


Сеть прогнозирования метаматериала с резонатором с разделенным кольцом на основе глубокого обучения
Аннотация
Введение «метаматериалов» оказало глубокое влияние на несколько областей, включая электромагнетизм. Однако создание структуры метаматериала по запросу - все еще чрезвычайно трудоемкий процесс. Как эффективный метод машинного обучения, глубокое обучение широко использовалось для классификации и регрессии данных в последние годы и фактически показало хорошие характеристики обобщения. Мы создали глубокую нейронную сеть для проектирования по запросу. Если на входе требуется требуемая отражательная способность, параметры конструкции рассчитываются автоматически, а затем выводятся для достижения цели проектирования по запросу. Наша сеть достигла низких среднеквадратичных ошибок (MSE), со MSE 0,005 как для обучающего, так и для тестового набора. Результаты показывают, что, используя глубокое обучение для обучения данных, обученная модель может более точно направлять проектирование структуры, тем самым ускоряя процесс проектирования. По сравнению с традиционным процессом проектирования, использование глубокого обучения для управления проектированием метаматериалов позволяет достичь более быстрых, точных и удобных целей.
Введение
Нанооптика - междисциплинарный предмет нанотехнологий и оптики. В последние годы, постоянно проектируя структуры с различными субволновыми размерами, чтобы добиться особых взаимодействий с падающим светом, ученым удалось манипулировать определенными характеристиками пропускания света [1,2,3]. С тех пор, как были предложены метаматериалы, они привлекли внимание многих ученых в этой области, и одновременно связанные с ними теоретические исследования [4, 5], процессы [6, 7] и прикладные [8] исследования продвигаются с одинаковой скоростью. Реализованы многие специфические функции, включая голографическое отображение, идеальное поглощение [9] и плоские линзы [10]. Благодаря быстрому развитию терагерцовой технологии и ее уникальным характеристикам, в последние годы она также стала популярной темой исследований в области метаматериалов [11,12,13].
Хотя применение метаматериалов очень широко, традиционный метод проектирования требует от проектировщика многократного выполнения сложных численных расчетов проектируемой конструкции. Этот процесс требует огромных затрат времени и вычислительных ресурсов. Поэтому крайне необходимо найти новые способы упрощения или даже замены традиционных методов проектирования.
Как междисциплинарная область, машинное обучение охватывает многие дисциплины, включая науки о жизни, компьютерные науки и психологию, оно работает над использованием компьютеров для имитации и реализации процессов обучения человека с целью приобретения новых знаний или навыков. Основной принцип машинного обучения можно описать просто как использование компьютерных алгоритмов для получения корреляции между большим объемом данных или для прогнозирования правил для похожих данных и, наконец, достижения цели классификации или регрессии. До сих пор многие алгоритмы машинного обучения применялись для обозначения метаматериалов и достигли значительных результатов, включая генетические алгоритмы [14], алгоритмы линейной регрессии [15] и мелкие нейронные сети. По мере того, как структура становится все более сложной, а изменения в структуре - более разнообразными, для решения проблем потребуется больше времени. В то же время из-за высокой нелинейности проблем простые алгоритмы машинного обучения затрудняют получение точных прогнозов. Кроме того, чтобы спроектировать соответствующую структуру метаматериала для определенного электромагнитного эффекта, проектировщики должны попытаться выполнить сложные численные расчеты конструкции. Эти процессы потребуют огромного количества времени и вычислительных ресурсов.
Как один из самых выдающихся алгоритмов в области машинного обучения, глубокое обучение добилось всемирно известных достижений в различных смежных областях, таких как компьютерное зрение [16], извлечение признаков [17] и обработка естественного языка [18]. В то же время успехи в других областях, не связанных с компьютером, многочисленны, включая многие базовые дисциплины, такие как науки о жизни, химия [19] и физика [20] [21]. Поэтому применение глубокого обучения для проектирования метаматериалов также является горячим направлением исследований в настоящее время, и появилось много выдающихся работ [22,23,24].
В этой статье, вдохновленной глубоким обучением, сообщается об исследовании с использованием алгоритма машинного обучения, основанного на глубокой нейронной сети, для прогнозирования структуры резонатора с разъемным кольцом (SRR) для достижения цели проектирования по запросу. Кроме того, прямая сеть и обратная сеть инновационным образом обучаются отдельно, что не только может повысить точность сети, но также может обеспечить различные функции за счет гибкой комбинации. Результаты показывают, что метод может достичь MSE 0,0058 и 0,0055 на обучающем наборе и наборе проверки, соответственно, и демонстрирует хорошую надежность и обобщение. С обученной моделью, управляющей проектированием структур из метаматериалов, цикл проектирования может быть сокращен до дней или даже часов, и повышение эффективности очевидно. Кроме того, этот метод также обладает хорошей масштабируемостью и требует только изменения данных обучающего набора для разработки различных входных данных или различных структур по запросу.
Теория и метод
Построение модели COMSOL
Чтобы показать, что глубокое обучение может быть применено к обратному проектированию структур из метаматериалов, мы смоделировали трехслойную структуру SRR, состоящую из золотого кольца, кварцевого дна и золотого дна, чтобы наблюдать его электромагнитный отклик под действием падающий свет. Как показано на рис. 1, угол раскрытия θ золотого кольца внутренний радиус r кольца и шириной линии d кольца выбраны в качестве независимых переменных этой структуры. Когда луч линейно поляризованного света обычно входит в метаматериалы, кривые отражательной способности длины волны под различными структурами получаются путем изменения структурных переменных. Толщина кольца Au 30 нм, дна SiO 2 составляет 100 нм, а нижняя часть Au составляет 50 нм, а размер метаатомов составляет 200 нм на 200 нм.
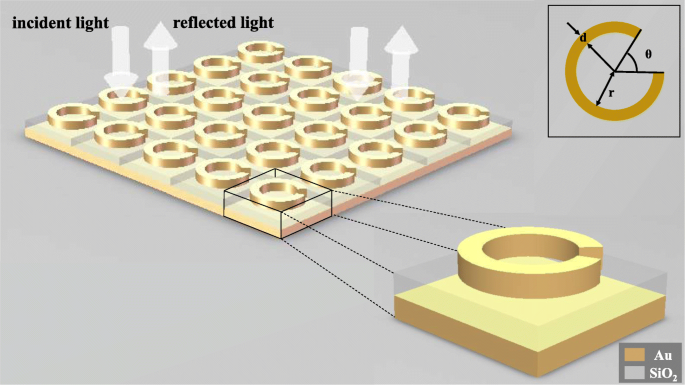
Принципиальная схема конструкции. Вся метаповерхность состоит из метаатомов, многократно расположенных в двух направлениях, и линейно поляризованный свет падает перпендикулярно метаповерхности. Каждый метаатом состоит из золотого кольца, нижней части из диоксида кремния и нижней части из золота в порядке сверху вниз. Самое верхнее золотое кольцо содержит три структурных параметра, а именно ширину линии d , угол раскрытия θ , а радиус внутреннего кольца r
Используйте COMSOL Multiphysics 5.4 [25] для моделирования, выберите трехмерное пространственное измерение, выберите оптику ≥ волновая оптика ≥ частотная область электромагнитных волн (ewfd) для физического поля и выберите область длин волн для исследования. Создайте указанную выше модель в геометрии. Материал каждой части и ее показатель преломления определяются по порядку в материале, а порты и периодические условия добавляются в частотной области электромагнитной волны.
Создание модели нейронной сети с глубоким обучением
Мы построили обратную сеть и прямую сеть для структуры метаматериала. Обратная сеть может прогнозировать структурные параметры SRR на основе данных двух наборов кривых отражательной способности от длины волны с разными направлениями поляризации. Прямая сеть может прогнозировать кривые отражательной способности длины волны в двух направлениях поляризации по заданным структурным параметрам. Функция обратной сети - это основная часть функции прогнозирования. Роль прямой сети заключается в проверке результатов прогнозирования обратной сети, чтобы наблюдать, соответствуют ли результаты прогнозирования требуемому электромагнитному отклику.
Используйте eclipse 2019 в качестве платформы разработки, python3.7 в качестве языка программирования и TensorFlow 1.12.0 в качестве среды разработки.
Две сети обучаются отдельно, чтобы на результаты обучения каждой сети не влияла ошибка другой сети, что, таким образом, обеспечивает соответствующую точность двух сетей.
Как показано на рис.2, еще одним преимуществом раздельного обучения двух сетей является то, что они могут использоваться для разных целей с помощью разных последовательностей соединений:(а) обратная сеть + прямая сеть, которая может использовать заданную кривую отражательной способности длины волны для расчета структурировать параметры, делать прогнозы и проверять, соответствуют ли результаты прогнозов потребностям, и (б) использование только прямой сети может упростить процесс расчета численного метода расчета и сократить время расчета.
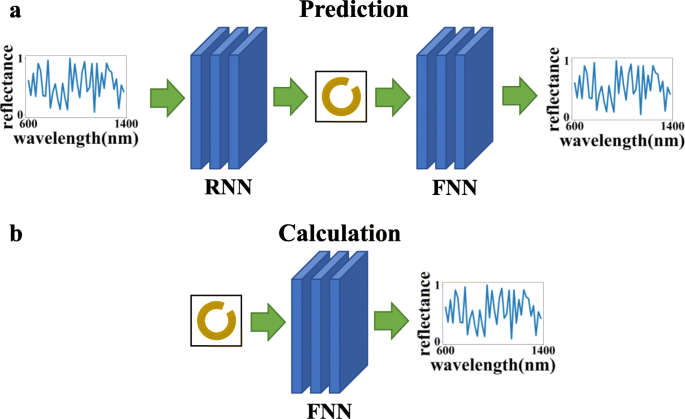
На этом рисунке FNN относится к прямой нейронной сети, а RNN относится к обратной нейронной сети. Верхний график ( a ) указывает, что две сети могут быть соединены для достижения эффекта прогнозирования и проверки, а нижний график ( b ) указывает, что для расчета оптического отклика можно использовать только сеть прямого отклика
Стоит отметить, что процесс ввода и получения результатов обученной модели методом глубокого обучения занимает чрезвычайно короткое время. И всякий раз, когда новые данные получаются посредством моделирования или эксперимента, модель можно использовать для дальнейшего обучения. Исследования показали, что с постоянным увеличением обучающих данных точность модели будет становиться все выше и выше, а производительность обобщения - все лучше и лучше [26].
Параметры структуры - это несколько наборов непрерывных собственных значений, которые относятся к задаче регрессии. В последние годы полностью связанные сети были в центре внимания сетей глубокого обучения по вопросам регрессии и показали такие характеристики, как высокая надежность, большая пропускная способность данных и низкая задержка. Внесение некоторых изменений в полностью подключенную сеть позволит сети лучше прогнозировать структуру.
Как показано на рис. 3b, прямая сеть представляет собой полностью подключенную сеть, в которой все узлы двух соседних уровней подключены друг к другу. Входные данные представляют собой структурный параметр, а выходные данные - кривую отражательной способности длины волны для двух направлений поляризации. Как показано на рис. 3a, обратная сеть состоит из слоя извлечения признаков (уровень FE) и полностью связанного уровня (уровень FC). Слой FE включает в себя два набора полностью связанных сетей, которые не связаны друг с другом, и обрабатывает кривые отражательной способности линейно поляризованного света в двух направлениях для извлечения некоторых характеристик входных данных. Слой FC изучит извлеченные объекты и выведет структурные параметры. Из-за характеристик высокой когезии и низкой связи между кривыми отражательной способности длины волны в различных состояниях поляризации разделение входов двух наборов данных поляризованного света в разных направлениях может предотвратить нарушение сети из-за стандартизации данных во время процесса извлечения данных. Прямая сеть не включает несколько наборов входных данных и не требует учета взаимных помех между данными, поэтому в ней нет уровня извлечения признаков.
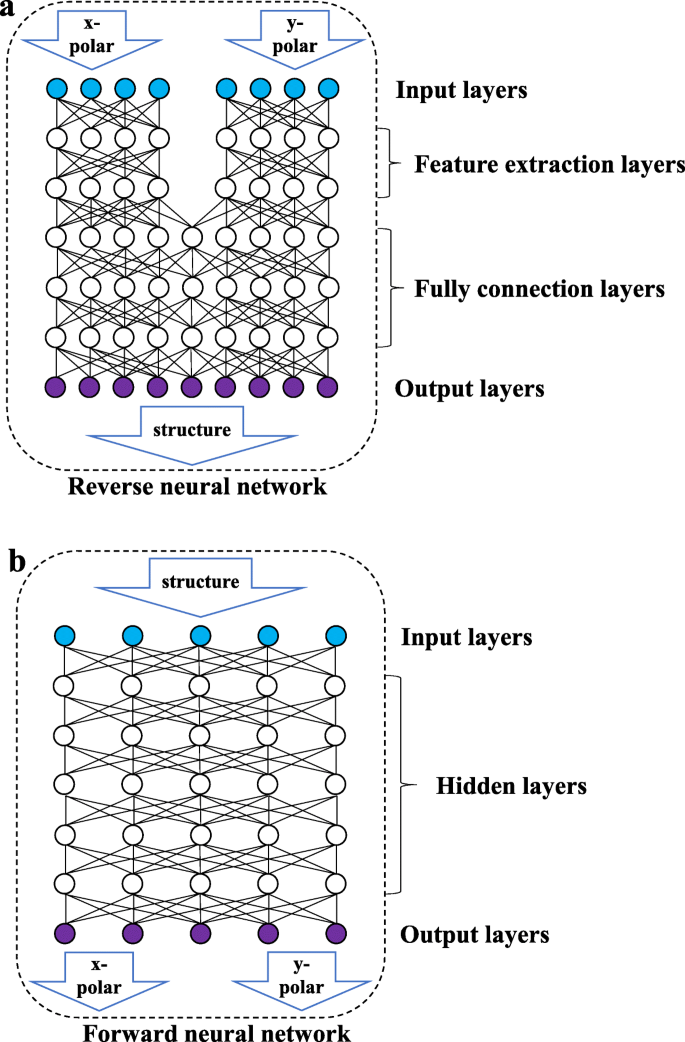
Принципиальная схема сетевой структуры. На приведенном выше рисунке показана обратная сеть. Обратная сеть состоит из входного слоя, слоя извлечения признаков, полностью связанного слоя и выходного слоя. На следующем рисунке показана прямая сеть, которая состоит из входного, скрытого и выходного уровней.
Чтобы определить оптимальную структуру сети, сети с разными структурами обучаются с использованием одного и того же набора данных. Как показано на рис. 4, после того, как данные прошли 50 эпох (когда все данные прошли полное обучение, это называется эпохой), MSE достигается прямой сетью с различными структурами. Как видно из левого изображения на рис. 4, когда прямая сеть содержит 5 скрытых уровней, каждый из которых содержит 100 узлов, наименьшая достигнутая MSE составляет около 0,0174, поэтому будет выбрана прямая сеть этой структуры.> 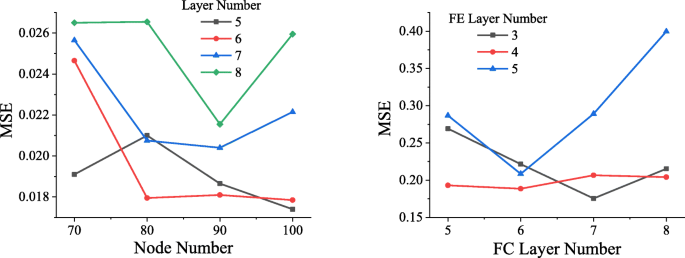
Сравнение сетевых структур. На рисунке слева горизонтальная ось представляет количество узлов в каждом слое, вертикальная ось представляет MSE, а черный, красный, синий и зеленый цвета представляют ситуацию, когда скрытый слой содержит 5, 6, 7 и 8 слоев соответственно. На рисунке справа горизонтальная ось указывает количество слоев в полностью подключенном слое, вертикальная ось указывает MSE, а черная, красная и синяя линии указывают ситуацию, когда слой FE включает 3, 4 и 5. соответственно
Точно так же были обучены разные сети обратных сетей, и объем обучения по-прежнему был установлен на 50 эпох. Результат показан на правом рисунке рис. 4. Когда количество уровней FC равно 7, а количество уровней FE равно 3, сеть достигает самой низкой MSE, которая составляет около 0,1756.
Мы обнаружили, что большее количество слоев сети вызовет явление градиентного взрыва, которое приведет к тому, что сеть не сможет сойтись, а потери будут бесконечными, поэтому они не указаны на рисунке.
Предварительная обработка данных
Чтобы обучить более надежную прямую сеть, данные отражения повторно разделяются, и они сшиваются с преломляющей способностью Au и SiO 2 соответствующие каждой частоте. Сортированные данные затем нормализуются и вводятся в прямую сеть, что может значительно повысить точность прямой сети.
Чтобы гарантировать, что данные с большими значениями не окажут большего влияния на сеть, чем данные с меньшими значениями, входные данные необходимо нормализовать, чтобы каждый столбец данных соответствовал стандартному нормальному распределению (среднее значение равно 0, дисперсия равна 1), а затем обработанные данные x можно выразить следующим образом:
$$ x =\ frac {\ left ({x} _0 \ hbox {-} \ mu \ right)} {\ sigma} $$ (1)В выражении x 0 исходные данные образца, μ среднее значение выборки и σ стандартное отклонение образца. Если входные данные не разделены повторно, отражательная способность будет искажена после нормализации, что снизит точность сети. Повторно разделенные данные не повлияют на их распределение из-за нормализации.
Метод нейронной сети
Принцип нейронной сети состоит в том, чтобы построить множество нейронов (узлов), имитируя работу и обучение человеческого мозга [27]. Нейроны связаны друг с другом, и выход регулируется путем регулировки веса соединения. Вывод j -й узел слоя можно выразить следующим образом:
$$ {y} _j =\ frac {\ sum \ limits_ {i =1} ^ nf \ left ({w} _i {x} _i + {b} _j \ right)} {n} $$ (2)е - функция активации, w я - вес соединения i предыдущего слоя й узел подключен к j й узел, x я является выводом i й узел предыдущего слоя, b j - член смещения этого узла, а n это количество узлов в предыдущем слое, подключенных к j й узел.
Выбор функции активации
Чтобы удовлетворить высокую нелинейность обратной задачи, функция ELU [28] используется как функция активации каждого слоя нейронов [28]. На выходе f ( x ) функции ELU можно представить в кусочном виде следующим образом:
$$ е (x) =\ left \ {\ begin {array} {c} x \\ {} \ alpha \ left ({e} ^ x-1 \ right) \ end {array} \ right. {\ displaystyle \ begin {array} {c}, \\ {}, \ end {array}} {\ displaystyle \ begin {array} {c} x \ ge 0 \\ {} x <0 \ end {array}} $$ (3)В этой функции x - исходный ввод, а значение параметра для α варьируется от 0 до 1.
Причина использования функции активации заключается в том, что функция активации изменяет способность нелинейного выражения каждого уровня сети, тем самым улучшая общую нелинейную подгоночную способность сети. Как показано на рис. 5, функция ELU сочетает в себе преимущества функций активации сигмоида и выпрямленного линейного блока (ReLU). Когда x <0, у него лучшее мягкое насыщение, что делает сеть более устойчивой к входным изменениям и шумам. Когда x > 0, насыщения нет, что помогает уменьшить исчезновение градиента сети. Функция, заключающаяся в том, что среднее значение ELU близко к 1, может облегчить настройку сети. Результат доказывает, что использование ELU в качестве функции активации глубокого обучения нейронной сети значительно повышает надежность сети.
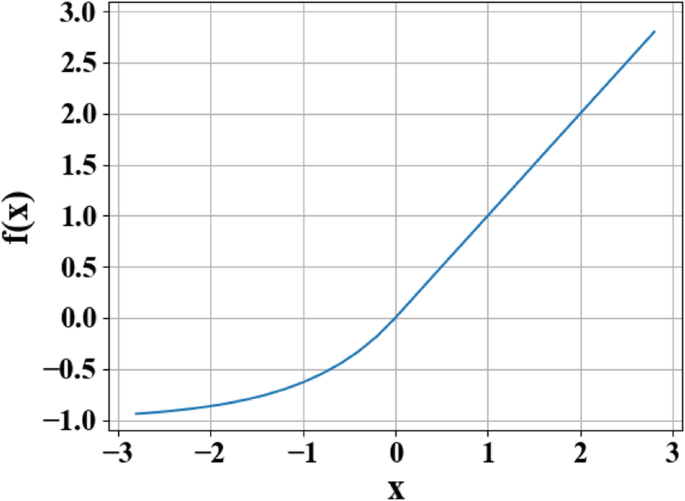
Кривая функции экспоненциальных линейных единиц (ELU). На рисунке x представляет исходный ввод, а f ( x ) представляет собой вывод функции
Схема инициализации веса
Метод инициализации сетевого веса каждого уровня определяет скорость подгонки сети и даже определяет, подходит ли сеть или нет. Инициализация масштабирования дисперсии основана на количестве входных данных на каждом уровне и извлекает веса из усеченного нормального распределения с центром на 0, так что дисперсия может быть уменьшена до определенного диапазона, а затем данные могут распространяться глубже по сети [29 ]. В этой сетевой структуре использование инициализации масштабирования дисперсии может значительно ускорить сходимость сети.
Решение для переобучения
Из-за недостатка данных сеть будет производить переоснащение. С уменьшением переобучения сеть может иметь хорошие характеристики обобщения данных за пределами обучающей выборки. Регуляризация L2 (также называемая убыванием веса в задачах регрессии) используется для обработки веса w . Регуляризованный вывод L можно выразить следующим образом:
$$ L ={L} _0 + \ frac {\ lambda} {2n} \ sum {w} ^ 2 $$ (4)В формуле. (4), L 0 представляет исходную функцию потерь, и на этой основе добавляется член регуляризации \ (\ frac {\ lambda} {2n} \ sum {w} ^ 2 \), где λ представляет собой коэффициент регуляризации, n пропускная способность данных и w вес. После добавления члена регуляризации значение веса w имеет тенденцию к уменьшению в целом, и появления чрезмерных значений можно избежать, поэтому w также называется ослаблением веса. Регуляризация L2 может снизить вес, чтобы избежать большого наклона подобранной кривой, тем самым эффективно уменьшая явление переобучения сети и помогая сходимости.
Исходя из этого, также используется метод отсева. Этот метод можно визуально рассматривать как «скрытие» определенного масштаба сетевых узлов для каждого обучения и сокрытие различных узлов во время каждого обучения для достижения цели обучения нескольких «частичных сетей». А посредством обучения большинство «частичных сетей» могут точно представлять цели, а результаты всех «частичных сетей» могут быть отсортированы для получения решения задач.
Использование упомянутых выше методов регуляризации и исключения L2 может не только эффективно уменьшить низкий уровень обобщения, вызванный недостаточным объемом данных, но также уменьшить влияние небольшого количества ошибочных данных в наборе данных на результаты обучения.
На этой сетевой структуре и наборе данных с dropout =0,2 и коэффициентом регуляризации L2 λ =0,0001, сеть может получить аналогичную точность на обучающем наборе и наборе тестов, тем самым достигнув высокой производительности обобщения.
Результат и обсуждение
После обучения наша прямая сеть может достичь высокой степени соответствия с MSE 0,0015, что показывает, что выходные данные очень похожи на результаты моделирования, как показано на рис. 6. Это также гарантирует, что при обучении обратной сети результаты обратной сети могут быть надежно проверены.
Результаты обучения прямой сети. Соответствующие структурные параметры: θ =50 °, r =60 нм и d =10 нм. На рисунке горизонтальная ось представляет длину волны падающего света, вертикальная ось представляет коэффициент отражения, красная линия представляет результат моделирования COMSOL, а синяя линия представляет результат обучения сети. На левом рисунке показана кривая отражательной способности, соответствующая x -поляризованный вход, а на правом рисунке показана кривая отражательной способности, соответствующая y -поляризованный вход
Наконец, мы сгенерируем две модели из изученной сети и соединим две модели для достижения функции прогнозирования.
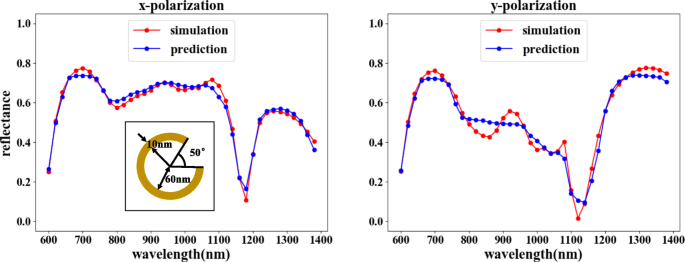
Функция прогнозирования может выбрать комбинацию, показанную на рис. 2а. Обратная сеть предсказывает соответствующую структуру в соответствии с требуемой кривой отражательной способности длины волны, а прямая сеть проверяет оптический отклик структуры. Как показано на рис. 7, сравнивая подтвержденную отражательную способность с входной отражательной способностью, характеристики отражения падающего света в двух направлениях поляризации в основном совпадают. Хотя незначительное рассогласование коэффициентов отражения наблюдается для определенных значений длины волны, общая тенденция согласования явно неопровержима, поскольку ошибки находятся в приемлемом диапазоне.
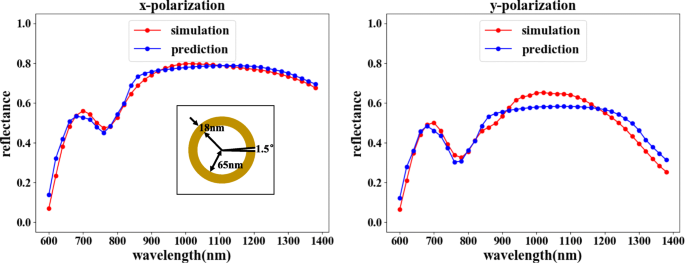
Обратная сеть, за которой следует прямая сеть, может достичь цели прогнозирования. На рисунке горизонтальная ось представляет длину волны падающего света, вертикальная ось представляет коэффициент отражения, красная линия представляет результат моделирования COMSOL, а синяя линия представляет результат обучения сети. На левом рисунке показана кривая отражательной способности, соответствующая x -поляризованный вход, а на правом рисунке показана кривая отражательной способности, соответствующая y -поляризованный вход. Прогнозируемые результаты для входной кривой коэффициента отражения от длины волны: θ =1,5 °, r =65 нм и d =18 нм
Заключение
В этой статье мы представили нашу спроектированную сеть глубокого обучения, способную создавать различные эффекты за счет использования гибких комбинаций сетевых конфигураций. Разработанная нами обратная сеть может прогнозировать требуемую структуру, используя входную кривую преломления длины волны, что может значительно сократить время, необходимое для решения обратной задачи, и удовлетворить различные потребности за счет использования гибких комбинаций. Результаты показывают, что сеть достигла более высокой точности прогнозов, что также означает, что проектирование по запросу может быть решено с помощью нашего метода. Использование глубокого обучения в качестве руководства при проектировании метаматериалов позволяет автоматически получать более точные структуры метаматериалов, что недостижимо с помощью традиционных методов проектирования.
Доступность данных и материалов
Дата получения рукописи из нашей сети моделирования, и мы не можем поделиться ею по личным причинам.
Сокращения
- ELU:
-
Экспоненциальные линейные единицы
- слой FC:
-
Полностью связанный слой
- слой FE:
-
Слой извлечения объектов
- FNN:
-
Прямая нейронная сеть
- MSE:
-
Среднеквадратичные ошибки
- ReLU:
-
Выпрямленный линейный блок
- RNN:
-
Обратная нейронная сеть
- SRR:
-
Резонатор с разъемным кольцом
Наноматериалы
- Использование FPGA для глубокого обучения
- Автомобильный процессор со встроенным ускорителем AI
- Распознавание цифр AI с помощью PiCamera
- Мобильный робот с функцией обхода препятствий на основе обзора
- Повышение производительности активов с помощью машинного обучения
- Обучение без учителя с искусственными нейронами
- WND сотрудничает с Sigfox, чтобы предоставить Великобритании сеть Интернета вещей
- Строковый метод Split() в Java:как разделить строку на примере
- Электрические свойства гибридных композитов на основе многослойных углеродных нанотрубок с графитовыми нан…
- Прогнозирование срока службы батареи с помощью машинного обучения