
tf.keras.layers.Reshape (target_shape =(7, 7, 32)),
tf.keras.layers.Conv2DTranspose (
filters =64,
kernel_size =3,
strides =(2, 2),
padding ="SAME",
Activation ='relu'),
tf.keras.layers.Conv2DTranspose (
filters =32,
kernel_size =3,
strides =(2, 2),
padding ="SAME",
Activation ='relu'),
# Без активации
tf.keras.layers.Conv2DTranspose (
filters =1, kernel_size =3, strides =(1, 1), padding ="SAME"),
]
)
@ tf.function
def sample (self, eps =None):
, если eps равен None:
eps =tf.random.normal (shape =(100, self.latent_dim))
вернуть self.decode (eps, apply_sigmoid =True)
def encode (self, x):
среднее, logvar =tf.split (self.inference_net (x), num_or_size_splits =2, axis =1)
вернуть среднее значение, логарифм
def reparameterize (self, mean, logvar):
eps =tf.random.normal (shape =mean.shape)
вернуть eps * tf.exp (logvar * .5) + mean
def decode (self, z, apply_sigmoid =False):
logits =self.generative_net (z)
if apply_sigmoid:
probs =tf.sigmoid (логиты)
вернуть запросы
вернуть логиты
Два фрагмента кода подготавливают наш набор данных и строят нашу вариационную модель автоэнкодера. Во фрагменте кода модели есть несколько вспомогательных функций для выполнения кодирования, выборки и декодирования.
Повторная параметризация для вычисления градиентов
Существует функция повторной параметризации, которую мы не обсуждали, но она решает очень важную проблему в нашей сети вариационного автокодировщика. Напомним, что на этапе декодирования мы выбираем кодирование скрытого вектора из распределения, управляемого средним значением и вектором дисперсии, сгенерированным кодировщиком. Это не создает проблем при прямом распространении данных по нашей сети, но вызывает большую проблему при обратном распространении градиентов от декодера к кодировщику, поскольку операция выборки недифференцируема.
Проще говоря, мы не можем вычислить градиенты с помощью операции выборки.
Хороший способ решения этой проблемы - применить трюк с повторной параметризацией. Для этого сначала создается стандартное гауссовское распределение среднего 0 и дисперсии 1, а затем выполняется дифференцируемая операция сложения и умножения этого распределения со средним значением и дисперсией, сгенерированными кодировщиком.
Обратите внимание, что мы преобразуем дисперсию в логарифм в коде. Это необходимо для обеспечения числовой стабильности. Дополнительный член потерь, потеря дивергенции Кульбака-Лейблера, введен для обеспечения того, чтобы генерируемые нами распределения были как можно ближе к стандартному гауссовскому распределению со средним 0 и дисперсией 1, насколько это возможно.
Приведение средних значений распределений к нулю гарантирует, что генерируемые нами распределения очень близки друг к другу, чтобы избежать разрывов между распределениями. Разница, близкая к 1, означает, что у нас есть более умеренное (то есть не очень большое и не очень маленькое) пространство для генерации кодировок.
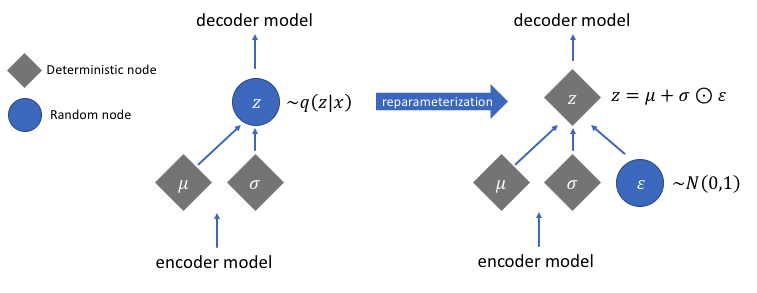
Изображение предоставлено Джереми Джорданом
После выполнения трюка с повторной параметризацией распределение, полученное путем умножения вектора дисперсии на стандартное распределение Гаусса и добавления результата к среднему вектору, очень похоже на распределение, которое непосредственно контролируется векторами среднего и дисперсии.
Простые шаги по созданию вариационного автокодировщика
Давайте завершим это руководство, суммируя шаги по созданию вариационного автоэнкодера:
- Создайте сети кодировщика и декодера.
- Примените трюк с изменением параметров между кодером и декодером, чтобы разрешить обратное распространение.
- Проведите сквозное обучение обеих сетей.
Полный код, использованный выше, можно найти на официальном сайте TensorFlow.
Рекомендуемое изображение изменено на основе Chiman Kwan
Промышленный робот
- Как 3D-принтеры создают металлические объекты
- Как уменьшить количество отходов с помощью автономных роботов
- Как защитить облачные технологии?
- Что мне делать с данными ?!
- Как Интернет вещей может помочь с большими данными HVAC:Часть 2
- Как сделать IOT реальным с помощью Tech Data и IBM Part 2
- Как сделать Интернет вещей реальным с помощью Tech Data и IBM Часть 1
- Как компании цепочки поставок могут строить дорожные карты с помощью ИИ
- Data Mining, AI:как промышленные бренды могут идти в ногу с электронной коммерцией
- Что такое срок службы инструмента? Как оптимизировать оснастку с помощью машинных данных