


Решайте проблемы ETL данных IoT и максимизируйте рентабельность инвестиций
Организации могут оптимизировать данные Интернета вещей, быстро и экономично извлекая из них ценность для бизнеса, приобретая опыт в технологиях ETL (извлечение, передача, загрузка).
Потенциал Интернета вещей никогда не был выше. Ожидается, что к 2021 году инвестиции в устройства с поддержкой Интернета вещей удвоятся, а возможности в сегментах данных и аналитики будут расти. Проекты данных Интернета вещей.
Организации могут оптимизировать данные Интернета вещей, быстро и экономично извлекая их ценность для бизнеса, приобретая опыт в технологиях ETL (извлечение, передача, загрузка), таких как потоковая обработка и озера данных.
См. также: 4 принципа создания чистого озера данных
Однако во многих организациях это может привести к узким местам в ИТ, длительным задержкам проектов и откладыванию обработки данных. Результат. Проекты Интернета вещей, в которых данные прогнозной аналитики должны играть решающую роль в повышении операционной эффективности и стимулировании инноваций, по-прежнему еще не преодолели порог проверки концепции и определенно не могут продемонстрировать рентабельность инвестиций.
Понимание проблем ETL, с которыми сталкивается Интернет вещей
Следующая диаграмма поможет вам лучше понять проблему:
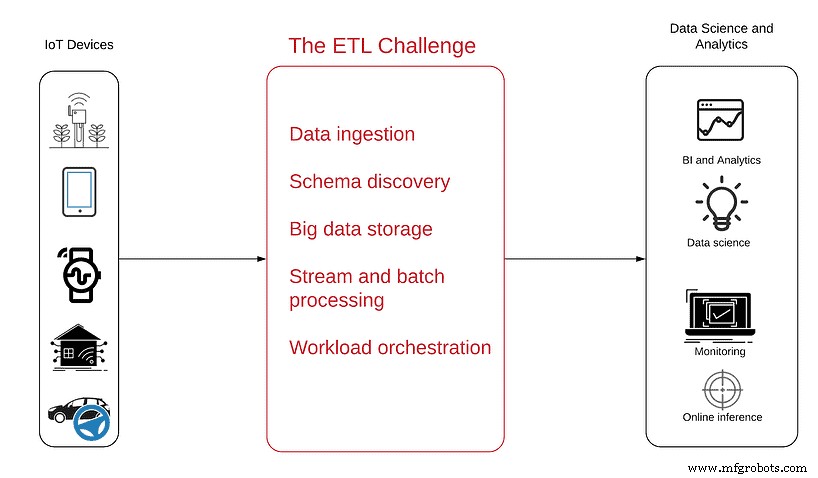
Источник данных находится слева — бесчисленное множество сенсорных устройств, от простых антенн до сложных автономных транспортных средств, которые генерируют данные Интернета вещей и отправляют их в виде непрерывного потока полуструктурированных данных через Интернет.
Справа указаны цели, которых должно достичь потребление указанных данных, с получением аналитических продуктов по завершении проекта, в том числе:
- Бизнес-аналитика чтобы получить представление о тенденциях и моделях использования продукта.
- Оперативный мониторинг чтобы увидеть сбои и неактивные устройства в режиме реального времени
- Обнаружение аномалий чтобы получать упреждающие оповещения о пиках или резком падении данных
- Встроенная аналитика чтобы клиенты могли видеть и понимать свои собственные данные об использовании.
- Наука о данных чтобы воспользоваться преимуществами расширенной аналитики и машинного обучения при профилактическом обслуживании, оптимизации маршрутов или разработке ИИ.
Для достижения этих целей вам необходимо сначала преобразовать данные из режима необработанной потоковой передачи в готовые к аналитике таблицы, которые можно запрашивать с помощью SQL и других инструментов аналитики.
Процесс ETL часто является наиболее сложным для понимания сегментом любого аналитического проекта, поскольку данные IoT содержат уникальный набор качеств, которые не всегда синхронизируются с обычными реляционными базами данных, ETL и инструментами BI. Например:
- Данные IoT — это потоковые данные. непрерывно генерируются в небольших файлах, которые накапливаются, превращаясь в массивные разветвленные наборы данных. Они сильно отличаются от традиционных табличных данных и требуют более сложных ETL для выполнения объединений, агрегирования и обогащения данных.
- Данные IoT нужно хранить сейчас, а анализировать позже. В отличие от обычных наборов данных, огромный объем данных, создаваемых устройствами Интернета вещей, означает, что они должны иметь место для хранения, прежде чем их можно будет проанализировать — облачное или локальное озеро данных.
- Данные IoT представляют собой неупорядоченные события из-за нескольких устройств которые могут перемещаться в области подключения к Интернету и выходить из них. Это означает, что журналы могут поступать на серверы в разное время и не всегда в «правильном» порядке.
- Для данных Интернета вещей часто требуется доступ с малой задержкой. С оперативной точки зрения вам, возможно, придется выявлять аномалии или определенные устройства в реальном или близком к реальному времени, поэтому вы не можете позволить себе задержки, вызванные пакетной обработкой.
Следует ли использовать платформы с открытым исходным кодом для создания озера данных?
Чтобы построить корпоративную платформу данных для анализа данных, многие организации используют этот распространенный подход:создают озеро данных, используя платформы потоковой обработки с открытым исходным кодом в качестве строительных блоков, а также базы данных временных рядов, такие как Apache Spark/Hadoop, Apache Flink, InfluxDB и другие.
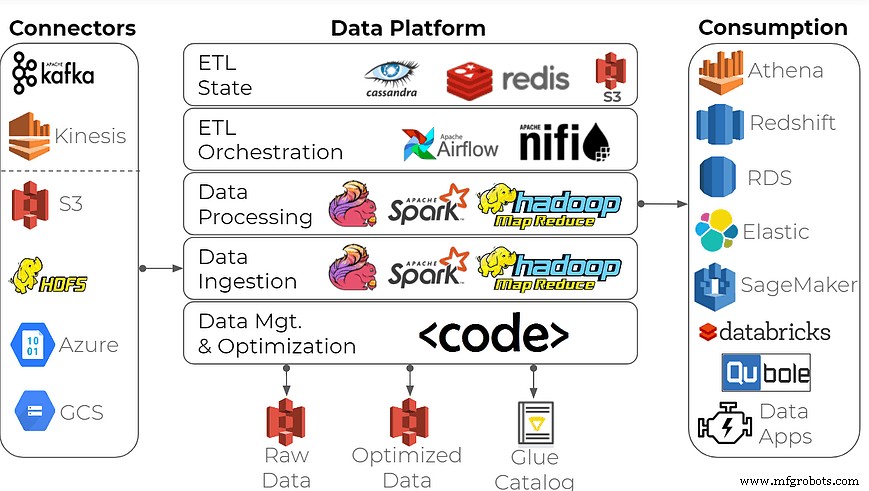
Может ли этот набор инструментов сделать работу? Конечно, но сделать это правильно может быть непосильной задачей для всех, кроме самых опытных компаний. Создание такой платформы данных требует специализированных навыков инженеров по работе с большими данными и пристального внимания к инфраструктуре данных, что обычно не очень подходит для производства и бытовой электроники, отраслей, которые тесно взаимодействуют с данными IoT. Ожидайте задержек с доставкой, высоких затрат и тонны потерянных инженерных часов.
Если вашей организации нужна высокая производительность, а также полный спектр функций и вариантов использования — операционная отчетность, специальная аналитика и подготовка данных для машинного обучения — выберите подходящее решение. Примером может служить использование ETL-платформы озера данных, специально созданной для преобразования потоков в готовые к анализу наборы данных.
Решение не такое жесткое и сложное, как платформы данных Spark/Hadoop. Он построен с пользовательским интерфейсом самообслуживания и SQL, а не с интенсивным программированием на Java/Scala. Для аналитиков, специалистов по данным, менеджеров по продуктам и поставщиков данных в DevOps и обработке данных это может быть по-настоящему удобный инструмент, который:
- Обеспечивает самообслуживание для потребителей данных без необходимости полагаться на ИТ-специалисты и специалистов по обработке данных.
- Оптимизирует потоки ETL и хранение больших данных для снижения затрат на инфраструктуру.
- Позволяет организациям благодаря полностью управляемому сервису сосредоточиться на функциях, а не на инфраструктуре.
- Устраняет необходимость поддерживать несколько систем для данных в реальном времени, специальной аналитики и отчетов.
- Гарантирует, что данные никогда не покидают аккаунт клиента AWS для обеспечения полной безопасности.
Вы можете извлечь выгоду из данных Интернета вещей — для того, чтобы сделать их полезными, нужны правильные инструменты.
Интернет вещей
- Интеллектуальные данные:следующий рубеж в Интернете вещей
- Простой, совместимый и безопасный - реализация концепции Интернета вещей
- Использование данных Интернета вещей от края до облака и обратно
- Какие отрасли станут победителями в революции Интернета вещей и почему?
- Необходимость интеграции данных срочна и нетривиальна, говорит отец Интернета вещей
- Три основных проблемы подготовки данных IoT
- Являются ли Интернет вещей и облачные вычисления будущим данных?
- AIoT:мощная конвергенция ИИ и Интернета вещей
- Демократизация Интернета вещей
- Максимизация ценности данных IoT