


Рекомендации по отладке приложений Интернета вещей на основе Zephyr
Проект Linux Foundation с открытым исходным кодом Zephyr стал основой многих проектов Интернета вещей. Zephyr предлагает лучшую в своем классе небольшую масштабируемую операционную систему реального времени (RTOS), оптимизированную для устройств с ограниченными ресурсами, в различных архитектурах. В настоящее время в проекте участвуют 1000 участников, а 50 000 совершают создание расширенной поддержки для различных архитектур, включая ARC, Arm, Intel, Nios, RISC-V, SPARC и Tensilica, а также более 250 плат.
При работе с Zephyr необходимо учитывать несколько важных факторов, позволяющих поддерживать надежную связь и функционирование. Разработчики не могут решить все классы проблем на своем рабочем месте, и некоторые из них становятся очевидными только тогда, когда парк устройств растет. По мере развития сетей и сетевых стеков вам необходимо следить за тем, чтобы обновления не вызывали ненужных проблем.
Например, рассмотрим ситуацию, с которой мы столкнулись с GPS-трекерами, установленными для отслеживания сельскохозяйственных животных. Устройство представляло собой сенсорный ошейник с малой занимаемой площадью. В любой день животное переходило из мобильной сети в мобильную; из страны в страну; от места к месту. Такое перемещение быстро выявило неправильную конфигурацию и неожиданное поведение, которое могло привести к потере мощности и значительным экономическим потерям. Нам не нужно было просто знать о проблеме, нам нужно было знать, почему это произошло и как это исправить. При работе с подключенными устройствами удаленный мониторинг и отладка имеют решающее значение для получения мгновенного понимания того, что пошло не так, дальнейших шагов по устранению ситуации и, в конечном итоге, того, как установить и поддерживать нормальную работу.
Мы используем комбинацию Zephyr и облачной платформы наблюдения за устройствами Memfault для поддержки мониторинга и обновления устройств. По нашему опыту, вы можете использовать и то, и другое, чтобы установить передовые методы удаленного мониторинга с использованием перезагрузок, сторожевых таймеров, ошибок / подтверждений и показателей подключения.
Настройка платформы наблюдения
Memfault позволяет разработчикам удаленно отслеживать, отлаживать и обновлять прошивку, что позволяет нам:
- Избегайте зависаний производства в пользу минимально жизнеспособного продукта и обновлений нулевого дня.
- постоянно контролировать общее состояние устройства.
- рассылать обновления и исправления до того, как большинство конечных пользователей заметят проблемы, если таковые имеются.
SDK Memfault легко интегрируется для сбора пакетов данных для облачного анализа и дедупликации. Он работает как типичный модуль Zephyr, куда вы добавляете его в свой файл манифеста.
# west.yml [...] - имя:memfault-firmware-sdk URL:https://github.com/memfault/memfault-firmware-sdk путь:modules / memfault-firmware-sdk версия:основная # prj.conf CONFIG_MEMFAULT =y CONFIG_MEMFAULT_HTTP_ENABLE =y
Первое направление:перезагрузки
Предположим, вы видите значительное количество сбросов на вашем устройстве. Это часто является ранним признаком того, что что-то в топологии изменилось или устройства начинают испытывать проблемы из-за дефектов оборудования. Это наименьшая часть информации, которую вы можете собрать, чтобы получить представление о работоспособности устройства, и ее можно разделить на две части:сброс оборудования и сброс программного обеспечения.
Аппаратные сбросы часто происходят из-за аппаратных сторожевых таймеров и сбоев. Сброс программного обеспечения может быть вызван обновлениями прошивки, утверждениями или инициирован пользователем.
Определив, какие типы сбросов происходят, мы можем понять, есть ли проблемы, которые затрагивают весь парк, или они ограничиваются небольшим процентом устройств.
Запишите причину перезагрузки
недействительно fw_update_finish (недействительно) { // ... memfault_reboot_tracking_mark_reset_imminent (kMfltRebootReason_FirmwareUpdate, ...); sys_reboot (0); } У Zephyr есть механизм регистрации регионов, которые будут сохраняться при сбросе, к которому подключается Memfault. Если вы собираетесь перезагрузить платформу, мы рекомендуем сохранить данные прямо перед началом работы. При перезагрузке платформы запишите причину перезагрузки - в данном случае обновление прошивки - и затем назовите ее Zephyr sys_reboot.
Запись сбросов устройства на Zephyr
Зарегистрируйте обработчик инициализации, который будет читать информацию о загрузке
статический int record_reboot_reason () { // 1. Считываем регистр причины аппаратного сброса. (Проверьте лист данных MCU на предмет имени регистра) // 2. Захватить причину сброса программного обеспечения из нулевой оперативной памяти // 3. Отправляем данные на сервер для агрегирования } SYS_INIT (record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); Вы можете настроить макрос, который собирает системную информацию перед сбросом через регистр причины сброса MCU. Когда устройство перезагружается, Zephyr зарегистрирует обработчики с помощью макроса system_int . Все регистры причин сброса MCU имеют несколько разные имена, и все они полезны, потому что вы можете увидеть, есть ли какие-либо аппаратные проблемы или дефекты.
Пример:проблема с источником питания
Давайте посмотрим на пример того, как удаленный мониторинг может дать жизненно важную информацию о состоянии автопарка, наблюдая за перезагрузками и энергоснабжением. Здесь мы видим, что на небольшое количество устройств приходится более 12 000 перезагрузок (рисунок 1).
щелкните, чтобы просмотреть изображение в полном размере

Рис. 1. Пример проблемы с источником питания, график перезагрузок за 15 дней. (Источник:авторы)
- 12 000 перезагрузок устройства в день - слишком много
- 99% перезагрузок приходится на 10 устройств.
- Неисправная механическая часть, из-за которой устройство постоянно перезагружается.
В этом случае некоторые устройства перезагружаются 1000 раз в день, вероятно, из-за механической проблемы (неисправная деталь, плохой контакт с батареей или различные хронические проблемы с частотой вращения).
Когда устройства будут запущены в производство, вы сможете решить ряд этих проблем с помощью обновлений прошивки. Развертывание обновления позволяет обойти аппаратные дефекты и избавиться от необходимости пытаться восстановить и заменить устройства.
Второе направление:сторожевые псы
При работе с подключенными стеками сторожевой таймер является последней линией защиты, которая возвращает систему в чистое состояние без ручного сброса устройства. Зависание может произойти по многим причинам, например
- Блокировка стека подключения при отправке ()
- Бесконечные циклы повторных попыток
- Тупиковые ситуации между задачами
- Коррупция
Аппаратные сторожевые таймеры - это выделенное периферийное устройство в MCU, которое необходимо периодически «подпитывать», чтобы предотвратить сброс устройства. Программные сторожевые таймеры реализованы в прошивке и срабатывают перед аппаратным сторожевым таймером, чтобы обеспечить захват состояния системы, ведущего к сторожевому таймеру оборудования
Zephyr имеет аппаратный сторожевой таймер API, в котором все микроконтроллеры могут использовать общий API для установки и настройки сторожевого таймера на платформе. (Подробнее см. Zephyr API:zephyr / include / drivers / watchdog.h)
// ... недействительно start_watchdog (недействительно) { // сверимся с деревом устройств на предмет доступного сторожевого таймера оборудования s_wdt =device_get_binding (DT_LABEL (DT_INST (0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ / * Сбросить SoC по истечении сторожевого таймера. * / .flags =WDT_FLAG_RESET_SOC, / * Срок действия сторожевого таймера после максимального окна * / .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout (s_wdt, &wdt_config); const uint8_t options =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup (s_wdt, параметры); // ЗАДАЧА:Запустите сторожевой таймер программного обеспечения } недействительно feed_watchdog (недействительно) { wdt_feed (s_wdt, s_wdt_channel_id); // ЗАДАЧА:Наблюдатель за программным обеспечением подачи } Давайте рассмотрим несколько шагов на этом примере Nordic nRF9160.
- Перейдите в дерево устройств и настройте папку времени просмотра Nordic nRF.
- Установите параметры конфигурации для сторожевого таймера с помощью открытого API.
- Установите сторожевой таймер.
- Периодически скармливайте сторожевому псу, когда поведение идет должным образом. Иногда это делается из задач с самым низким приоритетом. Если система зависнет, произойдет перезагрузка.
Используя Memfault на Zephyr, вы можете использовать таймеры ядра, работающие от периферийного таймера. Вы можете установить тайм-аут программного сторожевого таймера так, чтобы он опережал сторожевой таймер оборудования (например, установите сторожевой таймер оборудования на 60 секунд, а сторожевой таймер программного обеспечения на 50 секунд). Если обратный вызов когда-либо вызывается, будет запущено утверждение, которое проведет вас через обработчик ошибок Zephyr и получит информацию о том, что происходило в тот момент времени, когда система зависла.
Пример:зависание драйвера SPI
Давайте снова обратимся к примеру проблемы, которая не улавливается в разработке, но возникает на местах. На рисунке 2 вы можете увидеть время, факты и деградацию микросхем драйверов SPI.
щелкните, чтобы просмотреть изображение в полном размере
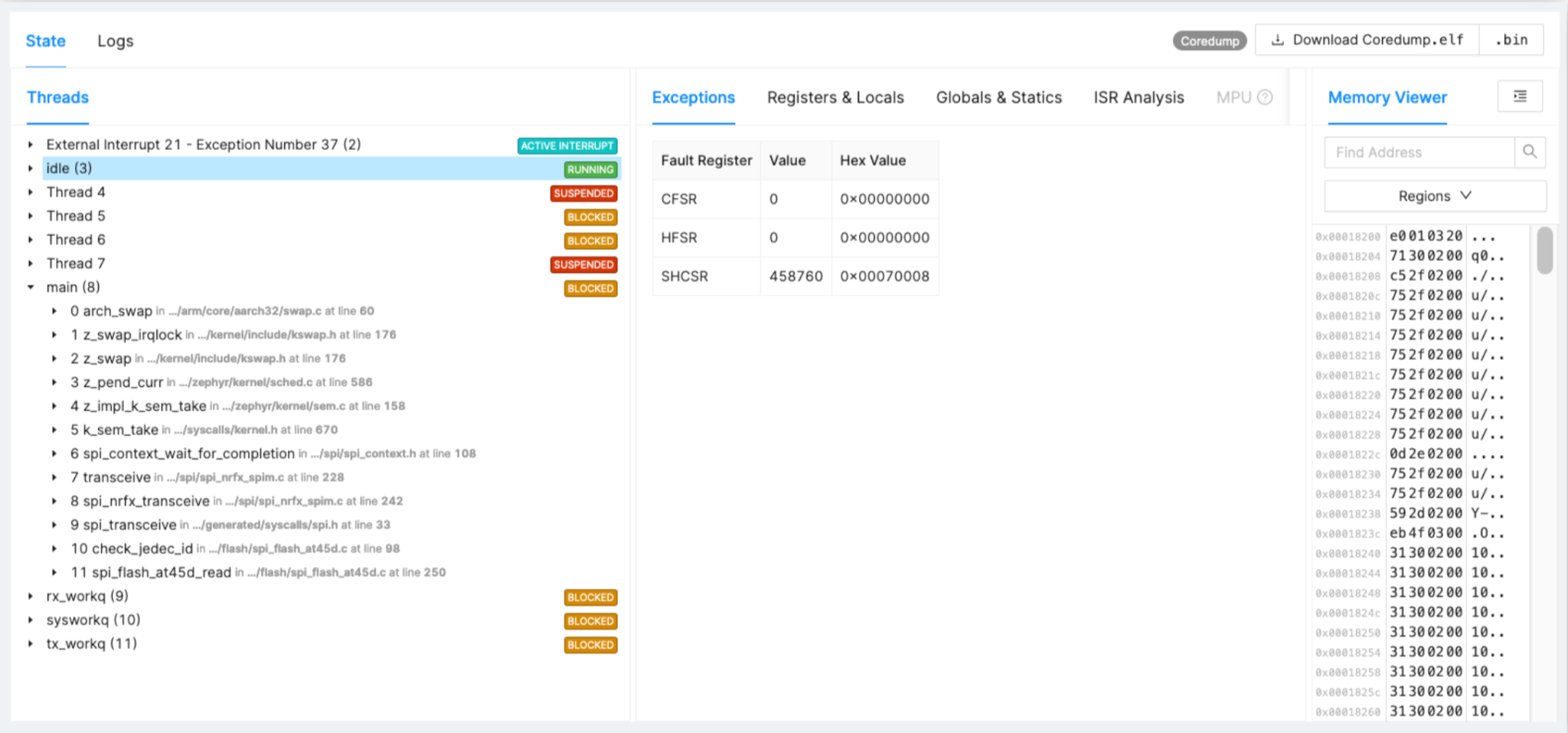
Рисунок 2:Пример зависания драйвера SPI. (Источник:авторы)
- Ухудшение состояния флэш-памяти SPI со временем, неправильное время передачи данных.
- Обнаружено это на 1% устройств после 16 месяцев развертывания на местах.
- Исправление драйвера и внедрение в следующем выпуске
Что касается Flash, после года работы в этой области вы можете увидеть, что внезапно возникают ошибки из-за зависания транзакций SPI или различных фрагментов кода. Наличие всей трассировки поможет вам найти основную причину и разработать решение.
Сторожевой таймер ниже (рис. 3) запускает обработчик ошибок Zephyr.
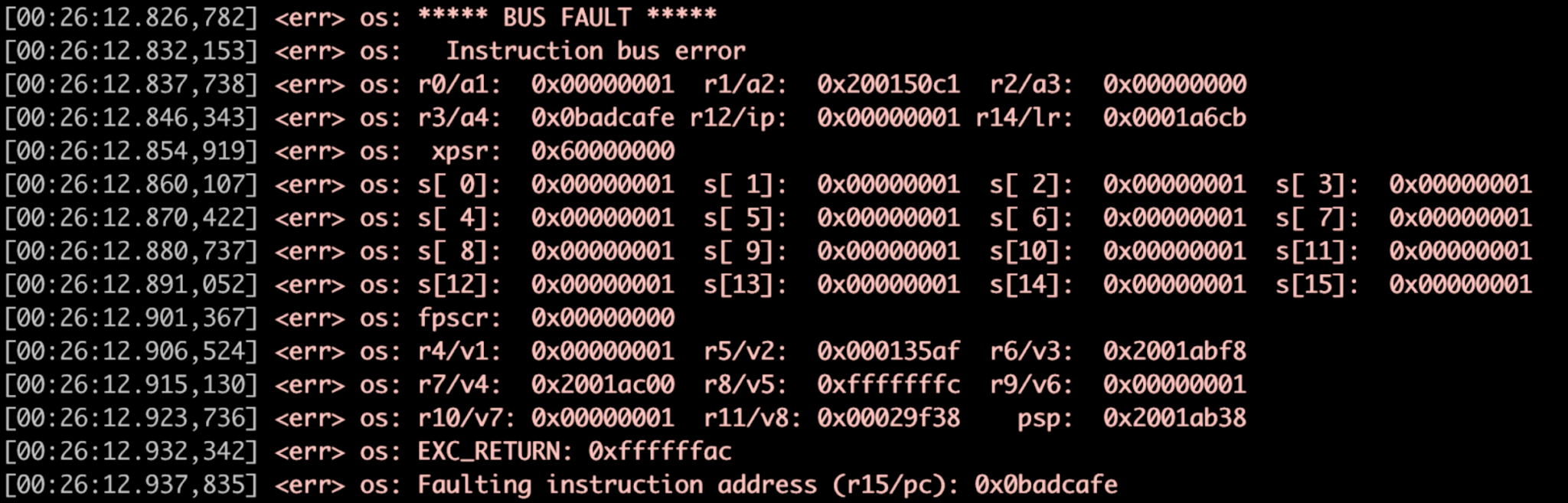
Рисунок 3:Пример обработчика ошибок, дамп регистра. (Источник:авторы)
Третье направление:ошибки / утверждения:
Третий компонент, который нужно отслеживать, - это ошибки и утверждения. Если вы когда-либо выполняли локальную отладку или создавали какие-то собственные функции, вы, вероятно, видели аналогичный экран о состоянии регистра, когда на платформе произошел сбой. Это может быть связано с:
- утверждает, или
- доступ к плохой памяти
- деление на ноль
- неправильное использование периферийного устройства
Вот пример потока обработки ошибок, который используется в микроконтроллерах Cortex M на платформе Zephyr.
недействительно network_send (недействительно) { const size_t packet_size =1500; void * buffer =z_malloc (размер_пакета); // отсутствует проверка на NULL! memcpy (буфер, 0x0, размер_пакета); // ... } ↓ недействительно network_send (недействительно) { const size_t packet_size =1500; void * buffer =z_malloc (размер_пакета); // отсутствует проверка на NULL! memcpy (буфер, 0x0, размер_пакета); // ... } ↓ булево memfault_coredump_save (const sMemfaultCoredumpSaveInfo * save_info) { // Сохраняем состояние регистра // Сохраняем _kernel и контексты задач // Сохраняем выбранные регионы .bss и .data } ↓ недействительно sys_arch_reboot (тип int) { // ... } Когда запускается утверждение или сбой, срабатывает прерывание и в Zephyr вызывается обработчик сбоев, который предоставляет состояние регистра на момент сбоя.
Memfault SDK автоматически встраивается в поток обработки ошибок, сохраняя важную информацию в облаке, включая состояние регистра, состояние ядра и часть всех задач, выполняемых в системе во время сбоя.
При локальной или удаленной отладке следует обратить внимание на три вещи:
- Регистр состояния сбоя Cortex M сообщает вам, почему платформа заявлена или неисправна.
- Memfault восстанавливает точную строку кода, которая выполнялась системой до сбоя, а также состояние всех других задач.
- Соберите _kernel структуры в ОСРВ Zephyr, чтобы увидеть планировщик, и, если это подключенное приложение, состояние параметров Bluetooth или LTE.
Четвертое направление:отслеживание показателей для наблюдения за устройством
Метрики отслеживания позволяют вам начать построение модели того, что происходит в вашей системе, и позволяют проводить сравнения между вашими устройствами и вашим парком, чтобы понять, какие изменения оказывают влияние.
Вот несколько показателей, которые полезно отслеживать:
- Загрузка ЦП
- параметры подключения
- использование тепла
С помощью Memfault SDK вы можете добавить и начать определение показателей в Zephyr с помощью двух строк кода:
- Определить показатель
MEMFAULT_METRICS_KEY_DEFINE ( LteDisconnect, kMemfaultMetricType_Unsigned)
- Обновить показатель в коде
недействительно lte_disconnect (недействительно) { memfault_metrics_heartbeat_add ( MEMFAULT_METRICS_KEY (LteDisconnect), 1); // ... } Memfault SDK + Cloud
- Сериализует и сжимает показатели для транспорта.
- Индексирует показатели по устройствам и версиям прошивки.
- Предоставляет веб-интерфейс для просмотра показателей по устройствам и по всему парку.
Десятки показателей могут быть собраны и проиндексированы по устройству и версии прошивки. Несколько примеров:
- Базовое подключение NB-IoT / LTE-M: Посмотрите, как модем влияет на срок службы батареи при подключении или подключении.
- Отслеживание базовых станций и PSM в NB-IoT / LTE-M: Качество мобильного сигнала может быть болезненным и может истощить заряд батареи, если его не контролировать. Создавайте показатели для состояния сети, событий, информации о вышках сотовой связи, настроек, таймеров и многого другого. Следите за изменениями и используйте предупреждения.
- Тестирование больших парков: Неожиданно большие данные могут увеличить затраты на подключение устройств и помочь выявить выбросы.
Пример:размер данных NB-IoT / LTE-M
щелкните, чтобы просмотреть изображение в полном размере
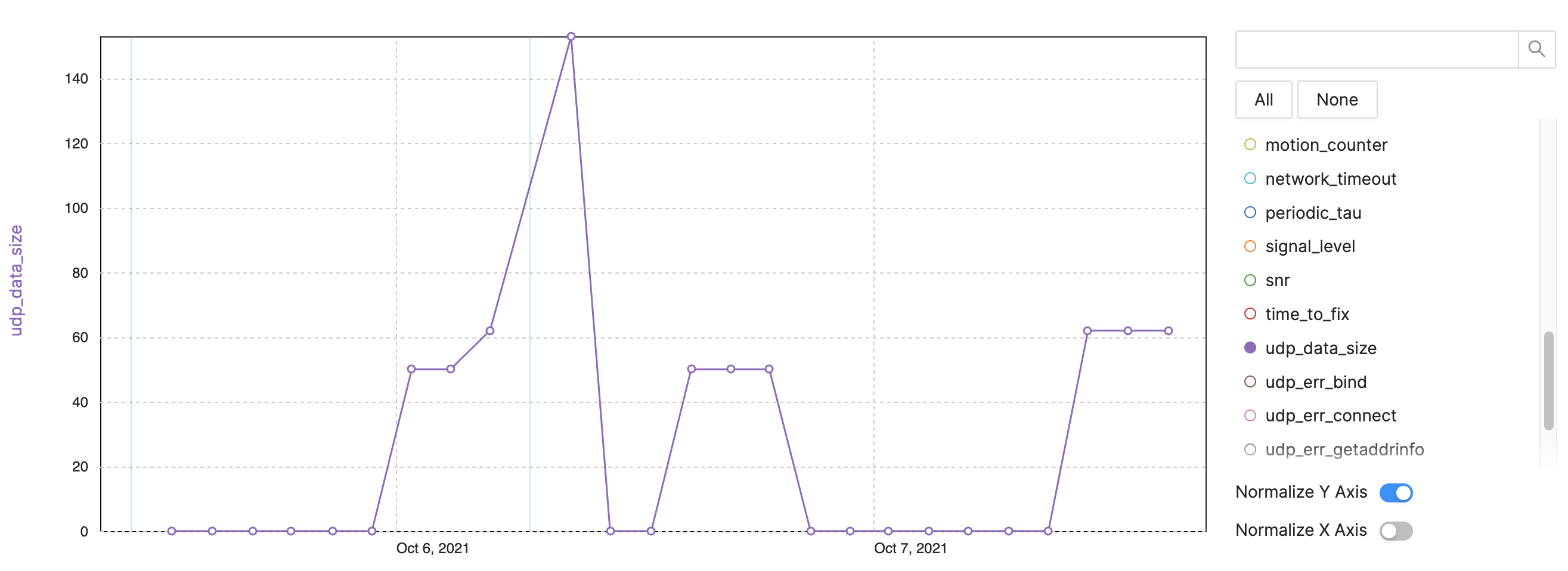
Рис. 4. Показатели отслеживания наблюдаемости устройства - пример NB-IoT, размер данных LTE-M. (Источник:авторы)
- Размер данных UDP:отслеживайте количество байтов за интервал отправки (рисунок 4).
- После перезагрузки отправляются дополнительные данные.
- Некоторые пакеты больше из-за дополнительной информации или следов.
- Отслеживайте проблему потребления данных.
Заключение
Используя Zephyr и Memfault, разработчики могут реализовать удаленный мониторинг, чтобы улучшить отслеживаемость функций подключенных устройств. Сосредоточившись на перезагрузках, наблюдениях, сбоях / утверждениях и показателях подключения, разработчики могут оптимизировать стоимость и производительность систем Интернета вещей.
Узнайте больше, посмотрев записанную презентацию с Саммита разработчиков Zephyr 2021 года.
Интернет вещей
- Лучшие практики для синтетического мониторинга
- Двунаправленные трансиверы 1G для поставщиков услуг и приложений Интернета вещей
- ETSI переходит к установлению стандартов для приложений IoT в экстренной связи
- IIC и TIoTA будут сотрудничать в области передового опыта IoT/Blockchain
- NIST публикует проект рекомендаций по безопасности для производителей IoT
- Партнерство направлено на бесконечное время автономной работы устройств IoT
- 3 причины использовать технологию IoT для управления активами
- Почему считают Интернет вещей лучшей платформой для мониторинга окружающей среды?
- Лучшие приложения для систем сжатого воздуха
- Оптимальные методы производственного маркетинга на 2019 год