


Объединение в языке C для упаковки и распаковки данных
Узнайте об упаковке и распаковке данных с помощью объединений на языке C.
Узнайте об упаковке и распаковке данных с помощью объединений на языке C.
В предыдущей статье мы обсуждали, что первоначальное приложение объединений создавало общую область памяти для взаимоисключающих переменных. Однако со временем программисты широко использовали объединения для совершенно другого приложения:извлечения меньших частей данных из более крупного объекта данных. В этой статье мы рассмотрим это конкретное применение союзов более подробно.
Использование объединений для упаковки / распаковки данных
Члены союза хранятся в общей области памяти. Это ключевая особенность, которая позволяет нам находить интересные приложения для профсоюзов.
Рассмотрим объединение ниже:
union {uint16_t word; struct {uint8_t byte1; uint8_t byte2; };} u1; Внутри этого объединения два члена:первый член, «слово», представляет собой двухбайтовую переменную. Второй член - это структура из двух однобайтовых переменных. Два байта, выделенные для объединения, распределяются между двумя его членами.
Выделенное пространство памяти может быть таким, как показано на рисунке 1 ниже.
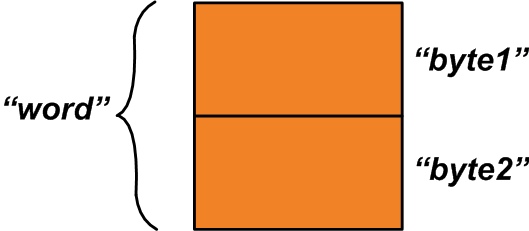
Рисунок 1
В то время как переменная «word» относится ко всему выделенному пространству памяти, переменные «byte1» и «byte2» относятся к однобайтовым областям, которые составляют переменную «word». Как мы можем использовать эту функцию? Предположим, что у вас есть две однобайтовые переменные, «x» и «y», которые следует объединить для получения одной двухбайтовой переменной.
В этом случае вы можете использовать указанное выше объединение и назначить «x» и «y» членам структуры следующим образом:
u1.byte1 =y; u1.byte2 =x; Теперь мы можем прочитать член объединения «word», чтобы получить двухбайтовую переменную, состоящую из переменных «x» и «y» (см. Рисунок 2).
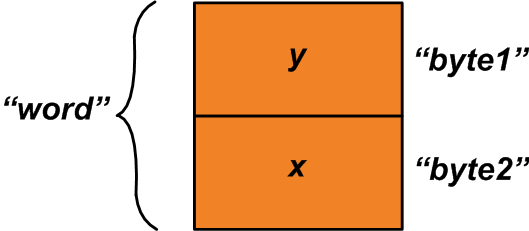
Рисунок 2
В приведенном выше примере показано использование объединений для упаковки двух однобайтовых переменных в одну двухбайтовую переменную. Мы также могли бы сделать обратное:записать двухбайтовое значение в «word» и распаковать его в две однобайтовые переменные, прочитав переменные «x» и «y». Запись значения в один член объединения и чтение другого члена иногда называют «каламбуром данных».
Порядок байтов процессора
При использовании объединений для упаковки / распаковки данных нам нужно быть осторожными с порядком байтов процессора. Как обсуждается в статье Роберта Кейма о порядке байтов, этот термин определяет порядок, в котором байты объекта данных хранятся в памяти. Процессор может быть с прямым порядком байтов или прямым порядком байтов. В процессоре с прямым порядком байтов данные хранятся таким образом, что байт, содержащий самый старший бит, имеет наименьший адрес памяти. В системах с прямым порядком байтов первым сохраняется байт, содержащий младший бит.
Пример, изображенный на рисунке 3, иллюстрирует порядок байтов с прямым и обратным порядком байтов для последовательности 0x01020304.
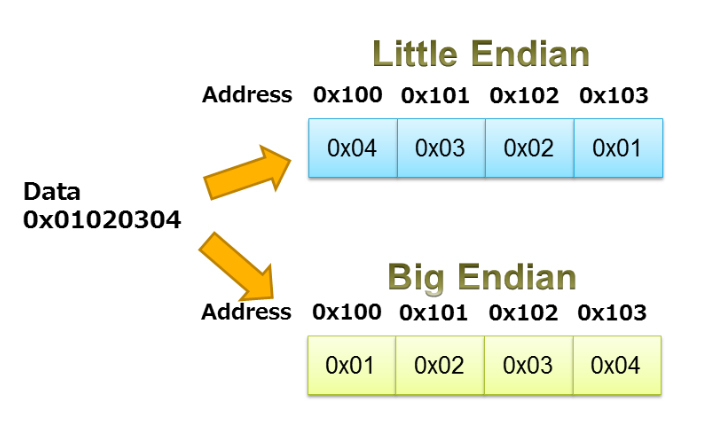
Рисунок 3. Изображение предоставлено IAR.
Давайте воспользуемся следующим кодом, чтобы поэкспериментировать с объединением из предыдущего раздела:
#include <stdio.h > # include <stdint.h >int main () {union {struct {uint8_t byte1; uint8_t byte2; }; uint16_t word; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf ("Word is:% # X", u1.word); return 0;} Запустив этот код, я получаю следующий результат:
Слово:0X4321
Это показывает, что первый байт общего пространства памяти («u1.byte1») используется для хранения младшего значащего байта (0X21) переменной «слово». Другими словами, процессор, который я использую для выполнения кода, имеет обратный порядок байтов.
Как видите, это конкретное приложение объединений может демонстрировать поведение, зависящее от реализации. Однако это не должно быть серьезной проблемой, потому что для такого низкоуровневого кодирования мы обычно знаем порядок байтов процессора. Если мы не знаем этих деталей, мы можем использовать приведенный выше код, чтобы узнать, как данные организованы в памяти.
Альтернативное решение
Вместо использования объединений мы также можем использовать побитовые операторы для упаковки или распаковки данных. Например, мы можем использовать следующий код, чтобы объединить две однобайтовые переменные, «byte3» и «byte4», и создать одну двухбайтовую переменную («word2»):
word2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); Давайте сравним результат этих двух решений в случаях с прямым порядком байтов и прямым порядком байтов. Рассмотрим код ниже:
#include <stdio.h > # include <stdint.h >int main () {union {struct {uint8_t byte1; uint8_t byte2; }; uint16_t word1; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf («Слово1:% # X \ n», u1.word1); uint8_t byte3, byte4; uint16_t word2; byte3 =0x21; byte4 =0x43; word2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); printf ("Word2:% # X \ n", word2); возврат 0;} Если мы скомпилируем этот код для процессора с прямым порядком байтов, такого как TMS470MF03107 , вывод будет:
Word1: 0X2143
Word2: 0X2143
Однако, если мы скомпилируем его для процессора с прямым порядком байтов, такого как STM32F407IE , вывод будет:
Word1: 0X4321
Word2: 0X2143
В то время как метод на основе объединения демонстрирует поведение, зависящее от оборудования, метод, основанный на операции сдвига, приводит к тому же результату независимо от порядка байтов процессора. Это связано с тем, что при последнем подходе мы присваиваем значение имени переменной («word2»), а компилятор заботится об организации памяти, используемой устройством. Однако с помощью метода на основе объединения мы изменяем значение байтов, составляющих переменную «word1».
Хотя метод на основе объединения демонстрирует поведение, зависящее от оборудования, его преимущество состоит в том, что он более читабелен и удобен в обслуживании. Вот почему многие программисты предпочитают использовать объединения для этого приложения.
Практический пример «вытеснения данных»
При работе с распространенными протоколами последовательной связи нам может потребоваться выполнить упаковку или распаковку данных. Рассмотрим протокол последовательной связи, который отправляет / принимает один байт данных во время каждой коммуникационной последовательности. Пока мы работаем с однобайтовыми переменными, передавать данные легко, но что, если у нас есть структура произвольного размера, которая должна проходить через канал связи? В этом случае мы должны каким-то образом представить наш объект данных в виде массива однобайтовых переменных. Как только мы получим это представление массива байтов, мы можем передавать байты по каналу связи. Затем, на стороне приемника, мы можем упаковать их соответствующим образом и восстановить исходную структуру.
Например, предположим, что нам нужно отправить переменную с плавающей запятой, «f1», через соединение UART. Переменная с плавающей запятой обычно занимает четыре байта. Следовательно, мы можем использовать следующее объединение в качестве буфера для извлечения четырех байтов из «f1»:
union {float f; struct {uint8_t byte [4]; };} u1; Передатчик записывает переменную «f1» в член объединения с плавающей запятой. Затем он считывает массив «байтов» и отправляет байты по каналу связи. Получатель делает обратное:он записывает полученные данные в «байтовый» массив своего собственного объединения и считывает переменную с плавающей запятой объединения как полученное значение. Мы могли бы использовать этот метод для передачи объекта данных произвольного размера. Следующий код может быть простым тестом для проверки этой техники.
#include <stdio.h > # include <stdint.h >int main () {float f1 =5.5; буфер объединения {float f; struct {uint8_t byte [4]; }; }; объединение буфера buff_Tx; объединение буфера buff_Rx; buff_Tx.f =f1; buff_Rx.byte [0] =buff_Tx.byte [0]; buff_Rx.byte [1] =buff_Tx.byte [1]; buff_Rx.byte [2] =buff_Tx .byte [2]; buff_Rx.byte [3] =buff_Tx.byte [3]; printf ("Полученные данные:% f", buff_Rx.f); возврат 0;} На рисунке 4 ниже изображена обсуждаемая техника. Обратите внимание, что байты передаются последовательно.
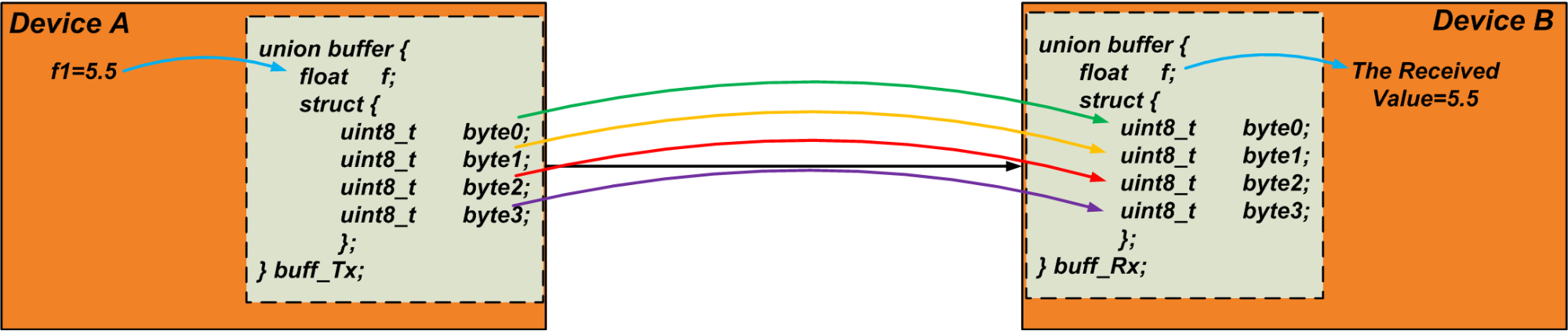
Рисунок 4
Заключение
В то время как первоначальное приложение объединений создавало общую область памяти для взаимоисключающих переменных, со временем программисты широко использовали объединения для совершенно другого приложения:объединения для упаковки / распаковки данных. Это конкретное применение объединений включает в себя запись значения одному члену объединения и чтение другого его члена.
«Перфорирование данных» или использование объединений для упаковки / распаковки данных может привести к аппаратно-зависимому поведению. Однако его преимущество в том, что он более читабелен и удобен в обслуживании. Вот почему многие программисты предпочитают использовать объединения для этого приложения. «Воспроизведение данных» может быть особенно полезным, когда у нас есть объект данных произвольного размера, который должен проходить через канал последовательной связи.
Чтобы увидеть полный список моих статей, посетите эту страницу.
Встроенный
- Семафоры:служебные службы и структуры данных
- Стратегия армии и решения по техническому обслуживанию по состоянию
- Преимущества адаптации решений IIoT и анализа данных для EHS
- Создание ответственного и заслуживающего доверия ИИ
- Что такое туманные вычисления и что они означают для Интернета вещей?
- С - Союзы
- Почему данные и контекст важны для видимости цепочки поставок
- Для управления автопарком ИИ и Интернет вещей лучше вместе
- Промышленный AIoT:сочетание искусственного интеллекта и Интернета вещей для Индустрии 4.0
- Litmus и Oden объединяют решения IIoT для интеллектуального производства