


Разработка новых навыков программирования, чтобы уменьшить количество ошибок во встроенном программном обеспечении
Размер и сложность приложений значительно увеличились за последнее десятилетие. Возьмем, к примеру, автомобильный сектор. По данным The New York Times , 20 лет назад средний автомобиль имел миллион строк кода, но 10 лет спустя Chevrolet Volt General Motors 2010 имел около 10 миллионов строк кода - больше, чем у истребителя F-35. Сегодня в среднем автомобиле содержится более 100 миллионов строк кода.
Переход на 32-битные и более мощные процессоры с большим объемом памяти и мощностью позволил компаниям встраивать в проекты гораздо больше дополнительных функций и возможностей; это плюс. Обратной стороной является то, что объем кода и его сложность часто приводят к сбоям, которые влияют на безопасность и безопасность приложений.
Пора применить лучший подход. В программном обеспечении можно обнаружить два основных типа ошибок, которые можно устранить с помощью инструментов, предотвращающих появление ошибок:
- Ошибки кодирования. Примером может служить код, который пытается получить доступ за пределы массива. Подобные проблемы можно обнаружить, выполнив статический анализ.
- Ошибки приложения:их можно обнаружить, только точно зная, что приложение должно делать, что означает тестирование на соответствие требованиям.
Устраните эти ошибки, и инженеры-проектировщики пройдут долгий путь к более безопасному и надежному коду.
Немного профилактики с помощью проверки кода
Ошибки в коде возникают так же легко, как и ошибки в электронной почте и обмене мгновенными сообщениями. Это простые ошибки, которые возникают из-за того, что инженеры спешат и не корректируют. Но со сложностью приходит целый ряд ошибок проектирования, которые создают огромные проблемы. Сложность порождает потребность в совершенно новом уровне понимания того, как работает система, как передаются данные и как определяются значения. Независимо от того, вызваны ли ошибки сложностью или какой-либо проблемой, связанной с человеком, они могут привести к тому, что фрагмент кода попытается получить доступ к значению за пределами массива. И это улавливается в стандарте кодирования.
Возможно, вас заинтересуют эти статьи из Embedded:
Создавайте безопасные и надежные встроенные системы с помощью MISRA C / C ++
Использование статического анализа для обнаружения ошибок кода в серверных приложениях с открытым исходным кодом, критически важных для безопасности
Как избежать таких ошибок? Во-первых, не помещайте их туда. Хотя это кажется очевидным - и почти невозможным, - это именно та ценность, которую дает стандарт кодирования.
В мире C и C ++ 80% программных дефектов вызваны неправильным или опрометчивым использованием примерно 20% языка. Стандарт кодирования накладывает ограничения на те части языка, которые считаются проблемными. Результат:устранение дефектов и значительное повышение качества программного обеспечения. Давайте взглянем на пару примеров.
Большинство ошибок программирования на C и C ++ вызвано неопределенным, определяемым реализацией и неопределенным поведением, присущим каждому языку, что приводит к ошибкам программного обеспечения и проблемам безопасности. Это определяемое реализацией поведение передает старший бит, когда целое число со знаком сдвигается вправо. В зависимости от используемого разработчиками компилятора результата может быть 0x40000000 или 0xC0000000, поскольку C не определяет порядок, в котором оцениваются аргументы функции.
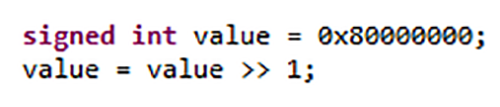
Рис. 1. Поведение некоторых конструкций C и C ++ зависит от используемого компилятора. Источник:LDRA
На рисунке 2, где rollDice () функция просто считывает следующее значение из кольцевого буфера, содержащего значения «1, 2, 3 и 4» - ожидаемое возвращаемое значение будет 1234. Но нет гарантии этого. По крайней мере, один компилятор генерирует код, который возвращает значение 3412.

Рис. 2. Поведение некоторых конструкций C и C ++ не определяется языками. Источник:LDRA
В языке C / C ++ есть и другие подводные камни:использование таких конструкций, как goto или malloc ; смесь значений со знаком и без знака; или «умный» код, который может быть очень эффективным и компактным, но настолько загадочным и сложным, что другим трудно его понять. Любая из этих проблем может привести к дефектам, переполнению значений, которое внезапно станет отрицательным, или просто сделать код невозможным для поддержки.
Стандарты кодирования обеспечивают унцию профилактики этих недугов. Они могут предотвратить использование этих проблемных конструкций и помешать разработчикам создавать недокументированный, чрезмерно сложный код, а также проверять согласованность стиля. Можно отслеживать даже такие вещи, как проверка того, что символ табуляции не используется или круглые скобки расположены в определенной позиции. Хотя это кажется тривиальным, следование стилю чрезвычайно помогает проверке кода вручную и предотвращает путаницу, вызванную разным размером вкладки при просмотре кода в другом редакторе - все это отвлекает рецензента от сосредоточения на коде.
MISRA приходит на помощь
Самыми известными стандартами программирования являются руководящие принципы MISRA, впервые опубликованные в 1998 году для автомобильной промышленности и теперь широко используемые многими встроенными компиляторами, которые предлагают определенный уровень проверки MISRA. MISRA фокусируется на проблемных конструкциях и практиках в языках C и C ++, рекомендуя использовать согласованные стилистические характеристики, но не предлагает их.
Руководства MISRA содержат полезные объяснения того, почему существует каждое правило, а также детали различных исключений из этого правила и примеры неопределенного, неопределенного и определяемого реализацией поведения. На рисунке 3 показан уровень руководства.

Рис. 3. Эти ссылки MISRA C относятся к неопределенному, неопределенному и определяемому реализацией поведению. Источник:LDRA
Большинство руководств MISRA являются «решаемыми», что означает, что инструмент может определить, есть ли нарушение; но некоторые из них «неразрешимы», что означает, что инструмент не всегда может определить, есть ли нарушение.
Неинициализированная переменная, переданная системной функции, которая должна ее инициализировать, может не регистрироваться как ошибка, если у инструмента статического анализа нет доступа к исходному коду для системной функции. Есть вероятность ложноотрицательного или ложноположительного результата.
В 2016 году в MISRA было добавлено 14 руководящих принципов, обеспечивающих проверку критически важного для безопасности кода, а не только безопасности. На рисунке 4 показано, как одно из новых правил - Директива 4.14 - решает эту проблему и помогает предотвратить ошибки, связанные с неопределенным поведением.

Рисунок 4. Директива 4.14 MISRA помогает предотвратить ошибки, вызванные неопределенным поведением. Источник:LDRA
Строгие стандарты кодирования традиционно ассоциировались с функционально безопасным программным обеспечением для критически важных приложений, таких как автомобили, самолеты и медицинские устройства. Однако сложность кода, критичность безопасности и важность для бизнеса создания высококачественного, надежного кода, который легко поддерживать и обновлять, делают стандарты кодирования критически важными во всех операциях разработки.
Обеспечивая отсутствие ошибок в коде, команды разработчиков должны:
- уменьшить потребность в обширной отладке,
- лучше контролировать расписание и
- контролировать рентабельность инвестиций за счет сокращения общих затрат.
Проверка кода предлагает набор инструментов с огромными потенциальными преимуществами.
Фунт лекарства с помощью инструментов для тестирования
Хотя проверка кода решает множество проблем, ошибки приложений можно найти только путем проверки того, выполняет ли продукт то, что он должен делать, а это означает наличие требований. Чтобы избежать ошибок приложения, необходимо разработать правильный продукт и разработать правильный продукт.
Разработка правильного продукта означает установление требований заранее и обеспечение двунаправленной прослеживаемости между требованиями и исходным кодом, чтобы каждое требование было реализовано, а каждая функция программного обеспечения прослеживалась до требования. Любые отсутствующие или ненужные функции, которые не соответствуют требованиям, являются ошибкой приложения. Правильное проектирование продукта - это процесс подтверждения того, что разработанный системный код соответствует требованиям проекта. Вы добиваетесь этого, выполняя тестирование на основе требований.
На рисунке 5 показан пример двунаправленной прослеживаемости. Выбранная единственная функция отслеживает восходящий поток от функции к требованию низкого уровня, затем к требованию высокого уровня и, наконец, к требованию системного уровня.
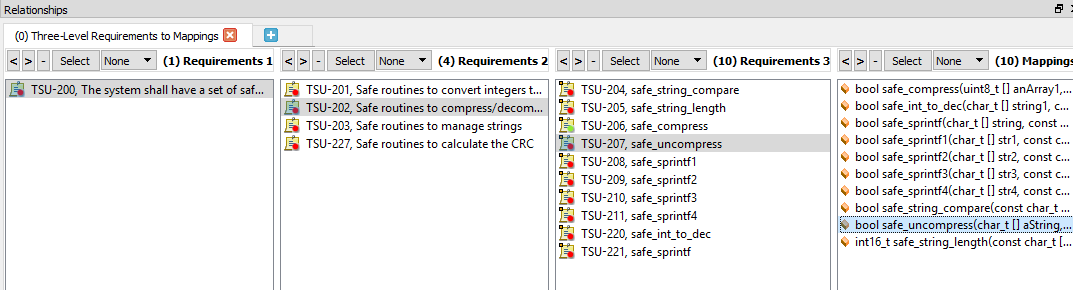
Рисунок 5. Это пример двунаправленной трассировки с одной выбранной функцией. Источник:LDRA
На рисунке 6 показано, как выбор высокоуровневого требования отображает прослеживаемость как восходящего потока до требований системного уровня, так и нисходящего потока - до требований низкого уровня и функций исходного кода.
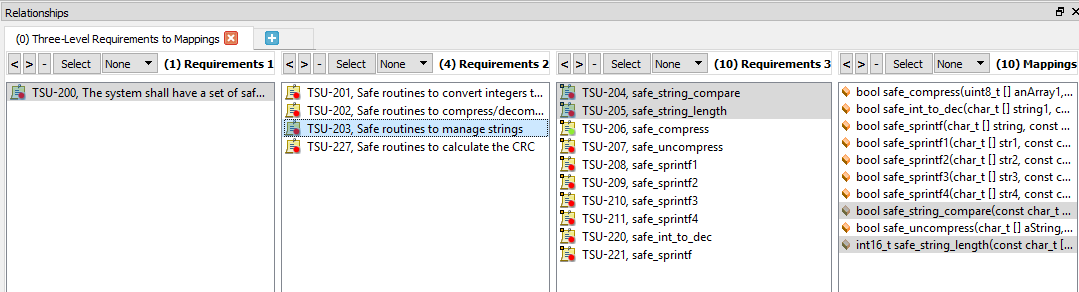
Рисунок 6. Это пример двунаправленной прослеживаемости с выбранными требованиями. Источник:LDRA
Эта способность визуализировать отслеживаемость может привести к обнаружению ошибок приложения на ранних этапах жизненного цикла.
Для тестирования функциональности кода требуется понимание того, что он должен делать, а это означает наличие низкоуровневых требований, определяющих, что делает каждая функция. На рисунке 7 показан пример низкоуровневого требования, которое в данном случае полностью описывает одну функцию.
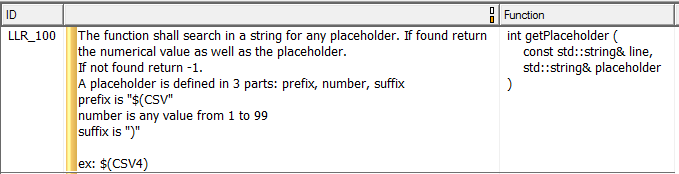
Рисунок 7. Это пример низкоуровневого требования, описывающего одну функцию. Источник:LDRA
Тестовые примеры основаны на низкоуровневых требованиях, как показано на рисунке 8.
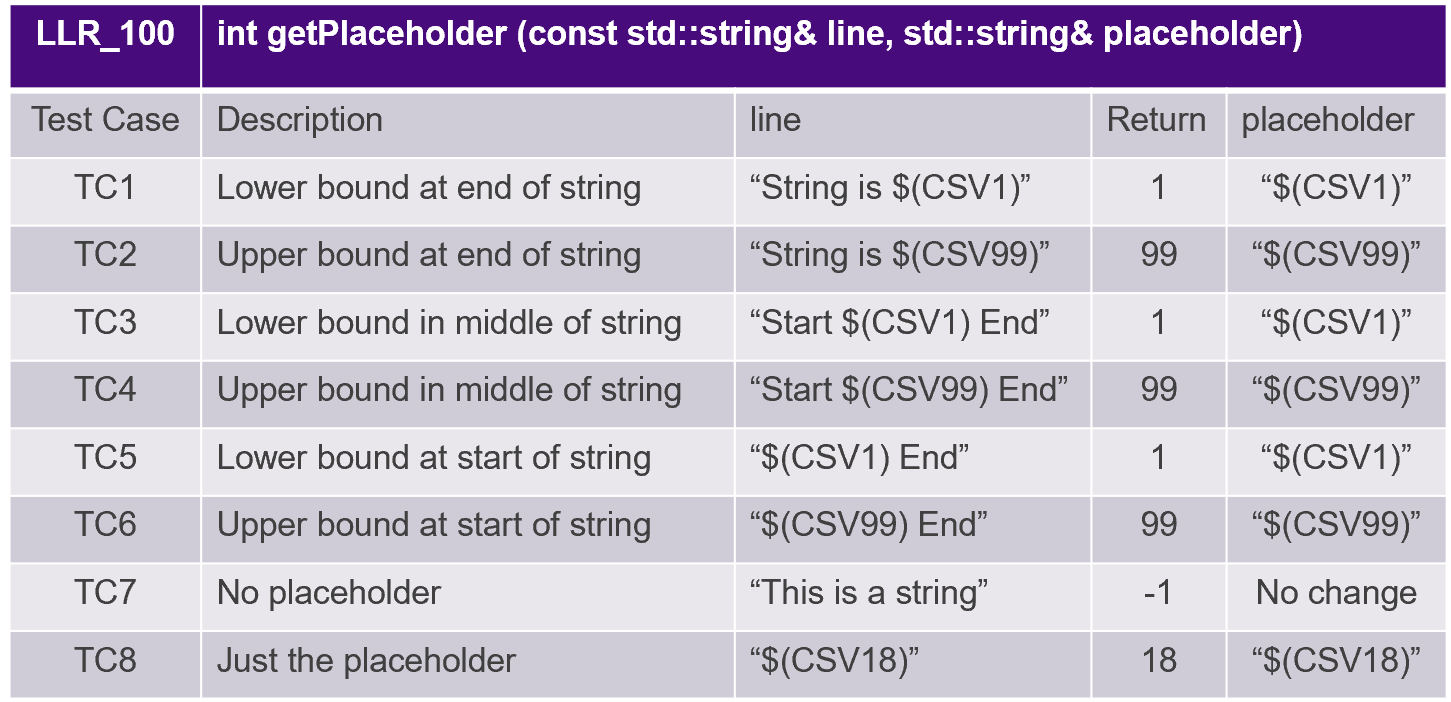
Рис. 8. Тестовые примеры основаны на низкоуровневых требованиях. Источник:LDRA
Затем с помощью инструмента модульного тестирования эти тестовые примеры могут быть выполнены на хосте или целевом компьютере, чтобы убедиться, что код ведет себя так, как того требует требование. На рисунке 9 показано, что все тестовые примеры были регрессированы и пройдены.
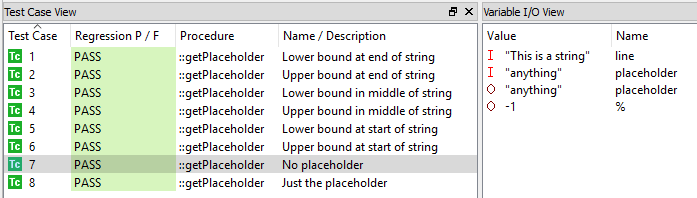
Рисунок 9. Вот как инструмент выполняет модульные тесты. Источник:LDRA
После выполнения тестовых примеров необходимо измерить структурное покрытие, чтобы убедиться, что весь код отработан. Если покрытие не является 100-процентным, возможно, потребуется больше тестовых примеров или следует удалить лишний код.
Новые привычки в программировании
Нет никаких сомнений в том, что сложность программного обеспечения и связанные с ним ошибки резко выросли из-за возможностей подключения, более быстрой памяти, богатых аппаратных платформ и особых требований заказчиков. Принятие современного стандарта кодирования, измерение показателей кода, отслеживание требований и внедрение тестирования на основе требований предоставляют командам разработчиков возможность создавать высококачественный код и снижать ответственность.
Степень принятия командой этих новых привычек, когда стандарты не требуют соблюдения, зависит от корпоративного признания изменений в правилах игры, которые они приносят. Внедрение этих методов, независимо от того, является ли продукт критичным с точки зрения безопасности или защиты, может повлиять на удобство сопровождения и надежность кода днем и ночью. Чистый код упрощает добавление новых функций, упрощает обслуживание продукта и сводит к минимуму затраты и график - все это характеристики, которые повышают рентабельность инвестиций вашей компании.
Независимо от того, является ли продукт критичным для безопасности или нет, это, безусловно, результат, который может быть выгоден только команде разработчиков.
>> Эта статья была первоначально опубликована на наш дочерний сайт EDN.
Встроенный
- Являются ли текстовые строки уязвимостью во встроенном ПО?
- Архитектура SOAFEE для встроенной периферии позволяет программно определяемым автомобилям
- Pixus:новые толстые и прочные лицевые панели для встроенных плат
- Kontron:новый стандарт встроенных вычислений COM HPC
- GE Digital запускает новое программное обеспечение для управления активами
- Как не отстать при обучении новому программному обеспечению
- Программные риски:защита открытого исходного кода в IoT
- Три шага к защите цепочек поставки программного обеспечения
- Saelig выпускает новый встраиваемый ПК от Amplicon
- Использование DevOps для решения проблем встроенного программного обеспечения