


Глубокое погружение в жизненный цикл науки о данных
С появлением больших данных современная информатика достигает новых возможностей и показателей вычислительной мощности. В настоящее время нередко можно найти приложения, которые создают наборы данных размером 100 терабайт и более, что считается большими данными.
Имея под рукой такие большие объемы информации, легко дезорганизоваться и тратить время на бесполезный контент. Это две причины, по которым очень важно следовать методологии, повышающей эффективность и результативность проекта больших данных.

Рисунок 1. Современная наука о данных работает с очень большими наборами данных, также известными как большие данные.
Жизненный цикл науки о данных предоставляет структуру, которая помогает определять, собирать, организовывать, оценивать и развертывать проекты больших данных. Это итеративный процесс, состоящий из серии шагов, упорядоченных в логической последовательности, что способствует обратной связи и повороту.
Как выглядит последовательность жизненного цикла? Ответ заключается в том, что не существует единой универсальной модели, которой следовали бы все. Многие компании, реализующие проекты с большими данными, адаптируют жизненный цикл науки о данных к своим бизнес-процессам, как правило, с большим количеством шагов. Несмотря на это, все многочисленные модели и технологические потоки имеют общие знаменатели. В этой статье будет использоваться модель процесса CRISP-DM, которая является одной из первых и наиболее популярных моделей жизненного цикла науки о данных.
Модель CRISP-DM
CRISP-DM означает межотраслевой стандартный процесс интеллектуального анализа данных. Впервые он был опубликован в 1999 г. ESPRIT, европейской программой по развитию исследований в области информационных технологий (ИТ). Модель CRISP-DM состоит из шести шагов или фаз, которые направляют проект больших данных. Он побуждает заинтересованные стороны задуматься о бизнесе, задавая важные вопросы о проблеме и отвечая на них.
Давайте подробно рассмотрим шесть этапов модели CRISP-DM.
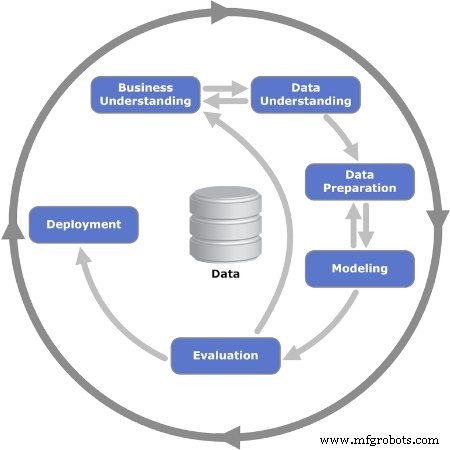
Рисунок 2 Показаны шесть итерационных фаз модели CRISP-DM. Изображение любезно предоставлено Кеннет Дженсен
Этап 1. Деловое понимание
Первый этап состоит из нескольких задач, которые определяют проблему и ставят цели. Это когда цели проекта ставятся с упором на бизнес или, другими словами, на клиента. Обычно команда, собранная для работы над проектом больших данных, должна предоставить решение заказчику, которым может быть другое подразделение или подразделение компании.
После того, как бизнес-потребность или проблема установлены, следующим шагом будет определение критериев успеха. Это могут быть ключевые показатели эффективности (KPI) или соглашения об уровне обслуживания (SLA), которые предоставляют объективные средства для оценки прогресса и завершения.
Затем необходимо проанализировать бизнес-ситуацию, чтобы определить риски, планы отката, меры на случай непредвиденных обстоятельств и, что более важно, доступность ресурсов. Представлен план проекта, включая ресурсы для основных этапов.
Этап 2. Анализ данных
После того, как основные принципы были установлены на предыдущем этапе, пора сосредоточиться на данных. Этот этап начинается с первоначального определения того, какие данные считаются необходимыми, а затем документируется некоторая конкретная информация о них:где их найти, тип данных, формат, отношения между различными полями данных и т. Д.
Когда первая документация готова, следующим шагом будет выполнение первого цикла сбора данных. Это дает полезный снимок того, как формируется структура. Затем этот снимок информации оценивается на предмет качества.
Этап 3. Подготовка данных
Третья фаза усиливает предыдущую фазу и подготавливает набор данных для моделирования. Поля данных из первой коллекции подвергаются дальнейшей обработке, и любая информация, которая считается ненужной, удаляется из набора:это называется очисткой данных.
Кроме того, может потребоваться получение определенной информации из другой доступной информации; в других случаях их необходимо комбинировать. Другими словами, данные необходимо обработать, чтобы получить окончательный формат.
Этап 4. Моделирование
Самая важная задача на этом этапе - выбрать алгоритм обработки собранных данных. В этом контексте алгоритм - это набор шагов последовательности и правил, запрограммированных в компьютерном программном обеспечении, разработанном для проектов с большими данными.
Можно использовать множество алгоритмов:примеры линейной регрессии, деревья решений и опорные векторные машины. Выбор правильного алгоритма для решения проблемы требует навыков, которыми обладают опытные специалисты по данным.
Рисунок 3 Линейная регрессия - это один из типов алгоритмов, используемых при моделировании больших данных.
Следующим шагом является кодирование алгоритма в программном приложении. Это также когда планируется этап тестирования, который состоит из выделения определенных наборов данных для тестирования и проверки.
Этап 5. Оценка
Иногда бывает сложно выбрать алгоритм с самого начала. Когда это происходит, ученые выполняют несколько алгоритмов и анализируют результаты, чтобы прийти к окончательному решению. По завершении этапа тестирования результаты проверяются на полноту и точность.
Что еще более важно, это возможность оценить, приводят ли результаты к решению. В итеративной модели это критически важный перекресток, на котором можно запустить основные последовательности итераций или принять решение о переходе к финальной фазе.
Этап 6. Развертывание
Это когда проект переходит из среды тестирования в рабочую среду. Планирование графика и стратегии развертывания очень важно для снижения рисков и потенциального простоя системы.
Несмотря на то, что диаграмма модели предполагает, что это конец проекта, есть еще множество шагов, которые необходимо предпринять после:мониторинг и обслуживание. Мониторинг - это период пристального наблюдения, также известный как гипервизор, сразу после ввода в эксплуатацию. Сопровождение - это полупостоянный процесс поддержки и обновления внедренного решения.
Большие данные называются так не просто так:необходимо проанализировать огромное количество данных. Внедрение одной из моделей жизненного цикла науки о данных помогает решить, какую информацию стоит хранить и использовать в таких процессах, как профилактическое обслуживание.
Интернет вещей
- Помимо смартфона:преобразование данных в звук
- Аутсорсинг ИИ и глубокое обучение в сфере здравоохранения - существует ли угроза для конфиденциальности данн…
- Обслуживание в цифровом мире
- Оптимизация жизненного цикла SIM-карты
- Демократизация Интернета вещей
- Максимизация ценности данных IoT
- Передача науки о данных в руки экспертов в предметной области для получения более ценной информации
- Почему прямое подключение является следующим этапом промышленного Интернета вещей
- Значение аналогового измерения
- Таблица, данные, лежащие в основе информации