


Как создать кольцевой буфер FIFO в VHDL
Циклические буферы — популярные конструкции для создания очередей в последовательных языках программирования, но они также могут быть реализованы аппаратно. В этой статье мы создадим кольцевой буфер на VHDL для реализации FIFO в блочной оперативной памяти.
При реализации FIFO вам придется принять множество проектных решений. Какой интерфейс вам нужен? Вы ограничены в ресурсах? Должен ли он быть устойчивым к перечтению и перезаписи? Допустима ли задержка? Вот некоторые из вопросов, которые возникают у меня, когда меня просят создать FIFO.
В Интернете существует множество бесплатных реализаций FIFO, а также генераторы FIFO, такие как Xilinx LogiCORE. Но все же многие инженеры предпочитают реализовывать собственные FIFO. Потому что, несмотря на то, что все они выполняют одни и те же основные задачи очереди и удаления из очереди, они могут сильно различаться, если учитывать детали.
Как работает кольцевой буфер
Кольцевой буфер — это реализация FIFO, которая использует непрерывную память для хранения буферизованных данных с минимальным перемешиванием данных. Новые элементы остаются в той же ячейке памяти с момента записи до тех пор, пока они не будут прочитаны и удалены из FIFO.
Два счетчика используются для отслеживания местоположения и количества элементов в FIFO. Эти счетчики относятся к смещению от начала области памяти, где хранятся данные. В VHDL это будет индекс ячейки массива. В оставшейся части этой статьи мы будем называть эти счетчики указателями. .
Эти два указателя являются head и хвост указатели. Голова всегда указывает на слот памяти, который будет содержать следующие записанные данные, а хвост указывает на следующий элемент, который будет прочитан из FIFO. Есть и другие варианты, но мы собираемся использовать именно этот.
Пустое состояние
![]()
Если начало и конец указывают на один и тот же элемент, это означает, что FIFO пуст. На изображении выше показан пример FIFO с восемью слотами. И головной, и хвостовой указатели указывают на элемент 0, указывая на то, что FIFO пуст. Это начальное состояние кольцевого буфера.
Обратите внимание, что FIFO по-прежнему был бы пуст, если бы оба указателя находились в другом индексе, например, 3. При каждой записи указатель начала перемещается на одну позицию вперед. Указатель хвоста увеличивается каждый раз, когда пользователь FIFO читает элемент.
Когда любой из указателей находится в самом высоком индексе, следующая запись или чтение заставят указатель вернуться к самому низкому индексу. В этом прелесть кольцевого буфера:данные не перемещаются, перемещаются только указатели.
Голова ведет хвост

На изображении выше показан тот же кольцевой буфер после пяти операций записи. Указатель хвоста по-прежнему находится на слоте номер 0, но указатель начала переместился на слот номер 5. Слоты, содержащие данные, окрашены на рисунке голубым цветом. Указатель хвоста будет на самом старом элементе, а указатель головы укажет на следующий свободный слот.
Когда голова имеет более высокий индекс, чем хвост, мы можем вычислить количество элементов в кольцевом буфере, вычитая хвост из головы. На изображении выше это дает пять элементов.
Хвост ведет голову

Вычитание головы из хвоста работает только в том случае, если голова ведет хвост. На изображении выше голова имеет индекс 2, а хвост — индекс 5. Таким образом, если мы выполним это простое вычисление, мы получим 2 – 5 =-3, что не имеет смысла.
Решение состоит в том, чтобы сместить заголовок с общим количеством слотов в FIFO, в данном случае 8. Расчет теперь дает (2 + 8) – 5 =5, что является правильным ответом.
Хвост будет вечно гоняться за головой, так работает кольцевой буфер. В половине случаев хвост будет иметь более высокий индекс, чем голова. Данные хранятся между ними, как показано голубым цветом на изображении выше.
Полное состояние

Полный кольцевой буфер будет иметь хвост, указывающий на индекс сразу после головы. Следствием этой схемы является то, что мы никогда не сможем использовать все слоты для хранения данных, должен быть хотя бы один свободный слот. На изображении выше показана ситуация, когда кольцевой буфер заполнен. Открытый, но неиспользуемый слот окрашен в желтый цвет.
Для индикации того, что кольцевой буфер заполнен, можно также использовать выделенный пустой/полный сигнал. Это позволило бы хранить данные во всех слотах памяти, но требует дополнительной логики в виде регистров и таблиц поиска (LUT). Поэтому мы собираемся использовать держать открытым схема для нашей реализации кольцевого буфера FIFO, так как это только тратит впустую более дешевую блочную ОЗУ.
Реализация кольцевого буфера FIFO
То, как вы определяете сигналы интерфейса к вашему FIFO и от него, будет ограничивать количество возможных реализаций вашего кольцевого буфера. В нашем примере мы собираемся использовать вариант классического интерфейса разрешения чтения/записи и пустого/полного/действительного интерфейса.
Будет запись данных шина на входной стороне, которая несет данные, которые должны быть помещены в FIFO. Также будет разрешить запись сигнал, который при утверждении заставит FIFO производить выборку входных данных.
Выходная сторона будет иметь чтение данных и действительно для чтения сигнал, управляемый FIFO. Он также будет иметь включение чтения сигнал, управляемый нижестоящим пользователем FIFO.
пусто и полный управляющие сигналы являются частью классического интерфейса FIFO, их мы тоже будем использовать. Они управляются FIFO, и их цель — сообщать о состоянии FIFO устройствам чтения и записи.
Противодавление
Проблема с ожиданием, пока FIFO не опустеет или не заполнится, прежде чем предпринимать какие-либо действия, заключается в том, что логика интерфейса не успеет отреагировать. Последовательная логика работает на основе тактового цикла, передние фронты тактового сигнала эффективно разделяют события в вашем проекте на временные интервалы.

Одним из решений является включение
В нашей реализации предыдущие сигналы будут называться empty_next. и full_next , просто потому, что я предпочитаю добавлять к именам постфикс, а не префикс.

Объект
На изображении ниже показана сущность нашего кольцевого буфера FIFO. В дополнение к входным и выходным сигналам в порту есть две общие константы. RAM_WIDTH generic определяет количество битов во входных и выходных словах, количество битов, которое будет содержать каждый слот памяти.
RAM_DEPTH generic определяет количество слотов, которые будут зарезервированы для кольцевого буфера. Поскольку один слот зарезервирован для индикации того, что кольцевой буфер заполнен, емкость FIFO будет RAM_DEPTH – 1. RAM_DEPTH константа должна соответствовать глубине оперативной памяти на целевой FPGA. Неиспользуемая ОЗУ в примитиве блочной ОЗУ будет потрачена впустую, ее нельзя использовать совместно с другой логикой в ПЛИС.
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
В дополнение к часам и сбросу объявление порта будет включать классические порты данных/разрешения чтения и записи. Они используются вышестоящим и нижестоящим модулями для отправки новых данных в FIFO и для извлечения из него самого старого элемента.
rd_valid сигнал утверждается FIFO, когда rd_data порт содержит достоверные данные. Это событие задерживается на один такт после импульса на rd_en сигнал. Подробнее о том, почему так должно быть, мы поговорим в конце этой статьи.
Затем идут флаги пустой/полный, установленные FIFO. empty_next сигнал будет установлен, когда останется 1 или 0 элементов, в то время как empty активен только тогда, когда в FIFO 0 элементов. Точно так же full_next signal укажет, что есть место для еще 1 или 0 элементов, а full подтверждается только тогда, когда FIFO не может вместить другой элемент данных.
Наконец, есть fill_count выход. Это целое число, которое будет отражать количество элементов, хранящихся в настоящее время в FIFO. Я включил этот выходной сигнал просто потому, что мы будем использовать его внутри модуля. Прорыв его через объект практически бесплатен, и пользователь может оставить этот сигнал неподключенным при создании экземпляра этого модуля.
Декларативная область
В декларативной области файла VHDL мы объявим пользовательский тип, подтип, количество сигналов и процедуру для внутреннего использования в модуле кольцевого буфера.
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
Во-первых, мы объявляем новый тип для моделирования нашей оперативной памяти. ram_type type представляет собой массив векторов, размер которых определяется общими входными данными. Новый тип используется в следующей строке для объявления ram. сигнал, который будет хранить данные в кольцевом буфере.
В следующем блоке кода мы объявляем index_type , подтип целого числа. Его диапазон будет косвенно регулироваться RAM_DEPTH общий. Ниже объявления подтипа мы используем индексный тип для объявления двух новых сигналов, указателей на начало и конец.
Затем следует блок объявлений сигналов, которые являются внутренними копиями сигналов объекта. Они имеют те же базовые имена, что и сигналы объектов, но с постфиксом _i. чтобы указать, что они предназначены для внутреннего использования. Мы используем этот подход, потому что использование inout считается плохим стилем. режим для сигналов сущностей, хотя это имело бы тот же эффект.
Наконец, мы объявляем процедуру с именем incr. который принимает index_type сигнал как параметр. Эта подпрограмма будет использоваться для увеличения указателей начала и конца и возврата их к 0, когда они будут иметь самое высокое значение. Голова и хвост являются подтипами целого числа, которые обычно не поддерживают перенос. Мы воспользуемся процедурой, чтобы обойти эту проблему.
Параллельные операторы
В верхней части архитектуры мы объявляем наши параллельные операторы. Я предпочитаю собирать эти однострочные назначения сигналов перед обычными процессами, потому что их легко не заметить. Параллельный оператор на самом деле является формой процесса, вы можете прочитать больше о параллельных операторах здесь:
Как создать параллельный оператор в VHDL
-- Copy internal signals to output empty <= empty_i; full <= full_i; fill_count <= fill_count_i; -- Set the flags empty_i <= '1' when fill_count_i = 0 else '0'; empty_next <= '1' when fill_count_i <= 1 else '0'; full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0'; full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
В первом блоке параллельных назначений мы копируем внутренние версии сигналов сущности на выход. Эти линии гарантируют, что сигналы объекта будут следовать внутренним версиям в одно и то же время, но с задержкой в один дельта-цикл при моделировании.
Во втором и последнем блоке параллельных операторов мы назначаем выходные флаги, сигнализирующие о полном/пустом состоянии кольцевого буфера. Мы основываем расчеты на RAM_DEPTH общий и на fill_count сигнал. Глубина оперативной памяти — это константа, которая не изменится. Поэтому флаги будут меняться только в результате обновленного счетчика заполнения.
Обновление указателя заголовка
Основная функция указателя головки состоит в том, чтобы увеличиваться каждый раз, когда сигнал разрешения записи поступает извне этого модуля. Мы делаем это, передавая head сигнал на ранее упомянутый incr процедура.
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
Наш код содержит дополнительный and full_i = '0' Заявление для защиты от перезаписи. Эту логику можно опустить, если вы уверены, что источник данных никогда не попытается выполнить запись в FIFO, пока он заполнен. Без этой защиты перезапись приведет к тому, что кольцевой буфер снова станет пустым.
Если указатель начала увеличивается при заполнении кольцевого буфера, заголовок будет указывать на тот же элемент, что и хвост. Таким образом, модуль «забудет» содержащиеся в нем данные, и заполнение FIFO окажется пустым.
Оценивая full_i сигнал перед увеличением указателя головы, он забудет только перезаписанное значение. Я думаю, что это решение лучше. Но в любом случае, если когда-либо произойдет перезапись, это свидетельствует о неисправности вне этого модуля.
Обновление хвостового указателя
Указатель хвоста увеличивается так же, как указатель начала, но read_en вход используется как триггер. Как и в случае с перезаписью, мы защищаем от перечтения, включив and empty_i = '0'. в логическом выражении.
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
Кроме того, мы пульсируем rd_valid сигнал при каждом действительном чтении. Считанные данные всегда действительны в тактовом цикле после rd_en утверждалось, если FIFO не был пуст. Зная это, в этом сигнале на самом деле нет необходимости, но мы включим его для удобства. rd_valid сигнал будет оптимизирован при синтезе, если он останется неподключенным при создании экземпляра модуля.
Вывод блока оперативной памяти
Чтобы заставить инструмент синтеза вывести блочную ОЗУ, мы должны объявить порты чтения и записи в синхронном процессе без сброса. Мы будем считывать и записывать в ОЗУ каждый такт и позволять управляющим сигналам управлять использованием этих данных.
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
Этот процесс не знает, когда произойдет следующая запись, но ему это и не нужно знать. Вместо этого мы просто постоянно пишем. Когда head сигнал увеличивается в результате записи, мы начинаем запись в следующий слот. Это эффективно зафиксирует записанное значение.
Обновление счетчика заполнения
fill_count сигнал используется для генерации сигналов заполнения и опустошения, которые, в свою очередь, используются для предотвращения перезаписи и чтения FIFO. Счетчик заполнения обновляется комбинационным процессом, который чувствителен к указателю начала и конца, но эти сигналы обновляются только по переднему фронту тактового сигнала. Таким образом, счетчик заполнения также изменится сразу после фронта часов.
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
Счетчик заполнения рассчитывается просто путем вычитания хвоста из головы. Если хвостовой индекс больше, чем головной, мы должны добавить значение RAM_DEPTH константа, чтобы получить правильное количество элементов, которые в настоящее время находятся в кольцевом буфере.
Полный код VHDL для кольцевого буфера FIFO
library ieee;
use ieee.std_logic_1164.all;
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
architecture rtl of ring_buffer is
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
begin
-- Copy internal signals to output
empty <= empty_i;
full <= full_i;
fill_count <= fill_count_i;
-- Set the flags
empty_i <= '1' when fill_count_i = 0 else '0';
empty_next <= '1' when fill_count_i <= 1 else '0';
full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0';
full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
-- Update the head pointer in write
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
-- Update the tail pointer on read and pulse valid
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
-- Write to and read from the RAM
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
-- Update the fill count
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
end architecture;
Приведенный выше код показывает полный код для кольцевого буфера FIFO. Вы можете заполнить форму ниже, чтобы файлы проекта ModelSim, а также испытательный стенд были отправлены вам по почте мгновенно.
Тестовый стенд
FIFO создается на простом тестовом стенде, чтобы продемонстрировать, как он работает. Вы можете загрузить исходный код тестового стенда вместе с проектом ModelSim, используя форму ниже.
Для общих входных данных установлены следующие значения:
- RAM_WIDTH:16
- RAM_DEPTH:256
Тестовый стенд сначала сбрасывает FIFO. Когда сброс отпускается, тестовый стенд записывает последовательные значения (1-255) в FIFO, пока он не заполнится. Наконец, FIFO очищается до завершения теста.
Мы можем видеть форму сигнала для полного запуска тестового стенда на изображении ниже. fill_count сигнал отображается как аналоговое значение в форме волны, чтобы лучше показать уровень заполнения FIFO.
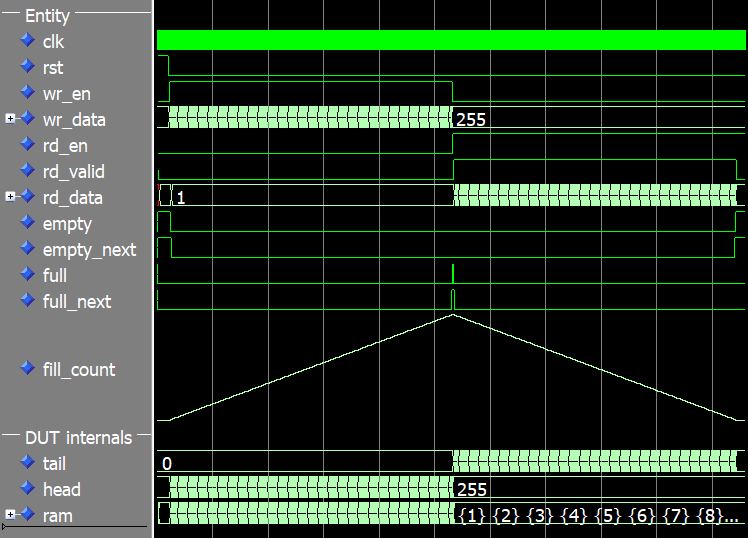
Голова, хвост и счетчик заполнения равны 0 в начале симуляции. В точке, где full сигнал установлен, заголовок имеет значение 255, как и fill_count сигнал. Счетчик заполнения увеличивается только до 255, хотя у нас есть глубина ОЗУ 256. Это потому, что мы используем оставить один открытым способ различать заполненные и пустые файлы, как мы обсуждали ранее в этой статье.
В поворотный момент, когда мы перестаем записывать в FIFO и начинаем читать из него, значение заголовка замораживается, а счетчик хвоста и заполнения начинает уменьшаться. Наконец, в конце симуляции, когда FIFO пуст, и голова, и хвост имеют значение 255, а счетчик заполнения равен 0.
Этот испытательный стенд нельзя считать пригодным ни для чего, кроме демонстрационных целей. У него нет никакого поведения или логики самопроверки, чтобы убедиться, что вывод из FIFO вообще правильный.
Мы будем использовать этот модуль в статье на следующей неделе, когда будем углубляться в тему ограниченной случайной проверки. . Это стратегия тестирования, отличная от более часто используемых направленных тестов. Короче говоря, испытательный стенд будет выполнять случайные взаимодействия с ИУ (тестируемым устройством), и поведение ИУ должно быть проверено отдельным процессом испытательного стенда. Наконец, когда произойдет ряд предопределенных событий, тест будет завершен.
Нажмите здесь, чтобы прочитать следующую запись в блоге:
Ограниченная случайная проверка
Синтез в Vivado
Я синтезировал кольцевой буфер в Xilinx Vivado, потому что это самый популярный инструмент реализации FPGA. Однако он должен работать на всех архитектурах FPGA с двухпортовым блочным ОЗУ.
Мы должны присвоить некоторые значения общим входам, чтобы иметь возможность реализовать кольцевой буфер как автономный модуль. Это делается в Vivado с помощью Настройки → Общие → Общие параметры/параметры меню, как показано на изображении ниже.
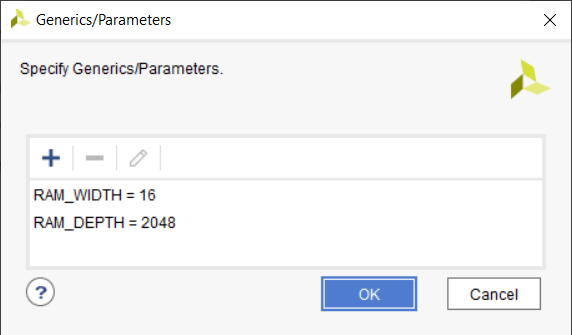
Значение для RAM_WIDTH установлено на 16, что совпадает с симуляцией. Но я установил RAM_DEPTH до 2048, потому что это максимальная глубина примитива RAMB36E1 в архитектуре Xilinx Zynq, которую я выбрал. Мы могли бы выбрать меньшее значение, но при этом использовалось бы такое же количество блоков ОЗУ. Более высокое значение привело бы к использованию более одного блока ОЗУ.
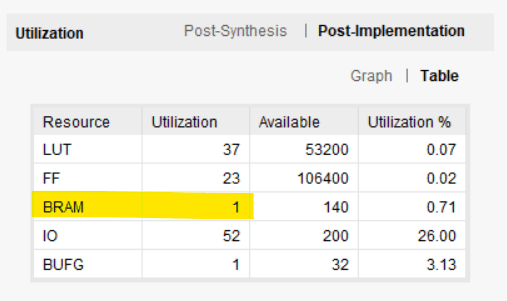
На изображении ниже показано использование ресурсов после внедрения, как сообщает Vivado. Наш кольцевой буфер действительно потреблял один блок оперативной памяти и несколько LUT и триггеров.
Отключение действительного сигнала
Вы можете спросить себя, не является ли задержка в один такт между rd_en и rd_valid сигнал действительно нужен. Ведь данные уже есть на rd_data когда мы утверждаем rd_en сигнал. Разве мы не можем просто использовать это значение и позволить кольцевому буферу перейти к следующему элементу в следующем такте, когда мы читаем из FIFO?

Строго говоря, нам не нужен valid сигнал. Я включил этот сигнал просто для удобства. Важнейшая часть заключается в том, что нам нужно дождаться такта после того, как мы утвердили rd_en сигнал, иначе эта оперативная память не успеет среагировать.
Блочное ОЗУ в ПЛИС — это полностью синхронные компоненты, им нужен фронт тактовой частоты как для чтения, так и для записи данных. Такты чтения и записи не обязательно должны исходить из одного и того же источника тактовых импульсов, но должны быть фронты тактовых импульсов. Кроме того, не может быть никакой логики между выходом ОЗУ и следующим регистром (триггеры). Это связано с тем, что регистр, который используется для синхронизации вывода ОЗУ, находится внутри блочного примитива ОЗУ.

На изображении выше показана временная диаграмма того, как значение распространяется от wr_data вводится в наш кольцевой буфер, через ОЗУ и, наконец, появляется на rd_data выход. Поскольку каждый сигнал дискретизируется по переднему фронту тактового сигнала, требуется три тактовых цикла с момента, когда мы начинаем управлять портом записи, до того, как он появится на порту чтения. И проходит дополнительный тактовый цикл, прежде чем принимающий модуль сможет использовать эти данные.
Уменьшение задержки
Есть способы смягчить эту проблему, но это происходит за счет дополнительных ресурсов, используемых в ПЛИС. Давайте проведем эксперимент, чтобы сократить задержку на один такт для порта чтения нашего кольцевого буфера. В фрагменте кода ниже мы изменили rd_data вывод из синхронного процесса в комбинационный процесс, чувствительный к ram и tail сигнал.
PROC_READ : process(ram, tail)
begin
rd_data <= ram(tail);
end process;
К сожалению, этот код нельзя сопоставить с блочной ОЗУ, поскольку между выходом ОЗУ и первым нисходящим регистром в rd_data может существовать комбинационная логика. сигнал.
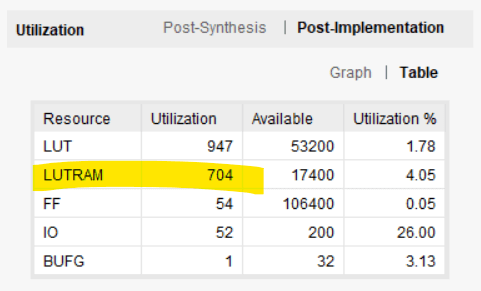
На изображении ниже показано использование ресурсов по данным Vivado. Блок RAM заменен на LUTRAM; форма распределенной оперативной памяти, реализованная в LUT. Использование LUT резко возросло с 37 до 947. Таблицы поиска и триггеры дороже, чем блочная RAM, и это главная причина, по которой у нас есть блочная RAM.
Существует множество способов реализации кольцевого буфера FIFO в блочной ОЗУ. Вы можете сэкономить дополнительный тактовый цикл, используя другой дизайн, но это будет стоить дополнительной вспомогательной логики. Для большинства приложений кольцевого буфера, представленного в этой статье, будет достаточно.
Обновление:
Как создать кольцевой буфер FIFO в блочной ОЗУ с помощью AXI ready/valid handshake
В следующем сообщении блога мы создадим улучшенный тестовый стенд для модуля кольцевого буфера, используя ограниченную случайную проверку. .
Нажмите здесь, чтобы прочитать следующую запись в блоге:
Ограниченная случайная проверка
VHDL
- Как создать список строк в VHDL
- Как создать управляемый Tcl тестовый стенд для модуля кодовой блокировки VHDL
- Как остановить симуляцию в тестовом стенде VHDL
- Как создать ШИМ-контроллер на VHDL
- Как генерировать случайные числа в VHDL
- Как создать самопроверяющийся тестовый стенд
- Как создать связанный список в VHDL
- Как использовать процедуру в процессе в VHDL
- Как использовать нечистую функцию в VHDL
- Как использовать функцию в VHDL