


Отчет ETSI открывает путь для стандартизации безопасности AI
Новый отчет ETSI, европейской организации по стандартизации сетей и услуг электросвязи, радиовещания и электронных коммуникаций, направлен на то, чтобы проложить путь к установлению стандарта безопасности искусственного интеллекта (ИИ).
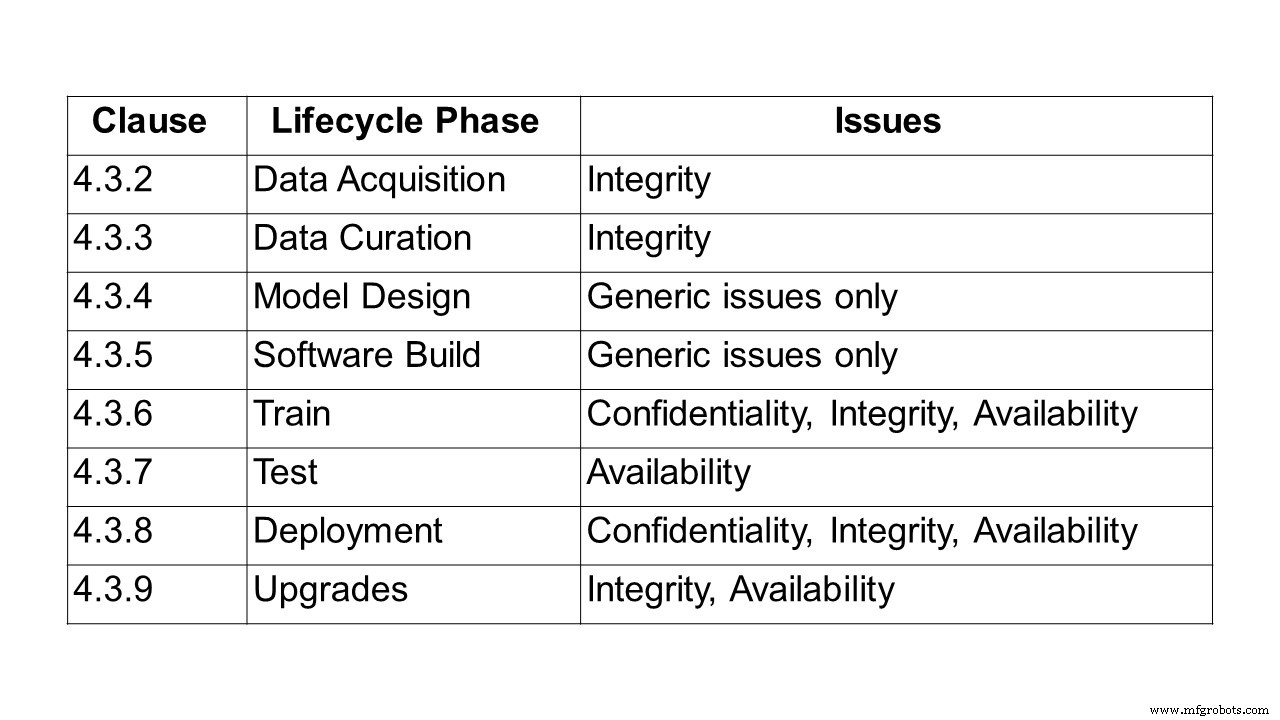
Первым шагом на пути к созданию стандарта является описание проблемы защиты систем и решений на основе ИИ. Это то, что делает 24-страничный отчет ETSI GR SAI 004, первый опубликованный Группой спецификаций индустрии искусственного интеллекта ETSI (SAI ISG). Он определяет формулировку проблемы и уделяет особое внимание машинному обучению (ML) и проблемам, связанным с конфиденциальностью, целостностью и доступностью на каждом этапе жизненного цикла машинного обучения. Он также указывает на некоторые из более широких проблем систем искусственного интеллекта, включая предвзятость, этичность и способность объяснять. Обрисован ряд различных векторов атак, а также несколько случаев реального использования и атак.
Чтобы определить проблемы, связанные с защитой ИИ, первым шагом было определение ИИ. Для группы ETSI искусственный интеллект - это способность системы обрабатывать представления, как явные, так и неявные, и процедуры для выполнения задач, которые считались бы интеллектуальными, если бы их выполнял человек. Это определение по-прежнему представляет собой широкий спектр возможностей. Однако сейчас становится возможным ограниченный набор технологий, в значительной степени обусловленный развитием машинного обучения и методов глубокого обучения, а также широкой доступностью данных и вычислительной мощности, необходимых для обучения и внедрения таких технологий.
Широко используются многочисленные подходы к машинному обучению, включая контролируемое, неконтролируемое, частично контролируемое обучение и обучение с подкреплением.
- Контролируемое обучение - все данные обучения помечены, и модель может быть обучена предсказывать выходные данные на основе нового набора входных данных.
- Полу-контролируемое обучение - набор данных частично помечен. В этом случае для улучшения качества модели можно использовать даже немаркированные данные.
- Обучение без учителя - когда набор данных не помечен, а модель ищет структуру в данных, включая группировку и кластеризацию.
- Обучение с подкреплением - когда политика, определяющая, как действовать, изучается агентами на собственном опыте, чтобы максимизировать свое вознаграждение; агенты получают опыт, взаимодействуя с окружающей средой посредством смены состояний.
В рамках этих парадигм могут использоваться различные модельные структуры, при этом одним из наиболее распространенных подходов является использование глубоких нейронных сетей, где обучение осуществляется на нескольких иерархических уровнях, имитирующих поведение человеческого мозга.
Также можно использовать различные методы обучения, а именно состязательное обучение, при котором обучающий набор содержит не только образцы, отражающие желаемые результаты, но также образцы состязательности, которые предназначены для того, чтобы бросить вызов или нарушить ожидаемое поведение.
«Об этике ИИ ведется много дискуссий, но ни одной дискуссии о стандартах защиты ИИ нет. Тем не менее, они становятся критически важными для обеспечения безопасности автоматизированных сетей на основе ИИ. Этот первый отчет ETSI призван дать исчерпывающее определение проблем, с которыми сталкиваются при обеспечении безопасности ИИ. Параллельно мы работаем над онтологией угроз, над тем, как защитить цепочку поставки данных ИИ и как ее протестировать », - объясняет Алекс Ледбитер, председатель ETSI SAI ISG.
Отвечая на вопрос о сроках, Ледбитер ответил embedded.com:«Еще 12 месяцев - разумная оценка технических характеристик. В ближайшие пару кварталов появятся новые технические отчеты (AI Threat Ontology, Data Supply Chain Report, SAI Mitigation Strategy). Фактически, одна спецификация по тестированию безопасности ИИ должна быть выпущена раньше, примерно в конце второго / третьего квартала. Следующими шагами будет определение конкретных областей в формулировке проблемы, которые могут быть расширены до более подробных информативных рабочих элементов ».
Схема отчета
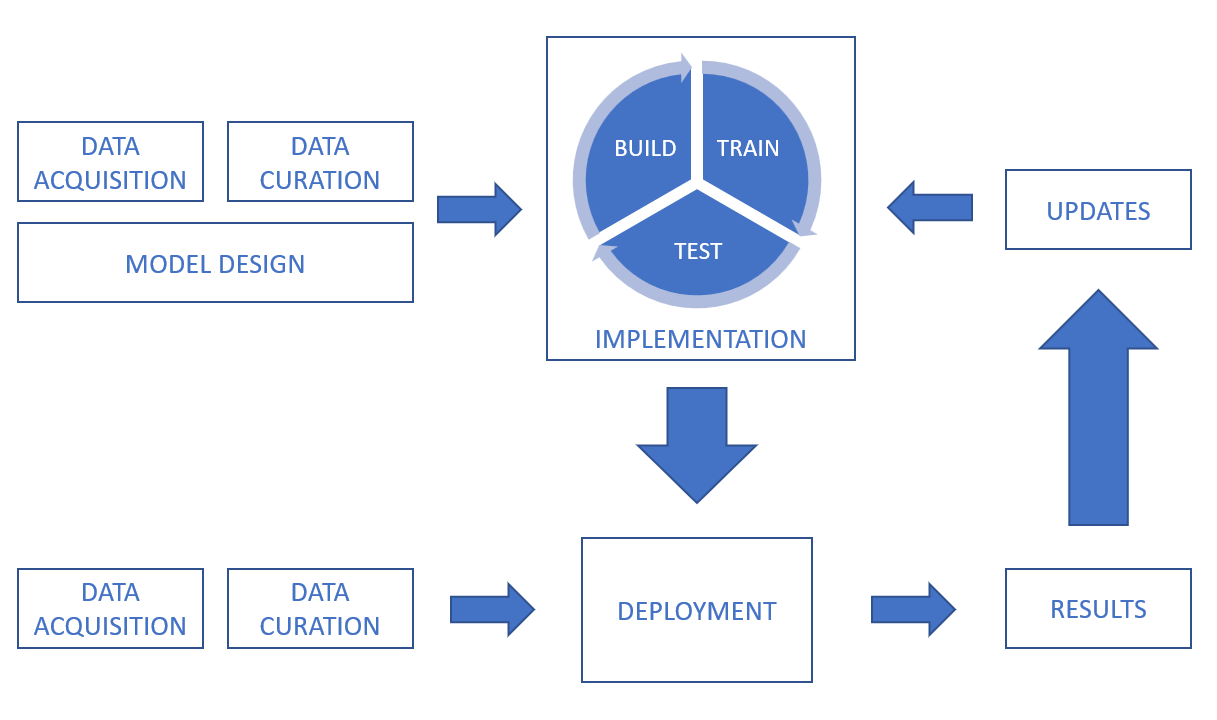
Следуя определению ИИ и машинного обучения, в отчете затем рассматривается цепочка обработки данных, охватывающая проблемы конфиденциальности, целостности и доступности на протяжении всего жизненного цикла, от сбора данных, обработки данных, проектирования модели и создания программного обеспечения до обучения, тестирования, развертывания и вывод и обновления.
В системе ИИ данные могут быть получены из множества источников, включая датчики (например, камеры видеонаблюдения, мобильные телефоны, медицинские устройства) и цифровые активы (например, данные с торговых платформ, выдержки из документов, файлы журналов). Данные также могут быть во многих различных формах (включая текст, изображения, видео и аудио) и могут быть структурированными или неструктурированными. Помимо проблем безопасности, связанных с самими данными, важно учитывать безопасность передачи и хранения.
Чтобы указать на проблемы целостности при курировании данных, при исправлении, расширении или преобразовании наборов данных важно гарантировать, что процессы не рискуют повлиять на качество и целостность данных. Для контролируемых систем машинного обучения важно, чтобы маркировка данных была точной и максимально полной, а также чтобы маркировка сохраняла свою целостность и не подвергалась риску, например, в результате атак с отравлением. Также важно решить проблему обеспечения объективности набора данных. Методы увеличения данных могут повлиять на целостность данных.
Другая рассматриваемая область связана с проблемами дизайна и другими непреднамеренными факторами, связанными с предвзятостью, этичностью данных и объяснимостью.
Например, предвзятость следует учитывать не только на этапах проектирования и обучения, но и после развертывания системы, поскольку предвзятость все еще может быть внесена. В отчете приводится пример из 2016 года, когда был запущен чат-бот, который задумывался как эксперимент «разговорного понимания». Чат-бот будет взаимодействовать с пользователями социальных сетей посредством твитов и прямых сообщений. Через несколько часов чат-бот начал твитнуть крайне оскорбительные сообщения. После того, как чат-бот был удален, было обнаружено, что его учетная запись была изменена для демонстрации предвзятого поведения интернет-троллей. Предвзятость не обязательно представляет собой проблему безопасности, но может просто привести к тому, что система не выполнит свои функциональные требования.
Что касается этики, в отчете приводится несколько примеров, в том числе автономные автомобили и здравоохранение. Он цитирует документ из Брайтонского университета, в котором обсуждается гипотетический сценарий, когда автомобиль, управляемый искусственным интеллектом, сбивает пешехода, и исследуются связанные с этим юридические обязательства. В марте 2018 года этот сценарий стал реальностью, когда беспилотный автомобиль сбил пешехода в городе Темпе, штат Аризона. Это привлекло внимание не только к юридической ответственности, но и к потенциальным этическим проблемам самого процесса принятия решений. В 2016 году Массачусетский технологический институт (MIT) запустил веб-сайт под названием Moral Machine, посвященный проблемам, связанным с разрешением интеллектуальным системам принимать решения этического характера. Сайт пытается изучить, как люди ведут себя, сталкиваясь с этическими дилеммами, и лучше понять, как должны себя вести машины.
В отчете подчеркивается, что, хотя этические соображения не имеют прямого отношения к традиционным характеристикам безопасности, таким как конфиденциальность, целостность и доступность, они могут существенно повлиять на представление человека о том, можно ли доверять системе. Поэтому важно, чтобы разработчики и разработчики систем искусственного интеллекта учитывали этические проблемы и стремились создать надежные этические системы, которые могут укрепить доверие среди пользователей.
Наконец, в отчете рассматриваются типы атак, от отравления и бэкдор-атак до обратного проектирования, а также реальные варианты использования и атаки.
При атаке с отравлением злоумышленник стремится скомпрометировать модель ИИ, обычно на этапе обучения, чтобы развернутая модель вела себя так, как этого хочет злоумышленник. Это может происходить из-за того, что модель не работает из-за определенных задач или входных данных, или из-за того, что модель изучает набор действий, которые желательны для злоумышленника, но не предусмотрены разработчиком модели. Атаки отравления обычно могут происходить тремя способами:
- Отравление данных - когда злоумышленник вводит неверные или неправильно помеченные данные в набор данных на этапах сбора или курирования данных.
- Отравление алгоритма - когда злоумышленник вмешивается в алгоритмы, используемые в процессе обучения. Например, федеративное обучение включает обучение отдельных моделей на подмножествах данных, а затем объединение изученных моделей вместе для формирования окончательной модели. Это означает, что отдельные наборы данных остаются конфиденциальными, но создают внутреннюю уязвимость. Поскольку злоумышленник может контролировать любой отдельный набор данных, он может напрямую манипулировать этой частью модели обучения и влиять на общее обучение системы.
- Отравление модели - когда вся развернутая модель просто заменяется альтернативной моделью. Этот тип атаки аналогичен традиционной кибератаке, когда электронные файлы, составляющие модель, могут быть изменены или заменены.
Хотя термин «искусственный интеллект» возник на конференции в 1950-х годах в Дартмутском колледже в Ганновере, штат Нью-Гэмпшир, США, случаи его использования в реальной жизни, описанные в отчете ETSI, показывают, насколько он изменился с тех пор. К таким случаям относятся атаки блокировщиков рекламы, обфускация вредоносных программ, дипфейки, воспроизведение почерка, человеческий голос и фальшивые разговоры (которые уже вызвали много комментариев с чат-ботами).
Что дальше? Текущие отчеты в рамках этой ISG
Эта группа отраслевых спецификаций (ISG) изучает несколько текущих отчетов как часть рабочих элементов, которые она рассмотрит глубже.
Тестирование безопасности :Цель этого рабочего элемента - определить цели, методы и приемы, которые подходят для тестирования безопасности компонентов на основе ИИ. Общая цель состоит в том, чтобы разработать руководящие принципы для тестирования безопасности ИИ и компонентов на основе ИИ с учетом различных алгоритмов символического и субсимвольного ИИ и устранения соответствующих угроз из рабочего элемента «Онтология угроз ИИ». Тестирование безопасности ИИ имеет некоторые общие черты с тестированием безопасности традиционных систем, но создает новые проблемы и требует разных подходов из-за
(а) существенные различия между символическим и подсимволическим ИИ и традиционными системами, которые имеют сильное влияние на их безопасность и на то, как тестировать их свойства безопасности;
(б) недетерминизм, поскольку системы на основе ИИ могут со временем развиваться (самообучающиеся системы), а свойства безопасности могут ухудшаться;
(c) тестовая задача оракула, назначение тестового вердикта является другим и более сложным для систем на основе AI, поскольку не все ожидаемые результаты известны априори, и (d) алгоритмы, управляемые данными:в отличие от традиционных систем, (обучающие) данные формирует поведение субсимволического ИИ.
Объем этого рабочего элемента по тестированию безопасности состоит в том, чтобы охватить следующие темы (но не ограничиваясь ими):
- подходы к тестированию безопасности для ИИ
- данные тестирования ИИ с точки зрения безопасности
- оракулы тестирования безопасности для ИИ
- определение критериев адекватности тестирования для тестирования безопасности ИИ
- цели тестирования атрибутов безопасности ИИ
И в нем представлены рекомендации по тестированию безопасности ИИ с учетом вышеупомянутых тем. В руководстве будут использоваться результаты рабочего элемента «Онтология угроз ИИ», чтобы охватить соответствующие угрозы для ИИ посредством тестирования безопасности, а также будут рассмотрены проблемы и ограничения при тестировании системы на основе ИИ.
Онтология угроз ИИ :Цель этого рабочего элемента - определить, что будет считаться угрозой искусственного интеллекта и чем она может отличаться от угроз для традиционных систем. Отправной точкой, которая предлагает обоснование этой работы, является то, что в настоящее время нет единого понимания того, что представляет собой атака на ИИ и как она может быть создана, размещена и распространена. Результатом рабочего элемента «Онтология угроз ИИ» будет приведение терминологии в соответствие с различными заинтересованными сторонами и различными отраслями. В этом документе будет определено, что подразумевается под этими терминами в контексте кибернетической и физической безопасности, и будет сопровождаться сопроводительное описание, которое должно быть легко доступно как экспертам, так и менее информированной аудитории во многих отраслях. Обратите внимание, что в этой онтологии угроз ИИ будет рассматриваться как система, злоумышленник и как защитник системы.
Отчет о цепочке поставок данных :Данные - важный компонент в разработке систем искусственного интеллекта. Это включает необработанные данные, а также информацию и обратную связь от других систем и людей в цикле, все из которых можно использовать для изменения функции системы путем обучения и переподготовки ИИ. Однако доступ к подходящим данным часто ограничен, что приводит к необходимости прибегать к менее подходящим источникам данных. Было продемонстрировано, что нарушение целостности обучающих данных является жизнеспособным вектором атаки на систему ИИ. Это означает, что обеспечение безопасности цепочки поставок данных является важным шагом в обеспечении безопасности ИИ. В этом отчете будут обобщены методы, используемые в настоящее время для получения данных для обучения ИИ, а также правила, стандарты и протоколы, которые могут контролировать обработку и обмен этими данными. Затем он предоставит анализ пробелов в этой информации для определения возможных требований к стандартам для обеспечения прослеживаемости и целостности данных, связанных атрибутов, информации и обратной связи, а также их конфиденциальности.
Стратегия снижения риска SAI Отчет:этот рабочий элемент направлен на обобщение и анализ существующих и потенциальных мер по снижению угроз для систем на основе ИИ. Цель состоит в том, чтобы разработать рекомендации по снижению угроз, возникающих в результате внедрения ИИ в системы. Эти руководящие принципы прольют свет на основы обеспечения безопасности систем на основе ИИ путем устранения известных или потенциальных угроз безопасности. Они также учитывают возможности, проблемы и ограничения безопасности при принятии мер по снижению рисков для систем на основе ИИ в определенных потенциальных сценариях использования.
? Роль оборудования в безопасности ИИ: Подготовить отчет, определяющий роль оборудования, как специализированного, так и общего назначения, в обеспечении безопасности ИИ. Это позволит решить проблемы, доступные в оборудовании для предотвращения атак, а также удовлетворить общие требования к оборудованию для поддержки SAI. Кроме того, в этом отчете будут рассмотрены возможные стратегии использования ИИ для защиты оборудования. В отчете также будет представлена сводка академического и промышленного опыта в области аппаратной безопасности для ИИ. Кроме того, в отчете будут рассмотрены уязвимости и недостатки оборудования, которые могут усилить векторы атак на ИИ.
Полный отчет ETSI, определяющий постановку проблемы для защиты ИИ, доступен здесь.
Интернет вещей
- Советы и тенденции безопасности IIoT на 2020 год
- Рецепт промышленной безопасности:немного ИТ, щепотка ОТ и немного SOC
- Поиск универсального стандарта безопасности IoT
- TI:резонаторная технология BAW прокладывает путь для коммуникаций следующего поколения
- Руководство по кибербезопасности, выпущенное для бизнес-пользователей облачных сред
- Сообщите о призывах к немедленным действиям для устранения киберугроз для критически важной инфраструктуры
- Три шага для глобальной безопасности Интернета вещей
- Четырехэтапное руководство по обеспечению безопасности для Iot-устройств
- Что означает появление 5G для безопасности Интернета вещей
- Штрафные санкции FTC "Сделано в США" открывают путь к дополнительному правоприменению