


Исследователи показывают чип ИИ с тренировкой с пониженной точностью
На ISSCC IBM Research представила тестовую микросхему, которая представляет собой аппаратное воплощение многолетней работы над низкоточными алгоритмами обучения ИИ и логического вывода. 7-нм чип поддерживает 16-битное и 8-битное обучение, а также 4-битный и 2-битный логический вывод (32-битное или 16-битное обучение и 8-битный логический вывод являются сегодня отраслевым стандартом).
Снижение точности может сократить количество вычислений и мощности, необходимых для вычислений AI, но у IBM есть несколько других архитектурных хитростей, которые также помогают повысить эффективность. Задача состоит в том, чтобы снизить точность без отрицательного влияния на результат вычислений, над чем IBM работает уже несколько лет на уровне алгоритмов.
Центр оборудования искусственного интеллекта IBM был создан в 2019 году для поддержки цели компании по увеличению производительности вычислений искусственного интеллекта в 2,5 раза в год с амбициозной общей целью повышения эффективности производительности в 1000 раз (FLOPS / Вт) к 2029 году. размер моделей ИИ и объем вычислений, необходимых для их обучения, быстро растут. В частности, модели обработки естественного языка (NLP) теперь превратились в чудовищ с триллионами параметров, и углеродный след, который сопровождает обучение этих чудовищ, не остался незамеченным.
Этот последний тестовый чип от IBM Research показывает прогресс, достигнутый IBM. Для 8-битного обучения 4-ядерный чип способен выполнять 25,6 терафлопс, в то время как производительность логического вывода составляет 102,4 терафлопс для 4-битных целочисленных вычислений (эти цифры приведены для тактовой частоты 1,6 ГГц и напряжения питания 0,75 В). Снижение тактовой частоты до 1 ГГц и напряжения питания до 0,55 В повышает энергоэффективность до 3,5 терафлопс / Вт (FP8) или 16,5 терафлопс / Вт (INT4).
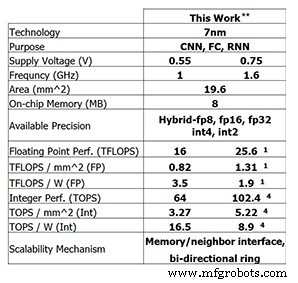
Производительность тестового чипа IBM Research (Изображение:IBM Research) ** Заявленная производительность при разреженности 0%. (1) FP8. (4) INT4.
Тренировка с низкой точностью
Этот результат основан на многолетней алгоритмической работе над методами обучения и логического вывода с низкой точностью. Этот чип является первым, кто поддерживает специальный 8-битный гибридный формат с плавающей запятой IBM (hybrid FP8), который был впервые представлен на NeurIPS 2019. Этот новый формат был разработан специально для 8-битного обучения, что вдвое сокращает объем вычислений, необходимых для 16-битного обучение, без отрицательного влияния на результаты (подробнее о числовых форматах для обработки AI здесь).
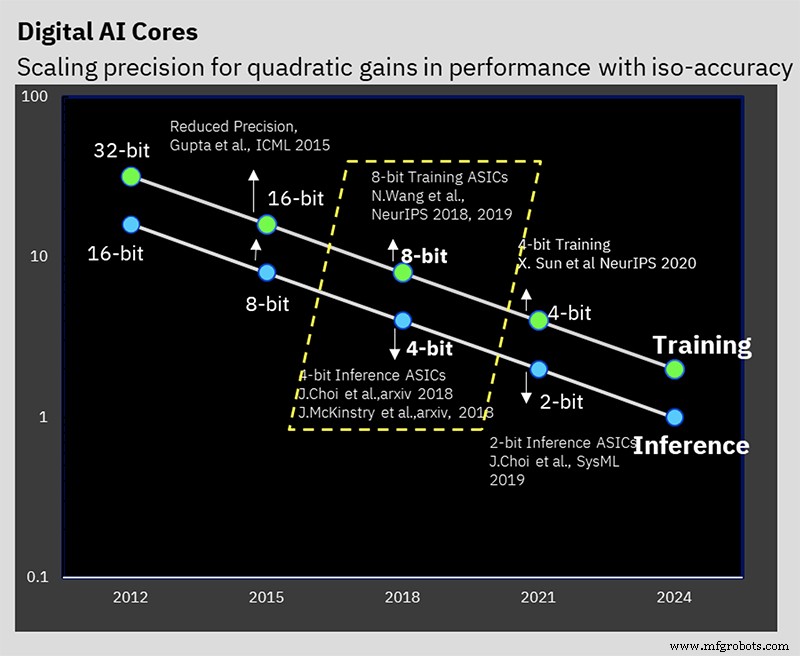
IBM Research работает над решением проблемы сохранения точности при одновременном снижении точности (Изображение:IBM)
«В ходе наших различных исследований на протяжении многих лет мы узнали, что обучение с низкой точностью очень сложно, но вы можете пройти 8-битное обучение, если у вас есть правильные числовые форматы», - сказал Кайлаш Гопалакришнан, научный сотрудник IBM и старший менеджер по архитектуре ускорителей. и машинное обучение в IBM Research сообщили EE Times . «Понимание правильных числовых форматов и их использование в правильных тензорах при глубоком обучении было важной частью этого».
Гибридный FP8 на самом деле представляет собой комбинацию двух разных форматов. Один формат используется для весов и активаций в прямом проходе глубокого обучения, а другой - в обратном. В выводе используется только прямой проход, тогда как для обучения требуются как прямая, так и обратная фазы.
«Мы узнали, что вам нужно больше верности, большей точности с точки зрения представления весов и активаций при прямом проходе глубокого обучения», - сказал Гопалакришнан. «С другой стороны [обратная фаза], градиенты имеют высокий динамический диапазон, и именно здесь мы осознаем необходимость иметь [большую] экспоненту ... это компромисс между тем, как некоторые тензоры в глубоком обучении нуждаются в большая точность, более точное представление, в то время как другим тензорам нужен более широкий динамический диапазон. Так зародился гибридный формат FP8, который мы представили в конце 2019 года и который теперь переведен на аппаратное обеспечение ».
В ходе работы IBM было установлено, что лучший способ разделить 8 бит между показателем степени и мантиссой - это 1-4-3 (один знаковый бит, четырехбитный показатель степени и трехбитовая мантисса) для прямой фазы с альтернативным 5- версия битовой экспоненты для обратной фазы, которая дает динамический диапазон 2 32 . Оборудование с гибридной FP8 поддерживает оба этих формата.
Иерархическое накопление
Нововведение, которое исследователи называют «иерархическим накоплением», позволяет уменьшать точность накопления наряду с весами и активациями. Типичные схемы обучения FP16 накапливаются в 32-битной арифметике для сохранения точности, но 8-битные обучающие схемы IBM могут накапливаться в FP16. Сохранение накопления в FP32 в первую очередь ограничило бы преимущества, полученные от перехода на FP8.
«В арифметике с плавающей запятой происходит следующее:если вы складываете вместе большой набор чисел, скажем, это вектор длиной 10 000, и вы складываете все это вместе, точность самого представления с плавающей запятой начинает ограничивать точность вашего сумма, - объяснил Гопалакришнан. «Мы пришли к выводу, что лучший способ сделать это - не выполнять сложение последовательно, а мы склонны разбивать долгое накопление на группы, которые мы называем порциями. А затем мы складываем блоки друг с другом, и это сводит к минимуму вероятность возникновения таких ошибок ».
Вывод с низкой точностью
Сегодня в большинстве выводов ИИ используется 8-битный целочисленный формат (INT8). Работа IBM показала, что 4-битное целое число - это новейшее достижение с точки зрения того, насколько низкая точность может быть достигнута без потери значительной точности прогнозирования. После квантования (процесса преобразования модели в числа с более низкой точностью) выполняется обучение с учетом квантования. По сути, это схема повторного обучения, которая уменьшает любые ошибки, возникающие в результате квантования. Такое повторное обучение может минимизировать потерю точности; IBM может «легко» выполнить квантование в 4-битные целые числа с потерей точности всего на полпроцента, что, по словам Гопалакришнана, «очень приемлемо» для большинства приложений.
Кольцо на чипе
Помимо упора на арифметику с низкой точностью, есть и другие аппаратные инновации, которые способствуют повышению эффективности чипа.
Один из них - это внутрикристальная кольцевая связь, сеть на кристалле, оптимизированная для глубокого обучения, которая позволяет каждому из ядер передавать многоадресные данные другим. Многоадресная коммуникация имеет решающее значение для глубокого обучения, поскольку ядра должны разделять веса и передавать результаты другим ядрам. Это также позволяет передавать данные, загруженные из внешней памяти, на несколько ядер. Это сокращает количество операций чтения памяти и общий объем отправляемых данных, сводя к минимуму требуемую полосу пропускания памяти.
«Мы поняли, что можем запускать ядра быстрее, чем кольца, потому что кольца включают в себя множество длинных проводов», - сказал Анкур Агравал, научный сотрудник IBM Research в области машинного обучения и архитектуры ускорителей. «Мы отделили частоту работы кольца от частоты работы ядер… что позволяет нам независимо оптимизировать производительность кольца по отношению к ядрам».
Управление питанием
Еще одним нововведением IBM было введение схемы масштабирования частоты для максимальной эффективности.
«Рабочие нагрузки глубокого обучения немного особенные, потому что даже на этапе компиляции вы знаете, с какими этапами вычислений вы столкнетесь в этой очень большой рабочей нагрузке», - сказал Агравал. «Мы можем выполнить некоторую предварительную настройку, чтобы выяснить, как будет выглядеть профиль мощности в различных частях расчета».
Профиль мощности глубокого обучения обычно имеет большие пики (для ресурсоемких операций, таких как свертка) и спады (возможно, для функций активации).
Схема IBM устанавливает начальное рабочее напряжение и частоту микросхемы довольно агрессивно, так что даже для режимов с наименьшим энергопотреблением микросхема почти достигла предела своей мощности. Затем, когда требуется больше мощности, рабочая частота снижается.
«Конечный результат - это микросхема, которая работает почти с максимальной мощностью на протяжении всего вычисления, даже на разных фазах», - пояснил Агравал. «В целом, не имея этих фаз низкого энергопотребления, вы можете делать все быстрее. Вы превратили любое снижение энергопотребления в прирост производительности, сохранив энергопотребление почти на уровне пикового энергопотребления на всех этапах работы ».
Масштабирование напряжения не используется, потому что это сложнее сделать "на лету"; время, необходимое для стабилизации при новом напряжении, слишком велико для вычислений с глубоким обучением. Поэтому IBM обычно предпочитает запускать микросхему при минимально возможном напряжении питания для этого технологического узла.
Тестовый чип
Тестовая микросхема IBM имеет четыре ядра, отчасти для того, чтобы можно было протестировать все различные функции. Гопалакришнан описал, как размер ядра сознательно выбирается как оптимальный; архитектуру из тысяч крошечных ядер сложно соединить вместе, в то время как разделение проблемы между большими ядрами также может быть затруднительным. Это промежуточное ядро было разработано для удовлетворения потребностей IBM и ее партнеров в AI Hardware Center, найдя золотую середину с точки зрения размера.
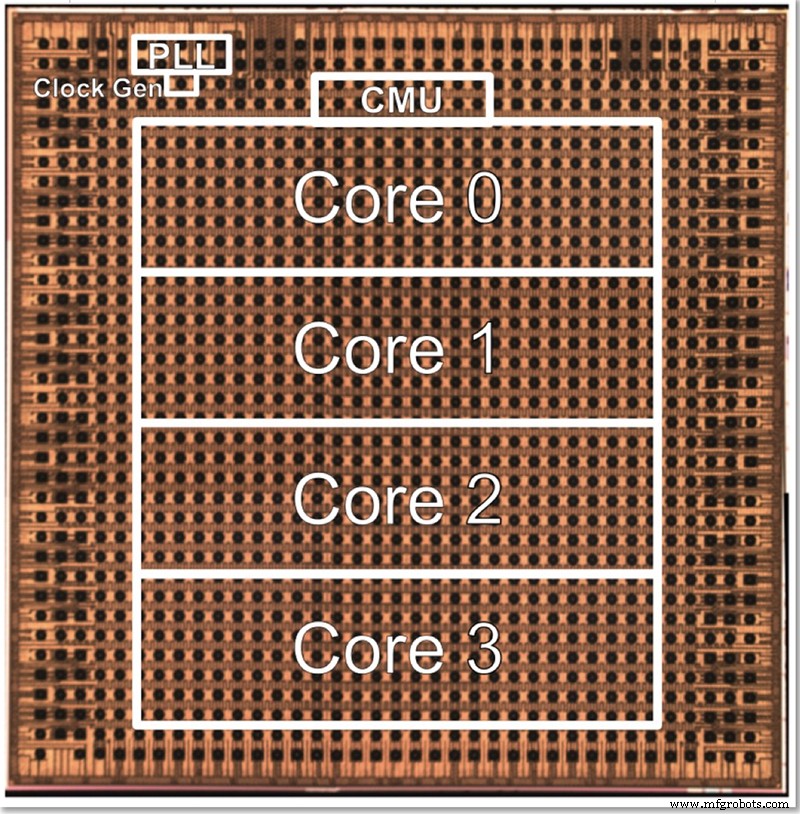
Фотография кристалла для 4-ядерного тестового чипа низкой точности IBM (Изображение:IBM)
Архитектуру можно масштабировать в большую или меньшую сторону, изменяя количество ядер. В конце концов, Гопалакришнан воображает, что 1-2 ядра чипа будут подходить для периферийных устройств, в то время как чипы с 32-64 ядрами могут работать в центре обработки данных. По его словам, тот факт, что он поддерживает несколько форматов (FP16, гибридный FP8, INT4 и INT2), также делает его достаточно универсальным для большинства приложений.
«Разные [прикладные] области будут иметь разные требования к энергоэффективности, точности и так далее, и тому подобное», - сказал он. «Наш швейцарский армейский нож точности, каждый из которых оптимизирован индивидуально, позволяет нам использовать эти ядра в различных областях, не отказываясь от какой-либо энергоэффективности в этом процессе».
Помимо аппаратного обеспечения, IBM Research также разработала стек инструментов (Deep Tools), компилятор которого обеспечивает высокую степень использования микросхемы (60-90%).
EE Times Предыдущее интервью с IBM Research показало, что микросхемы для обучения ИИ и логического вывода с низкой точностью, основанные на этой архитектуре, должны появиться на рынке примерно через два года.
>> Эта статья была первоначально опубликована на наш дочерний сайт EE Times.
Связанное содержание:
- Чипы AI поддерживают точность за счет сокращения модели.
- Обучение ИИ-моделей на передовой.
- ИИ на пороге гонок.
- Edge AI бросает вызов технологии памяти
- Инженерная группа стремится вывести ИИ мощностью 1 мВт на пределе возможностей.
- Применение нейронных сетей для небольших задач
- Исследование AI IC исследует альтернативные архитектуры
Чтобы получить больше информации о Embedded, подпишитесь на еженедельную рассылку Embedded по электронной почте.
Встроенный
- Проектирование с помощью сети Bluetooth:чип или модуль?
- Исследователи создают крошечный тег идентификации аутентификации
- Работа с сокращенным обслуживающим персоналом
- Альянс Rockwell с колледжем Миннесоты расширяет доступ к обучению автоматизации
- Исследователи показывают, как использовать недостатки безопасности Bluetooth Classic
- Как IBM Watson поддерживает любой другой бизнес с помощью ИИ
- Повысьте эффективность своих маркетинговых усилий, чтобы они работали с точностью агентств
- Повысьте эффективность своих маркетинговых усилий с точностью агентств
- IBM:активное обеспечение надежности и безопасности с помощью EAM
- Создание превосходных гидравлических систем с помощью прецизионной обработки