


Решение проблем многоядерного программирования и отладки
В этой статье мы обсудим различные аспекты многоядерной обработки, в том числе рассмотрим различные типы многоядерных процессоров и то, почему эти устройства становятся сегодня распространенными и популярными. Затем мы рассмотрим некоторые проблемы, возникающие при наличии более одного ядра на кристалле, и то, как современные многоядерные отладчики могут помочь сделать эти сложные задачи более управляемыми.
Производительность системы
Есть много способов повысить производительность встроенной вычислительной системы, от умных алгоритмов компилятора до эффективных аппаратных решений. Оптимизация компилятора важна для наиболее эффективного планирования инструкций из кода языка высокого уровня, который легко читать и понимать. В дополнение к этому, системы могут использовать параллелизм, доступный в проекте, для одновременной обработки нескольких задач. И, конечно же, масштабирование тактовой частоты может быть эффективным способом повышения производительности вашей вычислительной системы.
К сожалению, времена, когда можно было предположить, что тактовая частота увеличивается геометрически, прошли. А оптимизация кода может принести только некоторые улучшения, особенно сейчас, после многих поколений разработки технологии компиляторов. Это заставляет нас смотреть на параллелизм как на лучшую возможность продолжить масштабирование производительности нашей системы с течением времени.
Параллелизм

Копание колодца - задача, которую сложно распараллелить. Другие могут помочь, сгребая землю лопатой, но на самом деле копание ямы обычно выполняется одним человеком. В результате, добавление большего количества людей в яму не ускорит выполнение работы. Фактически, другие могут просто мешать и замедлять процесс. Некоторые задачи не подходят для распараллеливания.
Остальные задачи легко распараллелить. Копание канавы - задача, подходящая для распараллеливания. Многие люди могут работать бок о бок.

На этом рисунке показана форма параллелизма под названием MIMD, Multiple Instruction Multiple Data. Каждый экскаватор представляет собой отдельную единицу и может выполнять разные задачи. В этом случае вы можете представить, что четыре экскаватора могут выполнить свою работу примерно за 1/4 th время одиночного землекопа.
С SIMD, одной инструкцией и несколькими данными, один экскаватор может использовать лопату, подобную этой.
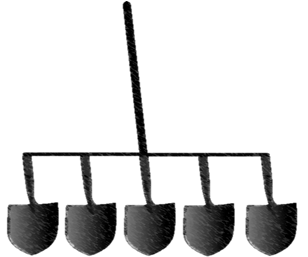
Модуль SIMD может одновременно выполнять только один тип вычислений, но он может выполнять их параллельно с несколькими частями данных. Эти типы инструкций распространены в блоках векторной обработки многих процессоров. Это полезно, если ваши данные очень регулярны и вам нужно снова и снова выполнять одни и те же операции с большим набором данных, например, при обработке изображений. Однако для более общих вычислительных задач этой модели не хватает гибкости, и она не даст прироста производительности.
Это приводит нас к решению разместить несколько полных подсистем ЦП на одном кристалле, создавая многоядерные процессоры. Использование нескольких ядер на одном кристалле позволяет масштабировать производительность. Каждое ядро представляет собой полноценный ЦП и может работать независимо или совместно с другими ядрами.
Различные типы многоядерной обработки
Существуют различные комбинации типов ядер, которые могут быть в микросхеме процессора, а также то, как между ними распределяется работа.
Однородные многоядерные процессоры имеют две или более копий одного и того же процессорного ядра. Каждое ядро работает автономно и может связываться и синхронизироваться с другими ядрами с помощью ряда механизмов, таких как общая память или системы почтовых ящиков. Каждый процессор имеет свои собственные регистры и функциональные блоки и может иметь собственную локальную память или кэш. Однако то, что делает это однородным, - это тот факт, что все рассматриваемые нами ядра относятся к одному типу.
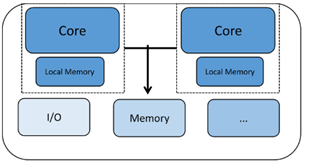
Другой тип многоядерного чипа называется гетерогенным многоядерным процессором с двумя или более ядрами ЦП разных типов. Здесь ядра могут иметь очень разные характеристики, что делает их подходящими для различных частей системной обработки. Одним из примеров может быть микросхема связи Bluetooth, в которой одно ядро предназначено для управления стеком протоколов Bluetooth, в то время как другое ядро может управлять внешней связью, обработкой приложений, человеческим интерфейсом и т. Д. Этот вид многоядерной микросхемы может использоваться для приложений, которым необходимы оба выделенная производительность в реальном времени на одном ядре и возможности управления системой на другом.
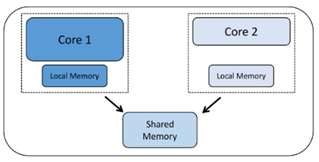
Теперь посмотрим, как используются ядра. Симметричная многопроцессорная обработка (SMP) происходит, когда у вас более одного ядра, и ядра работают с одной и той же кодовой базой проекта. На разных ядрах могут одновременно выполняться разные части кода, но код создается как единый проект и отправляется в отдельные ядра некоторой управляющей программой, такой как операционная система реального времени (RTOS). По необходимости ядра, работающие таким образом, должны быть одного типа, поскольку все они используют один и тот же код проекта, скомпилированный для одного типа процессора.
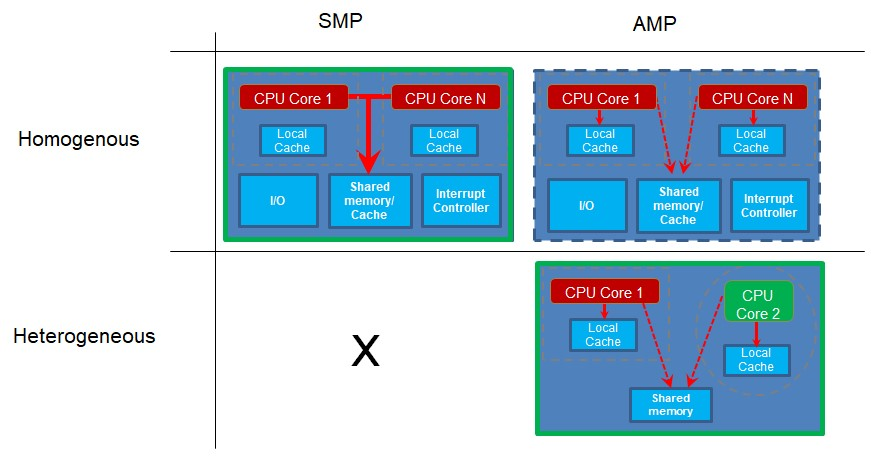
Асимметричная многопроцессорная обработка (AMP) происходит, когда у вас более одного ядра или процессора, и каждый процессор запускает собственное приложение проекта. Отдельные ядра могут время от времени синхронизироваться или обмениваться данными, но у каждого из них есть собственная кодовая база, которую они выполняют. Поскольку каждый из них выполняет свой собственный проект, эти ядра могут быть разных типов или разнородными. Однако это не является обязательным требованием. Если два или более ядер одного типа запускают разный код проекта, они являются однородными ядрами, на которых работает AMP.
Обратите внимание, что для работы SMP у вас должно быть несколько однородных ядер, поскольку все они запускают код из одной и той же базы кода проекта. Однако, если у вас есть несколько проектов с разными базами кода для запуска разных ядер, это могут быть разные ядра, например, в гетерогенной системе. Однако, если ядра одинаковые, это тоже работает.
Причины использования многоядерности
За последние несколько лет закон Мура, введенный в обращение в середине 1960-х годов, наконец, похоже, выдыхается или, по крайней мере, замедляется. Тактовая частота процессора больше не удваивается каждые 2–3 года, и на самом деле процессоры с самой высокой скоростью уже много лет достигают потолка в диапазоне низких однозначных чисел ГГц.
Один из способов продолжить расширять диапазон производительности - увеличить количество ядер ЦП, работающих вместе, если вы можете использовать их эффективно.
В то время как скорости стабилизировались, размер транзистора продолжал уменьшаться. Небольшие транзисторы, хотя и медленнее, чем раньше, позволяют разместить больше логики на одном кристалле. В результате использование этих транзисторов для размещения нескольких ядер ЦП на одной микросхеме позволяет использовать преимущества гораздо более быстрых и широких шинных соединений между несколькими подсистемами ЦП и памяти.
Гетерогенная асимметричная многопроцессорная обработка очень полезна, когда приложение имеет две или более рабочих нагрузок, которые имеют очень разные характеристики и требования. Один может зависеть от режима реального времени и задержки прерывания, а другой может больше зависеть от пропускной способности, чем от времени ответа. Эта модель работает очень хорошо:например, устройство может выделить одно ядро для управления стеком протоколов связи, таким как Bluetooth или Zigbee, в то время как другое ядро действует как процессор приложений, выполняющий взаимодействие с человеком и общие операции управления системой. Коммуникационный процессор, будучи изолированным, может обеспечить отличный отклик в реальном времени, необходимый стеку протоколов. Кроме того, коммуникационное программное обеспечение может быть сертифицировано по стандарту, что упрощает сертификацию всего продукта за счет сохранения функциональных модификаций отдельно от этой части системы.
Проблемы с использованием многоядерных процессоров
Какие проблемы возникают, когда на чип помещается более одного ядра ЦП? Что ж, давай разберемся.
Монолитное приложение или программное обеспечение может быть не в состоянии эффективно использовать доступные вычислительные ресурсы. Вам необходимо организовать приложение в параллельные задачи, которые могут выполняться одновременно, чтобы использовать ресурсы более чем одного ядра. Это может потребовать от разработчиков программного обеспечения незнакомого подхода к проектированию встраиваемых систем. Перенести существующий однопетлевой код может быть непросто. Слишком мало или даже слишком много потоков могут стать препятствием для производительности.
Приложения, которые совместно используют структуры данных или устройства ввода-вывода между несколькими потоками или процессами, могут иметь узкие места в последовательном соединении. Для поддержания целостности данных доступ к этим общим ресурсам может потребоваться сериализовать с использованием методов блокировки, например, блокировки чтения, блокировки чтения-записи, блокировки записи, спин-блокировки, мьютекса и т. Д. Неэффективно спроектированные блокировки могут создавать узкие места из-за высокой конкуренции за блокировку между несколькими потоками или процессами, пытающимися получить блокировку для использования общего ресурса. Это потенциально может снизить производительность приложения или программного обеспечения. Производительность приложения может даже ухудшиться по мере увеличения количества ядер или процессоров, если одни ядра задерживают другие, ожидая общих блокировок, в результате чего два ядра работают хуже, чем одно.
Неравномерно распределенная рабочая нагрузка может неэффективно использовать вычислительные ресурсы. Возможно, вам придется разбить большие задачи на более мелкие, которые можно будет запускать параллельно. Возможно, вам придется изменить последовательные алгоритмы на параллельные для повышения производительности и масштабируемости. Однако, если некоторые задачи выполняются очень быстро, а другие требуют значительного количества времени, быстрые задачи могут тратить значительное количество времени на ожидание завершения длинных задач. Это приводит к простое ценных вычислительных ресурсов и плохому масштабированию производительности.
RTOS, вероятно, поможет вам, но может не решить все проблемы. В системе SMP это фактически необходимо для планирования задач по ряду аналогичных ядер. Работу, которую предстоит выполнить, можно разделить по данным или по функциям. Если вы разделите вещи на блоки данных, каждый поток может выполнять все шаги в конвейере обработки. В качестве альтернативы вы можете попросить один поток выполнить один шаг в функции, а другой - следующий шаг и т. Д. Преимущества одного метода перед другим будут зависеть от характеристик работы, которую предстоит выполнить.
Отладка в многоядерных средах
Первое, что пригодится при отладке многоядерной системы - это видимость всех ядер. В идеале мы должны иметь возможность запускать и останавливать ядра одновременно или по отдельности, то есть делать одно ядро пошагово, в то время как другие работают или останавливаются. Многоядерные точки останова могут быть очень полезны для управления работой одного ядра в зависимости от состояния другого.
Реализовать многоядерную трассировку может быть очень сложно. Управление высокой пропускной способностью информации трассировки от нескольких ядер, а также работа с потенциально разными типами данных трассировки из разных типов ядер - настоящая проблема.
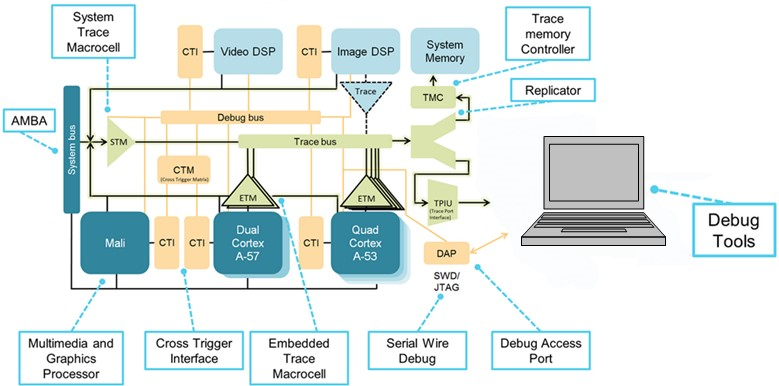
(Источник:IAR Systems, диаграмма предоставлена Arm Ltd.)
Вот пример процессора с гетерогенными и однородными многоядерными реализациями. Есть две однородные основные группы, одна на основе сдвоенного Arm Cortex-A57, а другая - на четырехъядерном Cortex-A53. Эти группы однородны внутри себя, но неоднородны между двумя группами.
Архитектура отладки CoreSight предоставляет протоколы и механизмы для связи с ресурсами отладки на всех ядрах, и отладчику приходится управлять всей этой информацией и анализировать сообщения от разных ядер. Интерфейсы перекрестного запуска и матрица (CTI, CTM) позволяют одновременно останавливать оба ядра, запускать трассировку и многое другое. Инфраструктура трассировки включает последовательные (SWD) и параллельные (TPIU) порты трассировки, используемые для сглаживания потока трассировки, и воронки трассировки, которые объединяют трассировку от каждого источника в единый поток. По сравнению с двухъядерным процессором, на диаграмме представлен более сложный для управления чип.
Отладчик C-SPY в IAR Embedded Workbench обеспечивает поддержку как симметричной, так и асимметричной многоядерной отладки. Это включается с помощью параметров отладчика на вкладке многоядерности. Чтобы включить симметричную многоядерную отладку, все, что требуется, - это ввести количество ядер, чтобы отладчик знал, с каким количеством различных процессоров следует взаимодействовать. В других IDE могут быть доступны аналогичные параметры.
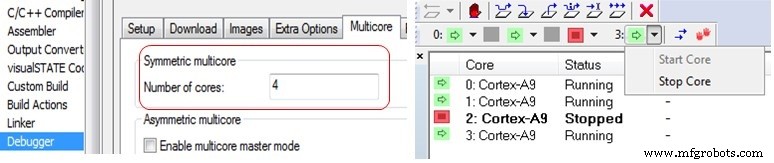
Справа (вверху) вы можете увидеть представление в отладчике, в котором состояние ядер 4-ядерного SMP-кластера Cortex-A9 отображается с остановленным ядром номер 2, в то время как остальные три ядра работают.
Асимметричная многоядерная система может использовать гетерогенную многоядерную часть, такую как STM32H745 / 755, которая имеет одно ядро Cortex-M7 и отдельное ядро Cortex-M4. В этом случае, когда отладчик запускается, он использует два экземпляра IDE (главный и узел). По одному для каждого ядра, поскольку на двух ядрах выполняется разный код проекта.
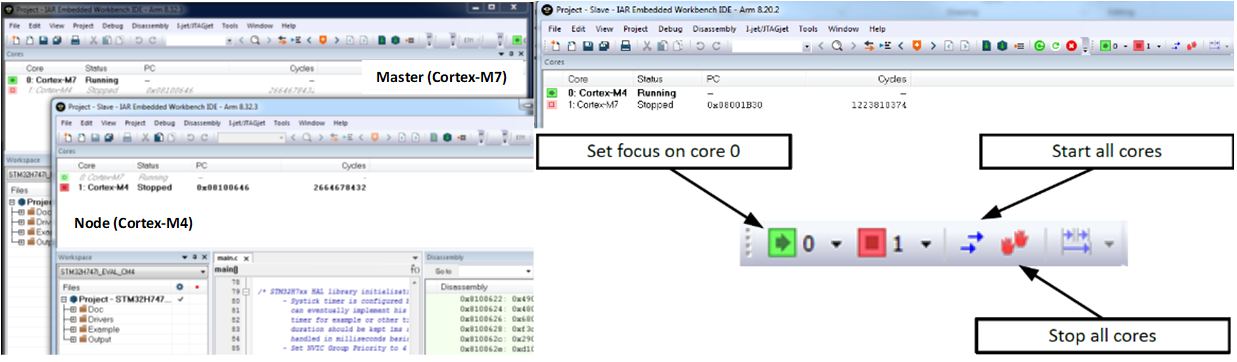
В каждом экземпляре IDE есть информация о состоянии контролируемого ядра, а также другого ядра, управляемого в другом окне. Существуют параметры, которые можно выбрать для управления поведением отладчика, чтобы запуск и остановка ядер вместе или по отдельности находились под контролем разработчика.
Этот полный контроль возможен благодаря интерфейсам перекрестного запуска (CTI) и матрице перекрестного запуска (CTM), которые вместе образуют встроенную функцию перекрестного запуска Arm. Существует три компонента CTI:один на системном уровне, один для Cortex-M7 и один для Cortex-M4. Три CTI подключены друг к другу через CTM, как показано на рисунке ниже. CTI уровня системы и Cortex-M4 доступны отладчику через порт доступа к системе и связанный APB-D. Cortex-M7 CTI физически интегрирован в ядро Cortex-M7 и доступен через порт доступа Cortex-M7.
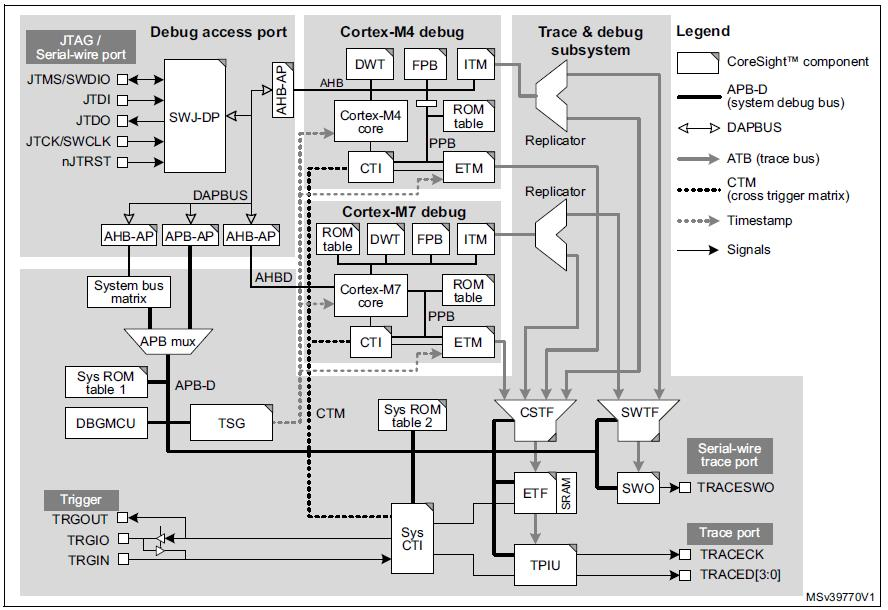
(Источник:IAR Systems, диаграмма любезно предоставлена STMicroelectronics из Справочного руководства M0399)
CTI позволяют событиям из различных источников запускать отладку и отслеживать действия. Например, точка останова, достигнутая в одном из ядер процессора, может остановить другой процессор, или переход, обнаруженный на входе внешнего триггера, может быть установлен для запуска трассировки кода.
В этом примере с гетерогенным многоядерным процессором, который имеет ядро Cortex-M7 и ядро Cortex-M4 на одном кристалле, используются две отдельные программы:одна для работы на Cortex-M4, а другая - на Cortex-M7. Каждый проект использует FreeRTOS для управления программным обеспечением, работающим на процессорах. Два ядра обмениваются данными через интерфейс общей памяти. Однако оба приложения используют механизмы передачи сообщений FreeRTOS для связи с другим процессором и скрывают сложность базовых механизмов. Итак, с точки зрения одного процессора, это просто отправка или получение сообщений с другой задачей. Совершенно очевидно, что другая задача выполняется на другом ядре ЦП.
Изображение ниже - это окно проводника рабочей области в среде IDE. Здесь отображается обзор двух проектов, поэтому вы можете видеть содержимое проектов Cortex-M7 и Cortex-M4.
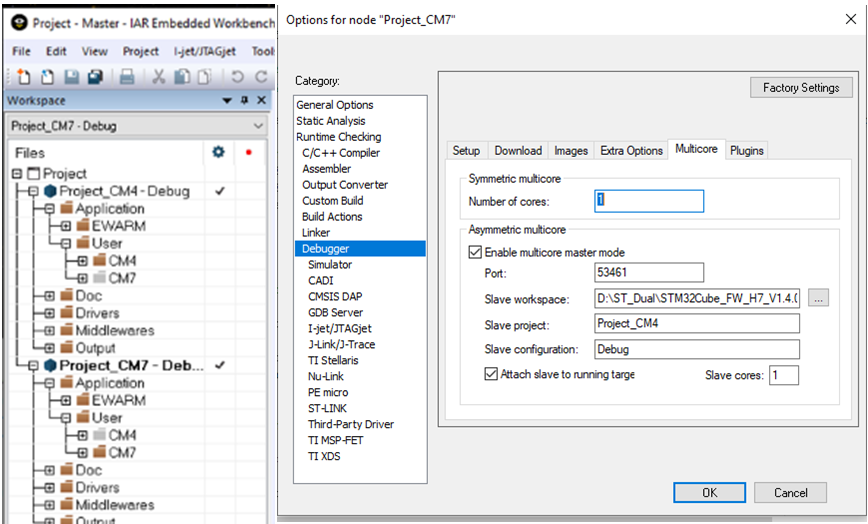
Выбрав одну из других вкладок внизу окна, вы можете переключить фокус на проект M4 или проект M7.
В проекте Cortex-M7 есть задача, которая отправляет сообщения задачам, выполняемым на Cortex-M4. Cortex-M4 имеет два запущенных экземпляра задачи приема. Cortex-M7 имеет задачу «проверки», которая периодически запускается, чтобы убедиться, что все еще работает правильно.
Наконец, отладчик загружает оба проекта. Это означает, что запускается дополнительный экземпляр Embedded Workbench для второго отладчика.
Чтобы настроить отладчик для поддержки асимметричной многопроцессорной обработки, нам нужно обозначить один проект как «Главный», а другой как «Узловой». Фактически, выбор является произвольным и определяет только, какой проект может запускать другой при запуске.
Проект «Узел» не имеет специальных настроек и не знает, что он работает как «Узел» для другого проекта.
Таким образом, когда «главный» проект запускает отладчик, он автоматически запускает другой экземпляр IDE, чтобы обеспечить второй сеанс отладчика, в котором будет запущен второй проект.
Резюме
Multicore позволяет повысить производительность, когда закон Мура истекает. Однако многоядерность создает проблемы для отладки и требует особых подходов к разработке, чтобы приложение могло максимально использовать преимущества многоядерной архитектуры.
После того, как настройка отладки настроена, отладка многоядерных процессоров становится еще проще. Если вы раньше использовали инструменты для отладки одноядерных процессоров, вы узнаете все, что в них включено, и, вероятно, никогда не поймете, как другие люди говорят о том, насколько сложна для них отладка многоядерных процессоров.
Современные аппаратные и программные средства помогут вам преодолеть проблемы многоядерной отладки.
Примечание:изображения на рисунках принадлежат IAR Systems, если не указано иное.
 Аарон Баух является старшим инженером по полевым приложениям в IAR Systems, работающим с клиентами в восточной части США и Канаде. Аарон работал со встроенными системами и программным обеспечением для таких компаний, как Intel, Analog Devices и Digital Equipment Corporation. Его проекты охватывают широкий спектр приложений, включая медицинские приборы, навигационные и банковские системы. Аарон также преподавал ряд курсов на уровне колледжа, включая проектирование встроенных систем в качестве профессора Южного университета штата Нью-Йорк. Г-н Баух имеет степень бакалавра электротехники от Cooper Union и степень магистра электротехники от Колумбийского университета в Нью-Йорке, штат Нью-Йорк.
Аарон Баух является старшим инженером по полевым приложениям в IAR Systems, работающим с клиентами в восточной части США и Канаде. Аарон работал со встроенными системами и программным обеспечением для таких компаний, как Intel, Analog Devices и Digital Equipment Corporation. Его проекты охватывают широкий спектр приложений, включая медицинские приборы, навигационные и банковские системы. Аарон также преподавал ряд курсов на уровне колледжа, включая проектирование встроенных систем в качестве профессора Южного университета штата Нью-Йорк. Г-н Баух имеет степень бакалавра электротехники от Cooper Union и степень магистра электротехники от Колумбийского университета в Нью-Йорке, штат Нью-Йорк. Связанное содержание:
- Обеспечение временных характеристик программного обеспечения в критически важных многоядерных встроенных системах.
- Многоядерные системы, гипервизоры и многоядерные платформы
- Высокопроизводительные встроенные вычисления - параллелизм и оптимизация компилятора.
- Вы думаете, что ваше программное обеспечение работает? Докажи это!
- Отслеживание программного обеспечения на устройствах, развернутых в полевых условиях.
- Компиляторы в чужом мире функциональной безопасности
Чтобы получить больше информации о Embedded, подпишитесь на еженедельную рассылку Embedded по электронной почте.
Встроенный
- Сети Wi-Fi, поставщики SaaS и проблемы, которые они несут ИТ
- Платы - Прорыв Pi - I2C, UART, GPIO и др.
- Пять основных проблем и проблем для 5G
- Сложные факторы риска, с которыми сталкиваются аэрокосмическая и оборонная промышленность
- 5G, IoT и новые проблемы цепочки поставок
- Решайте проблемы ETL данных IoT и максимизируйте рентабельность инвестиций
- Преодоление трудностей крутого поворота
- 4 основные проблемы, стоящие перед OEM-производителями аэрокосмической и оборонной промышленности
- Важность и проблемы актуальной документации
- Понимание преимуществ и проблем гибридного производства