


2017 год - год голосового интерфейса?
За последние несколько лет значительный прогресс в области автоматического распознавания речи (ASR) привел к появлению множества устройств и приложений, использующих речь в качестве основного интерфейса. IEEE Spectrum журнал объявил 2017 год годом распознавания голоса; ZDNet сообщил с выставки CES 2017, что голос - это следующий компьютерный интерфейс; и многие другие придерживаются аналогичных взглядов. Итак, где мы находимся в отношении развития голосовых интерфейсов? В этой публикации будет рассмотрено текущее состояние голосовых интерфейсов и соответствующих технологий.
На скольких ваших устройствах с вами разговаривают?
Голосовая активация повсюду. Почти каждый смартфон имеет голосовой интерфейс, включая такие флагманы, как Apple iPhone 7 и Samsung Galaxy S7, включая функцию постоянного прослушивания. Большинство умных часов предлагают голосовую активацию, а также другие носимые, особенно наушники, такие как Apple AirPods и Samsung Gear IconX. В большинстве этих устройств нет удобного способа интеграции какого-либо другого интерфейса, что делает голосовую связь идеальным и необходимым решением. Новыми камерами, такими как GoPro Hero 5, можно управлять с помощью голосовых команд, что отлично подходит для селфи. Информационно-развлекательные системы с голосовой активацией стали обычным явлением, поэтому менять станцию во время вождения стало намного безопаснее.
Amazon Echo зажег тенденцию разговорного помощника, который горит, когда Google Home пытается конкурировать, и множество подобных клонов было продемонстрировано на выставке CES 2017. Голосовая служба Echo, названная Alexa, имеет несколько встроенных навыков. Например, вы можете сказать «Алекса, расскажи мне анекдот» (очень иронично), «Алекса, победили ли Воины?» (конечно, были), или «Алекса, которая снялась в фильме 2001:Космическая одиссея?» (кажется, больше никто не знает). Также есть куча забавных пасхальных яиц, таких как ответ, когда вы говорите «Алекса, инициируйте последовательность самоуничтожения». (см. также это видео, демонстрирующее некоторые пасхальные яйца Алексы).
Помимо встроенных функций, новые возможности могут быть добавлены в Alexa третьими сторонами с помощью Alexa Skills Kit (ASK). Этот ASK позволяет разработчикам обучать Alexa новым навыкам, чтобы она (или она?) Могла контролировать больше продуктов и услуг и взаимодействовать с ними. Как вы можете видеть в этом видео, например, один человек взломал свой iRobot Roomba и добавил навык для управления роботом-пылесосом.
Другие навыки Alexa включают в себя полезные вещи, такие как заказ еды из различных закусочных или вызов Uber, и случайные развлечения, такие как задание волшебных вопросов с восьмерками, мелочи по Сайнфелду и изучение новых фактов о фруктах. Сотрудничество между Amazon и такими компаниями, как Whirlpool и GE, также укрепит возможности Alexa в умном доме, добавив возможности для управления бытовой техникой, такой как стиральные машины, холодильники, лампы и многое другое.
В настоящее время Amazon, кажется, лидирует на этом рынке, но другие прилагают огромные усилия (и инвестиции), чтобы наверстать упущенное. Марк Цукерберг нанял Моргана Фримена озвучивать его голосового помощника с искусственным интеллектом (ИИ). Согласно записке с описанием того, как он это построил, Цукерберг потратил год на разработку приложения как простого ИИ, чтобы помочь ему управлять своим домом «как Джарвис в Железном человеке» (он тоже назвал его Джарвисом). Джарвис якобы идентифицирует говорящего по его голосу, а также распознает лица, чтобы позволить авторизованным людям войти в дверь, отчитываясь перед Цукербергом.
Еще один интересный соперник - японское устройство, похожее на Amazon-Echo, под названием Gatebox, на котором изображен голографический персонаж по имени Адзума Хикари.

Ответ Японии на Amazon Echo (Источник:Gatebox)
Помимо простого динамика, устройство использует экран и проектор для визуального и звукового оживления виртуального помощника. Помимо микрофонов, в нем также есть камеры, датчики движения и температуры, которые позволяют ему более комплексно взаимодействовать с пользователем.
Как работает прием голоса в дальней зоне?
Как устройство слушает и понимает ваши голосовые команды во время воспроизведения музыки в другом конце комнаты? Есть много компонентов, задействованных в реализации этого умения, но некоторые из них имеют первостепенное значение. Во-первых, это механизм автоматического распознавания речи (ASR), который позволяет машинам преобразовывать издаваемые нами звуки в исполняемые инструкции. Чтобы механизм ASR работал правильно, он должен получать чистый голосовой образец. Это требует уменьшения шума и эхоподавления, чтобы отфильтровать помехи. Ниже приведены некоторые из наиболее важных технологий, обеспечивающих улавливание голоса в дальней зоне:
Глубокое обучение играет в этом огромную роль. Способность понимать естественный язык была установлена несколько лет назад, но недавние усовершенствования приблизили ее к человеческому уровню. Используя методы, основанные на обучении, такие как глубокие нейронные сети (DNN), как языковая обработка, так и распознавание визуальных объектов во многих тестовых случаях сравнялись или превзошли человеческую производительность. DNN генерируются с использованием массивных наборов данных на этапе обучения. После того, как обучение было проведено в автономном режиме, DNN используются для выполнения своих функций в режиме реального времени.
Адаптивное формирование луча является ключевым элементом надежного голосового пользовательского интерфейса. Он включает такие функции, как шумоподавление, отслеживание выступающих в случае, если пользователь движется во время разговора, и разделение динамиков, когда несколько пользователей говорят одновременно.
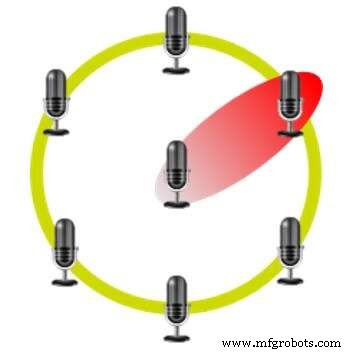
Формирование луча с помощью гексагональной микрофонной решетки (Источник:CEVA)
Этот метод использует несколько микрофонов в фиксированных положениях относительно друг друга. Например, Amazon Echo использует семь микрофонов в шестиугольной компоновке с одним микрофоном в каждой вершине и одним в центре. Временная задержка между приемом сигнала различными микрофонами позволяет устройству определять, откуда идет голос, и подавлять звуки, исходящие с других направлений.
Подавление акустического эха необходимо, потому что многие продукты, выполняющие автоматическое распознавание речи, также сами издают звуки; например, воспроизведение музыки или передача информации. Даже при выполнении этих действий устройства должны иметь возможность слышать, чтобы пользователь мог прервать (вмешаться) и остановить музыку или запросить другое действие. Чтобы продолжить прослушивание, устройство должно иметь возможность гасить звук, который он генерирует сам. Это называется акустическим эхоподавлением (AEC).
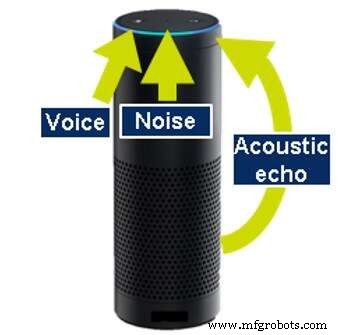
Подавление акустического эха (Источник:CEVA)
Для выполнения AEC устройство должно осознавать издаваемый звук, либо путем анализа выходных данных, либо путем прослушивания генерируемых звуков с помощью дополнительного выделенного микрофона. Аналогичная технология также применяется для удаления эхо, отражающегося от стен и других объектов вокруг устройства.

Платформа разработки с несколькими микрофонами для моделирования DNN, формирования луча и алгоритмов эхоподавления (Источник:CEVA)
Другой тип эха генерируется самими командами пользователя, когда они отражаются от объектов или от стен. Для подавления таких непредсказуемых эхо-сигналов требуется еще один алгоритм, называемый дереверберацией. Затем звук фильтруется, и машина может прислушиваться к командам от пользователя.
Сегодняшние голосовые интерфейсы далеки от совершенства
С одной стороны, 2017 год выглядит знаменательным для голосовых интерфейсов, учитывая, насколько широко они получили распространение. С другой стороны, даже с учетом всех впечатляющих достижений последних нескольких лет, предстоит еще долгий путь.
Остается много проблем с текущими реализациями голосовых интерфейсов в устройствах массового производства, но это будет темой для будущей статьи. В моем следующем посте я планирую рассмотреть некоторые недостатки и недостающие функции, которые характерны для сегодняшних голосовых интерфейсов. Обязательно настройтесь.
Эран Белаиш является менеджером по маркетингу продуктов линейки аудио и голосовых продуктов CEVA, разрабатывая изысканные решения, начиная от голосового запуска и мобильной голосовой связи и заканчивая беспроводным аудио и домашним аудио высокого разрешения. Хотя Эран не занят увлекательным миром иммерсивного звука, он любит погружаться в завораживающую тишину подводного мира.
Встроенный
- Генеральный директор Monroe Engineering - финалист конкурса EY «Предприниматель года»
- Интерфейс командной строки
- MajorTom:ARDrone 2.0 с голосовым управлением Alexa
- Motion назван поставщиком года
- Mobius получает награду "Продукт года"
- 2020 год станет годом непрерывного интеллекта
- Тренды CMMS 2019:Год клиента
- Монро выиграла премию «Бизнес года 2019»!
- Большое кулинарное шоу с чили в Висконсине
- Единый голос производителей сжатого воздуха