


Понимание формул обучения и обратного распространения ошибки для многослойных персептронов
В этой статье представлены уравнения, которые мы используем при выполнении вычислений с обновлением веса, а также мы обсудим концепцию обратного распространения ошибки.
Добро пожаловать в серию AAC по машинному обучению.
Следите за серией здесь:
- Как выполнить классификацию с помощью нейронной сети:что такое перцептрон?
- Как использовать простой пример нейронной сети персептрона для классификации данных
- Как обучить базовую нейронную сеть персептрона
- Общие сведения об обучении простой нейронной сети
- Введение в теорию обучения нейронных сетей.
- Скорость обучения в нейронных сетях
- Расширенное машинное обучение с многоуровневым персептроном
- Функция активации сигмовидной кишки:активация в многослойных перцептронных нейронных сетях.
- Как обучить многослойную нейронную сеть персептрона
- Понимание формул обучения и обратного распространения ошибки для многослойных персептронов
- Архитектура нейронной сети для реализации Python
- Как создать многослойную нейронную сеть персептрона на Python.
- Обработка сигналов с использованием нейронных сетей:проверка при проектировании нейронных сетей
- Обучающие наборы данных для нейронных сетей:как обучить и проверить нейронную сеть Python
Мы достигли точки, в которой нам необходимо тщательно рассмотреть фундаментальную тему теории нейронных сетей:вычислительную процедуру, которая позволяет нам точно настраивать веса многослойного персептрона (MLP), чтобы он мог точно классифицировать входные выборки. Это приведет нас к концепции «обратного распространения ошибки», которая является важным аспектом проектирования нейронных сетей.
Обновление веса
Информация, связанная с обучением для MLP, сложна. Что еще хуже, онлайн-ресурсы используют другую терминологию и символы, и даже кажется, что они дают разные результаты. Однако я не уверен, действительно ли результаты различаются или одна и та же информация представлена по-разному.
Уравнения, содержащиеся в этой статье, основаны на выводах и объяснениях, предоставленных доктором Дастином Стэнсбери в этом сообщении в блоге. Его трактовка - лучшее, что я нашел, и это отличное место для начала, если вы хотите вникнуть в математические и концептуальные детали градиентного спуска и обратного распространения ошибки.
На следующей диаграмме представлена архитектура, которую мы реализуем в программном обеспечении, и приведенные ниже уравнения соответствуют этой архитектуре, которая более подробно обсуждается в следующей статье.
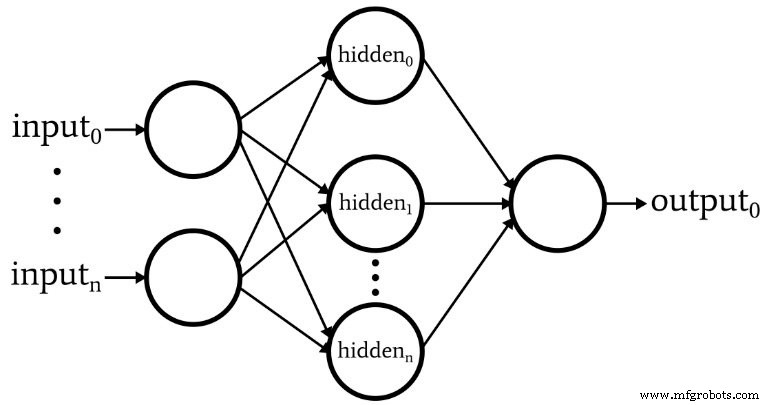
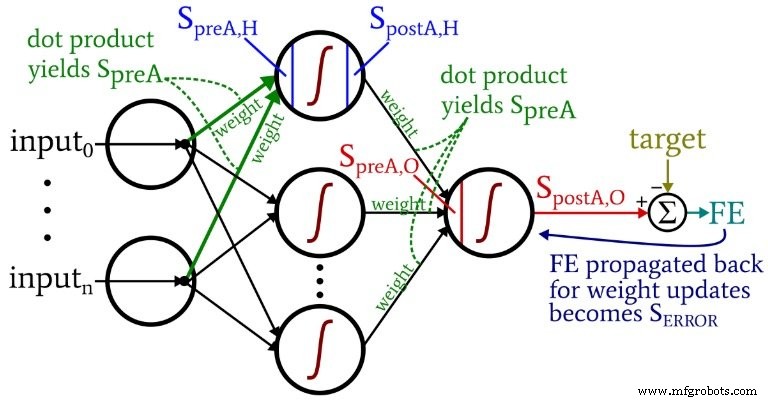
Терминология
Эта тема быстро становится неуправляемой, если мы не придерживаемся четкой терминологии. Я буду использовать следующие термины:
- Предварительная активация (сокращенно \ (S_ {preA} \) ):Это относится к сигналу (на самом деле это просто число в контексте одной обучающей итерации), который служит входными данными для функции активации узла. Он рассчитывается путем скалярного произведения массива, содержащего веса, и массива, содержащего значения, происходящие из узлов предыдущего уровня. Скалярное произведение эквивалентно выполнению поэлементного умножения двух массивов с последующим суммированием элементов в массиве, полученных в результате этого умножения.
- Постактивация (сокращенно \ (S_ {postA} \) ):Это относится к сигналу (опять же, просто число в контексте отдельной итерации), который выходит из узла. Он создается путем применения функции активации к сигналу предварительной активации. Я предпочитаю термин для функции активации, обозначенный как \ (f_ {A} () \) , является логистическим а не сигмовидную.
- В коде Python вы увидите весовые матрицы, помеченные как ItoH . и HtoO . Я использую эти идентификаторы, потому что было бы двусмысленно сказать что-то вроде «веса скрытого слоя» - будут ли это веса, которые применяются до скрытый слой или после скрытый слой? В моей схеме ItoH определяет веса, которые применяются к значениям, передаваемым из входных узлов в скрытые узлы, а HtoO определяет веса, которые применяются к значениям, передаваемым из скрытых узлов в выходной узел.
- Правильное выходное значение для обучающей выборки называется целевым . и обозначается T .
- Скорость обучения сокращенно LR .
- Последняя ошибка это разница между сигналом постактивации от выходного узла ( \ (S_ {postA, O} \) ) и цель, рассчитываемая как \ (FE =S_ {postA, O} - T \) .
- Сигнал ошибки ( \ (S_ {ОШИБКА} \) ) - это последняя ошибка, распространяющаяся обратно к скрытому слою через функцию активации выходного узла.
- Градиент представляет вклад данного веса в сигнал ошибки. Мы изменяем веса, вычитая этот вклад (при необходимости умноженный на скорость обучения).
Следующая диаграмма помещает некоторые из этих терминов в визуализированную конфигурацию сети. Я знаю - это похоже на разноцветный беспорядок. Я прошу прощения. Это насыщенная информацией диаграмма, и хотя на первый взгляд она может показаться немного оскорбительной, но если вы внимательно ее изучите, я думаю, вы найдете ее очень полезной.
Уравнения обновления веса выводятся путем взятия частной производной функции ошибок (мы используем суммарную квадратичную ошибку, см. Часть 8 серии, в которой рассматриваются функции активации) по отношению к изменяемому весу. Пожалуйста, обратитесь к сообщению доктора Стэнсбери, если вы хотите увидеть математику; в этой статье мы сразу перейдем к результатам. Для весов, скрытых для вывода, мы имеем следующее:
\ [S_ {ERROR} =FE \ times {f_A} '(S_ {preA, O}) \]
\ [gradient_ {HtoO} =S_ {ERROR} \ times S_ {postA, H} \]
\ [weight_ {HtoO} =weight_ {HtoO} - (LR \ times gradient_ {HtoO}) \]
Рассчитываем знак ошибки l умножением на окончательную ошибку по значению, которое получается, когда мы применяем производную функции активации на сигнал предварительной активации доставляется в выходной узел (обратите внимание на символ штриха, который указывает первую производную в \ ({f_A} '(S_ {preA, O}) \)). градиент затем вычисляется путем умножения сигнала ошибки по сигналу постактивации из скрытого слоя. Наконец, мы обновляем вес, вычитая этот градиент . от текущего значения веса, и мы можем умножить градиент по скорости обучения если мы хотим изменить размер шага.
Для весов, которые вводятся в скрытые, у нас есть следующее:
\ [gradient_ {ItoH} =FE \ times {f_A} '(S_ {preA, O}) \ times weight_ {HtoO} \ times {f_A}' (S_ {preA , H}) \ times input \]
\ [\ Rightarrow gradient_ {ItoH} =S_ {ERROR} \ times weight_ {HtoO} \ times {f_A} '(S_ {preA, H}) \ times input \]
\ [weight_ {ItoH} =weight_ {ItoH} - (LR \ times gradient_ {ItoH}) \]
При использовании весов «вход - скрытый» ошибка должна распространяться обратно через дополнительный слой, и мы делаем это, умножая сигнал ошибки . по весу скрытых для вывода подключен к скрытому интересующему узлу. Таким образом, если мы обновляем входной вес-скрытый который ведет к первому скрытому узлу, мы умножаем сигнал ошибки по весу, который соединяет первый скрытый узел с выходным узлом. Затем мы завершаем вычисление, выполняя умножения, аналогичные тем, которые используются при обновлении веса скрытых для вывода:мы применяем производную функции активации на сигнал предварительной активации скрытого узла , а «входное» значение можно рассматривать как сигнал постактивации из входного узла.
Обратное распространение
Вышеупомянутое объяснение уже затрагивало концепцию обратного распространения ошибки. Я просто хочу кратко усилить эту концепцию, а также убедиться, что вы хорошо знакомы с этим термином, который часто встречается в обсуждениях нейронных сетей.
Обратное распространение позволяет нам преодолеть дилемму скрытых узлов, обсуждаемую в части 8. Нам необходимо обновить веса от входных до скрытых на основе разницы между генерируемыми сетью выходными данными и целевыми выходными значениями, предоставленными обучающими данными, но эти веса влияют на сгенерированный вывод косвенно.
Обратное распространение - это метод, с помощью которого мы отправляем сигнал ошибки обратно на один или несколько скрытых слоев и масштабируем этот сигнал ошибки, используя как весовые коэффициенты, исходящие из скрытого узла, так и производную от функции активации скрытого узла. Общая процедура служит способом обновления веса на основе его вклада в ошибку вывода, даже несмотря на то, что этот вклад скрыт косвенной зависимостью между весовым коэффициентом «входной-скрытый» и сгенерированным выходным значением.
Заключение
Мы рассмотрели много важного материала. Я думаю, что в этой статье у нас есть действительно ценная информация об обучении нейронных сетей, и я надеюсь, что вы согласны. Серия станет еще более захватывающей, так что следите за новыми выпусками.
Промышленный робот
- Двунаправленные трансиверы 1G для поставщиков услуг и приложений Интернета вещей
- CEVA:AI-процессор второго поколения для глубоких рабочих нагрузок нейронных сетей
- Разблокировать нарезку интеллектуальной базовой сети для Интернета вещей и MVNO
- Пять основных проблем и проблем для 5G
- Как кормить беспроводные сенсорные сети и ухаживать за ними
- Руководство по пониманию бережливого производства и шести сигм для производства
- Обучение по вакуумному насосу BECKER для вас и меня
- Senet и SimplyCity объединяются для расширения LoRaWAN и IoT
- Понимание преимуществ и проблем гибридного производства
- Понимание ударопрочных инструментальных сталей для изготовления пуансонов и штампов