


Как обучить нейронную сеть многослойного персептрона
Мы можем значительно повысить производительность перцептрона, добавив слой скрытых узлов, но эти скрытые узлы также немного усложняют обучение.
До сих пор из серии AAC о нейронных сетях вы узнали о классификации данных с использованием нейронных сетей, особенно разновидности Perceptron.
Ознакомьтесь с серией статей ниже или погрузитесь в эту новую статью, которая объясняет основы многослойной нейронной сети Perceptron (MLP).
- Как выполнить классификацию с помощью нейронной сети:что такое перцептрон?
- Как использовать простой пример нейронной сети персептрона для классификации данных
- Как обучить базовую нейронную сеть персептрона
- Общие сведения об обучении простой нейронной сети
- Введение в теорию обучения нейронных сетей.
- Скорость обучения в нейронных сетях
- Расширенное машинное обучение с многоуровневым персептроном
- Функция активации сигмовидной кишки:активация в многослойных перцептронных нейронных сетях.
- Как обучить многослойную нейронную сеть персептрона
- Понимание формул обучения и обратного распространения ошибки для многослойных персептронов
- Архитектура нейронной сети для реализации Python
- Как создать многослойную нейронную сеть персептрона на Python.
- Обработка сигналов с использованием нейронных сетей:проверка при проектировании нейронных сетей
- Обучающие наборы данных для нейронных сетей:как обучить и проверить нейронную сеть Python
Что такое многослойная нейронная сеть персептрона?
Предыдущая статья продемонстрировала, что однослойный персептрон просто не может обеспечить производительность, которую мы ожидаем от современной архитектуры нейронных сетей. Система, ограниченная линейно разделяемыми функциями, не сможет аппроксимировать сложные отношения ввода-вывода, которые возникают в реальных сценариях обработки сигналов. Решением является многослойный персептрон (MLP), такой как этот:
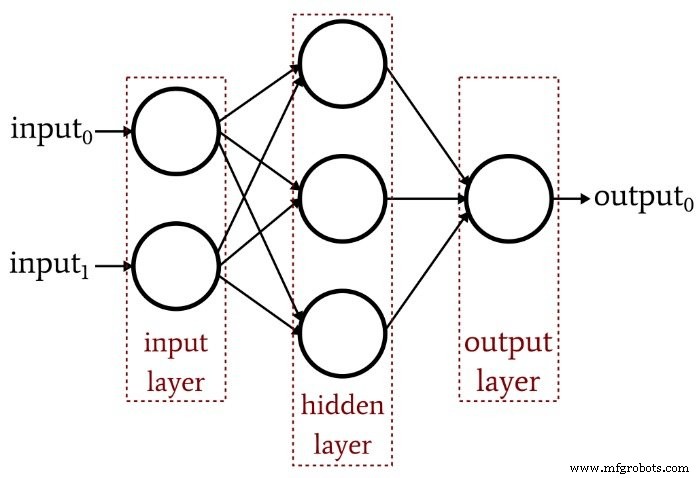
Добавляя этот скрытый слой, мы превращаем сеть в «универсальный аппроксиматор», который может обеспечить чрезвычайно сложную классификацию. Но всегда нужно помнить, что ценность нейронной сети полностью зависит от качества ее обучения. Без обширных разнообразных обучающих данных и эффективной процедуры обучения сеть никогда не «научится» классифицировать входные выборки.
Почему скрытый слой усложняет обучение?
Давайте посмотрим на правило обучения, которое мы использовали для обучения однослойного персептрона в предыдущей статье:
\ [w_ {new} =w + (\ alpha \ times (output_ {ожидаемый} -output_ {вычисленный}) \ times input) \]
Обратите внимание на неявное предположение в этом уравнении:мы обновляем веса на основе наблюдаемых выходных данных, поэтому для того, чтобы это работало, веса в однослойном персептроне должны напрямую влиять на выходное значение. Это все равно, что выбирать температуру воды в кране, поворачивая две ручки:горячая и холодная. Связь между общей температурой и действием ручки довольно проста, и даже люди, не любящие математику, могут найти желаемую температуру воды, немного повозившись с ручками.
Но теперь представьте, что поток воды по горячим и холодным трубам связан с положением ручки сложным и очень нелинейным образом. Вы постепенно и медленно поворачиваете ручку для горячей воды, но результирующая скорость потока меняется беспорядочно. Вы пробуете ручку для холодной воды, и она сделает то же самое. Установить идеальную температуру воды в этих условиях - особенно с учетом того, что «выход» должен достигаться за счет комбинации двух запутанных взаимосвязей управления, - было бы намного сложнее.
Вот как я понимаю дилемму скрытого слоя. Веса, которые соединяют входные узлы со скрытыми узлами, концептуально аналогичны этим механически неустойчивым ручкам - поскольку веса между входными и скрытыми не имеют прямого пути к выходному слою, связь между этими весами и выходом сети такова. сложный, что простое правило обучения, показанное выше, не будет эффективным.
Новая парадигма обучения
Поскольку исходное правило обучения персептрона не может быть применено к многослойным сетям, нам необходимо переосмыслить нашу стратегию обучения. Что мы собираемся сделать, так это включить градиентный спуск и минимизацию функции ошибок.
Следует иметь в виду, что эта процедура обучения не специфична для многослойных нейронных сетей. Градиентный спуск исходит из общей теории оптимизации, и процедура обучения, которую мы используем для MLP, также применима к одноуровневым сетям. Однако, насколько я понимаю, градиентный спуск в стиле MLP (по крайней мере теоретически) не нужен для однослойного персептрона, потому что более простое правило, показанное выше, в конечном итоге выполнит свою работу.
Вывод реальных уравнений обновления веса для MLP включает в себя некоторую пугающую математику, которую я не буду пытаться разумно объяснить на данном этапе. Моя цель до конца этой статьи - представить концептуальное введение в два ключевых аспекта обучения MLP - градиентный спуск и функцию ошибок - а затем мы продолжим это обсуждение в следующей статье, добавив новую функцию активации.
Градиентный спуск
Как следует из названия, градиентный спуск - это способ спуска к минимуму функции ошибок на основе наклона. На приведенной ниже диаграмме показано, как градиент дает нам информацию о том, как изменять веса - наклон точки на функции ошибок говорит нам, в каком направлении нам нужно двигаться и как далеко мы находимся от минимума.
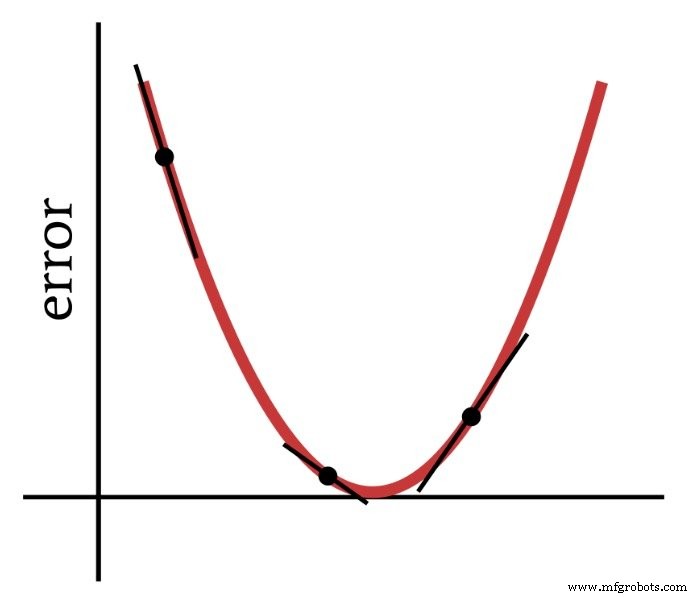
Таким образом, производная функции ошибок является важным элементом вычислений, которые мы используем для обучения многослойного персептрона. На самом деле нам понадобится частичное производные здесь. Когда мы реализуем градиентный спуск, мы делаем каждое изменение веса пропорциональным наклону функции ошибок по отношению к изменяемому весу.
Функция ошибки (функция потерь также известна как функция потерь)
Распространенным методом количественной оценки ошибки нейронной сети является возведение в квадрат разницы между ожидаемым (или «целевым») значением и вычисленным значением для каждого выходного узла, а затем суммирование всех этих квадратов разностей. Вы можете назвать это «сумма квадратов разности» или «суммарная квадратичная ошибка» или, может быть, другие вещи, и вы также увидите аббревиатуру LMS, которая означает наименьшее среднее квадратическое, потому что цель обучения состоит в том, чтобы минимизировать среднее значение. квадратичная ошибка. Эту функцию ошибок (обозначенную E) математически можно выразить следующим образом:
\ [E =\ frac {1} {2} \ sum_k (t_k-o_k) ^ 2 \]
где k указывает диапазон выходных узлов, t - целевое выходное значение, а o - вычисленное выходное значение.
Заключение
Мы заложили основу для успешного обучения многослойного персептрона, и продолжим изучение этой интересной темы в следующей статье.
Промышленный робот
- Топология сети
- Как стать автоэлектриком
- Как усилить защиту ваших устройств для предотвращения кибератак
- CEVA:AI-процессор второго поколения для глубоких рабочих нагрузок нейронных сетей
- Как сетевая экосистема меняет будущее фермы
- Что такое интеллектуальная сеть и как она может помочь вашему бизнесу?
- Что такое ключ безопасности сети? Как его найти?
- Искусственная нейронная сеть может улучшить беспроводную связь
- Насколько безопасна сеть вашего цеха?
- Как индустрия 4.0 обучает рабочую силу завтрашнего дня?