


Использование FPGA для глубокого обучения
Недавно я посетил Форум разработчиков Xilinx (XDF) 2018 в Кремниевой долине. На этом форуме я познакомился с компанией Mipsology, стартапом в области искусственного интеллекта (AI), который утверждает, что решил проблемы, связанные с AI, связанные с программируемыми вентильными матрицами (FPGA). Компания Mipsology была основана с большой мечтой ускорить вычисление любой нейронной сети (NN) с максимальной производительностью, достижимой на FPGA, без ограничений, присущих их развертыванию.
Mipsology продемонстрировала способность выполнять более 20 000 изображений в секунду, работая на недавно анонсированных платах Alveo от Xilinx и обрабатывая набор сетевых сетей, включая ResNet50, InceptionV3, VGG19 и другие.
Представляем нейронные сети и глубокое обучение
Нейронная сеть, смоделированная на основе сети нейронов человеческого мозга, лежит в основе глубокого обучения (DL), сложной математической системы, которая может самостоятельно изучать задачи. Изучая множество примеров или ассоциаций, сеть может узнать связи и отношения быстрее, чем в традиционной программе распознавания. Процесс настройки NN для выполнения определенной задачи на основе обучения миллионы образцов одного и того же типа называется обучением . .
Например, NN может слушать много вокальных образцов и использовать DL, чтобы научиться «распознавать» звуки определенных слов. Затем этот NN мог бы просмотреть список новых голосовых образцов и правильно идентифицировать образцы, содержащие слова, которые он выучил, используя метод, называемый выводом .
Несмотря на свою сложность, DL основан на выполнении простых операций - в основном сложения и умножения - в миллиардах или триллионах. Требование вычислений для выполнения таких операций устрашает. Более конкретно, вычислительные потребности для выполнения логических выводов DL больше, чем для обучения DL. В то время как обучение DL должно выполняться только один раз, NN, однажды обученный, должен выполнять логический вывод снова и снова для каждой новой полученной выборки.
Четыре варианта ускорения вывода глубокого обучения
Со временем инженерное сообщество обратилось к четырем различным вычислительным устройствам для обработки NN. В порядке увеличения вычислительной мощности и энергопотребления и в порядке убывания гибкости / адаптируемости эти устройства включают в себя:центральные процессоры (ЦП), графические процессоры (ГП), ПЛИС и интегральные схемы для конкретных приложений (ASIC). В таблице ниже приведены основные различия между четырьмя вычислительными устройствами.
<центр> 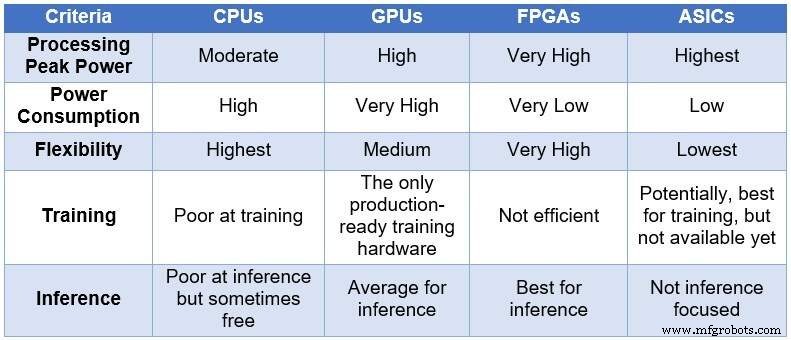
Сравнение процессоров, графических процессоров, FPGA и ASIC для вычислений DL (Источник:Лауро Риццатти)
Процессоры основаны на архитектуре фон Неймана. Несмотря на гибкость (причина их существования), ЦП подвержены длительной задержке из-за того, что доступ к памяти требует нескольких тактовых циклов для выполнения простой задачи. Применительно к задачам, которые выигрывают от наименьших задержек, таких как вычисление NN и, в частности, обучение и логический вывод DL, они являются наихудшим выбором.
Графические процессоры обеспечивают высокую производительность вычислений за счет снижения гибкости. Кроме того, графические процессоры потребляют значительную мощность, требующую охлаждения, что делает их менее идеальными для развертывания в центрах обработки данных.
Хотя кастомные ASIC могут показаться идеальным решением, у них есть свой набор проблем. На разработку ASIC уходят годы. DL и NN быстро развиваются благодаря постоянным достижениям, в результате чего технологии прошлого года неуместны. Кроме того, чтобы конкурировать с ЦП или ГП, ASIC потребуется использовать большую площадь кремния с использованием технологии самого тонкого технологического узла. Это делает предварительные вложения дорогими без каких-либо гарантий долгосрочной актуальности. В целом, ASIC эффективны для решения конкретных задач.
Устройства FPGA оказались лучшим выбором для вывода. Они быстрые, гибкие, энергоэффективные и предлагают хорошее решение для обработки данных в центрах обработки данных, особенно в быстро меняющемся мире DL, на границе сети и под столом ученых, занимающихся искусственным интеллектом.
Самые большие доступные сегодня ПЛИС включают в себя миллионы простых логических операторов, тысячи памяти и DSP, а также несколько ядер процессора ARM. Все эти ресурсы работают параллельно - каждый такт часов запускает до миллионов одновременных операций, что приводит к триллионам операций, выполняемых каждую секунду. Обработка, требуемая DL, довольно хорошо отображается на ресурсы FPGA.
ПЛИС имеют и другие преимущества перед процессорами и графическими процессорами, используемыми для DL, в том числе следующие:
-
Они не ограничиваются определенными типами данных. Они могут обрабатывать нестандартную низкую точность, более подходящую для обеспечения более высокой пропускной способности для DL.
-
Они потребляют меньше энергии, чем процессоры или графические процессоры - обычно в 5-10 раз меньше средней мощности для тех же вычислений NN. Их текущие расходы в центрах обработки данных ниже.
-
Их можно перепрограммировать, чтобы они соответствовали любой задаче, но они должны быть достаточно общими для выполнения различных задач. DL быстро развивается, и та же самая FPGA будет соответствовать новым требованиям без необходимости использования микросхемы следующего поколения (что типично для ASIC), тем самым снижая стоимость владения.
-
Они варьируются от больших до маленьких устройств. Их можно использовать в центрах обработки данных или в узле Интернета вещей (IoT). Единственная разница - количество содержащихся в них блоков.
Не все то золото, что блестит
Высокая вычислительная мощность, низкое энергопотребление и гибкость FPGA имеют свою цену - сложность программирования.
Интернет вещей
- CEVA:AI-процессор второго поколения для глубоких рабочих нагрузок нейронных сетей
- Обоснование использования нейроморфных чипов для вычислений ИИ
- ICP:карта ускорителя на основе FPGA для вывода глубокого обучения
- Аутсорсинг ИИ и глубокое обучение в сфере здравоохранения - существует ли угроза для конфиденциальности данн…
- Как высокотехнологичная отрасль использует ИИ для экспоненциального роста бизнеса
- Искусственный интеллект против машинного обучения против глубокого обучения | Разница
- Команда Apple и IBM Watson для корпоративного мобильного машинного обучения
- Глубокое обучение и его многочисленные приложения
- Решение по стабильности инструмента для глубокого сверления
- Как глубокое обучение автоматизирует контроль в медико-биологической отрасли