


Python RegEx:re.match(), re.search(), re.findall() с примером
Что такое регулярное выражение в Python?
Регулярное выражение (RE) в языке программирования — это специальная текстовая строка, используемая для описания шаблона поиска. Это чрезвычайно полезно для извлечения информации из текста, такого как код, файлы, журналы, электронные таблицы или даже документы.
При использовании регулярных выражений Python в первую очередь следует признать, что все, по сути, является символом, и мы пишем шаблоны для соответствия определенной последовательности символов, также называемой строкой. Ascii или латинские буквы — это те, которые есть на вашей клавиатуре, а Unicode используется для соответствия иностранному тексту. Он включает в себя цифры и знаки препинания, а также все специальные символы, такие как $#@!% и т. д.
В этом руководстве по Python RegEx мы изучим-
- Синтаксис регулярных выражений
- Пример выражения w+ и ^
- Пример выражения \s в функции re.split
- Использование методов регулярных выражений
- Использование re.match()
- Поиск шаблона в тексте (re.search())
- Использование re.findall для текста
- Флаги Python
- Пример re.M или многострочных флагов
Например, регулярное выражение Python может указать программе искать определенный текст в строке, а затем соответствующим образом распечатать результат. Выражение может включать
- Сопоставление текста
- Повторение
- Разветвление
- Шаблон-композиция и т. д.
Регулярное выражение или RegEx в Python обозначается как RE (RE, регулярные выражения или шаблон регулярных выражений), которые импортируются через модуль re. . Python поддерживает регулярные выражения через библиотеки. RegEx в Python поддерживает различные вещи, такие как модификаторы, идентификаторы и пробельные символы. .
| Идентификаторы | Модификаторы | Пробелы | Требуется побег |
|---|---|---|---|
| \d=любое число (цифра) | \d представляет цифру. Пример:\d{1,5} будет объявлена цифра между 1,5, например 424 444 545 и т. д. | \n =новая строка | <тд>. + * ? [] $ ^ () {} | \|
| \D=все, кроме числа (не цифры) | + =соответствует 1 или более | \s=пробел | <тд>|
| \s =пробел (табуляция, пробел, новая строка и т. д.) | <тд>? =соответствует 0 или 1 \t =вкладка | <тд>||
| \S=что угодно, кроме пробела | * =0 или больше | \e =escape | <тд>|
| \w =буквы ( Соответствует буквенно-цифровому символу, включая «_») | $ соответствует концу строки | \r =возврат каретки | <тд>|
| \W =все, кроме букв ( Соответствует небуквенно-цифровому символу, кроме «_») | ^ соответствует началу строки | \f=подача формы | <тд>|
| . =все, кроме букв (точек) | <тд>| соответствует или или x/y <тд>—————— <тд>|||
| \b =любой символ, кроме новой строки | [] =диапазон или «дисперсия» | —————- | <тд>|
| \. | {x} =это количество предшествующего кода | <тд>—————— <тд>
Синтаксис регулярных выражений (RE)
import re
- модуль «re», входящий в состав Python, в основном используется для поиска и обработки строк
- Также часто используется для очистки веб-страницы (извлечение большого объема данных с веб-сайтов).
Мы начнем изучение выражений с этого простого упражнения, используя выражения (w+) и (^).
Пример выражения w+ и ^
- «^»: Это выражение соответствует началу строки
- "ж+ “:это выражение соответствует буквенно-цифровому символу в строке.
Здесь мы увидим пример Python RegEx того, как мы можем использовать выражения w+ и ^ в нашем коде. Мы рассмотрим функцию re.findall() в Python позже в этом руководстве, но пока сосредоточимся на выражениях \w+ и \^.
Например, для нашей строки «guru99, образование — это весело», если мы выполним код с w+ и ^, он даст вывод «guru99».
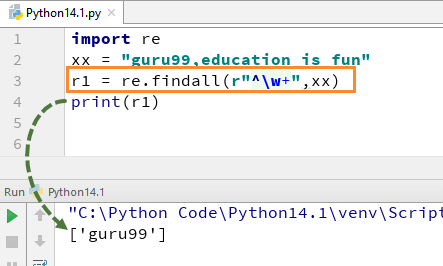
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
Помните, что если вы удалите знак + из w+, вывод изменится, и он даст только первый символ первой буквы, то есть [g]
Пример выражения \s в функции re.split
- «s»:это выражение используется для создания пробела в строке.
Чтобы понять, как работает это RegEx в Python, мы начнем с простого примера Python RegEx функции разделения. В примере мы разделили каждое слово с помощью функции «re.split» и в то же время мы использовали выражение \s, которое позволяет разобрать каждое слово в строке отдельно.
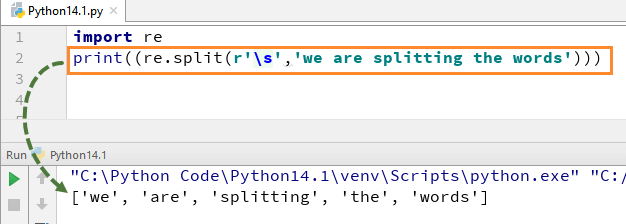
Когда вы выполните этот код, он выдаст вам результат [‘мы’, ‘есть’, ‘расщепление’, ‘то’, ‘слова’].
Теперь давайте посмотрим, что произойдет, если вы удалите «\» из s. В выводе нет алфавита 's', это потому, что мы удалили '\' из строки, и он оценивает «s» как обычный символ и, таким образом, разделяет слова везде, где он находит «s» в строке.
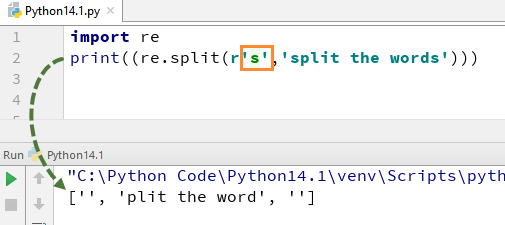
Точно так же существует ряд других регулярных выражений Python, которые вы можете использовать в Python различными способами, например \d,\D,$,\.,\b и т. д.
Вот полный код
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
Далее мы рассмотрим типы методов, которые используются с регулярными выражениями в Python.
Использование методов регулярных выражений
Пакет «re» предоставляет несколько методов для фактического выполнения запросов к входной строке. Мы увидим методы re в Python:
- re.match()
- поиск()
- re.findall()
Примечание :на основе регулярных выражений Python предлагает две различные примитивные операции. Метод match проверяет совпадение только в начале строки, тогда как поиск проверяет совпадение в любом месте строки.
re.match()
re.match() Функция re в Python будет искать шаблон регулярного выражения и возвращать первое вхождение. Метод Python RegEx Match проверяет совпадение только в начале строки. Итак, если совпадение найдено в первой строке, он возвращает объект совпадения. Но если совпадение найдено в какой-либо другой строке, функция Python RegEx Match возвращает значение null.
Например, рассмотрим следующий код функции Python re.match(). Выражение «w+» и «\W» будут соответствовать словам, начинающимся с буквы «g» и далее, все, что не начинается с «g», не идентифицируется. Чтобы проверить совпадение для каждого элемента в списке или строке, мы запускаем цикл for в этом примере Python re.match().
re.search():поиск шаблона в тексте
повторный поиск() функция будет искать шаблон регулярного выражения и возвращать первое вхождение. В отличие от Python re.match(), он проверяет все строки входной строки. Функция re.search() в Python возвращает объект соответствия, если шаблон найден, и значение null, если шаблон не найден
Как использовать поиск()?
Чтобы использовать функцию search(), вам нужно сначала импортировать модуль Python re, а затем выполнить код. Функция Python re.search() берет «шаблон» и «текст» для сканирования из нашей основной строки
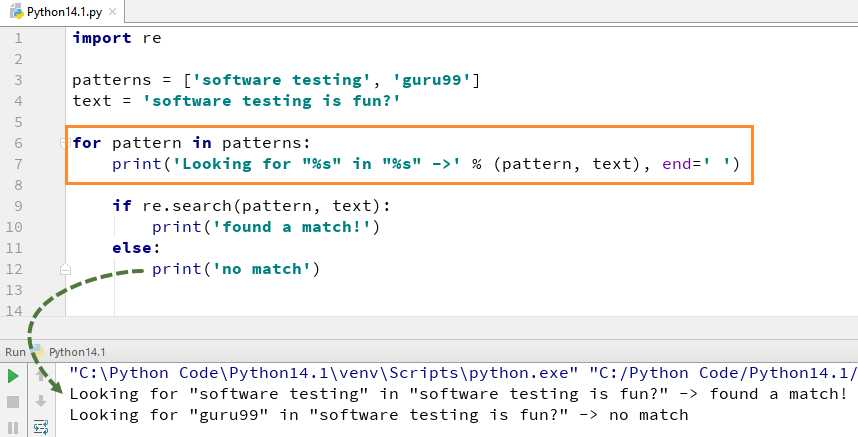
Например, здесь мы ищем две буквальные строки «Тестирование программного обеспечения» «guru99» в текстовой строке «Тестирование программного обеспечения — это весело». Для «тестирования программного обеспечения» мы нашли совпадение, поэтому он возвращает вывод примера Python re.search() как «найдено совпадение», в то время как для слова «guru99» мы не смогли найти в строке, поэтому он возвращает вывод как «Нет совпадения». ".
re.findall()
найти все() Модуль используется для поиска «всех» вхождений, соответствующих заданному шаблону. Напротив, модуль search() вернет только первое вхождение, соответствующее указанному шаблону. findall() перебирает все строки файла и возвращает все непересекающиеся совпадения шаблона за один шаг.
Как использовать re.findall() в Python?
Здесь у нас есть список адресов электронной почты, и мы хотим, чтобы все адреса электронной почты были извлечены из списка, мы используем метод re.findall() в Python. Он найдет все адреса электронной почты из списка.
Вот полный код примера re.findall()
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) Флаги Python
Многие методы регулярных выражений Python и функции регулярных выражений принимают необязательный аргумент, называемый флагами. Эти флаги могут изменить значение данного шаблона Python Regex. Чтобы понять это, мы рассмотрим один или два примера этих флагов.
Различные флаги, используемые в Python, включают
| Синтаксис флагов регулярных выражений | Что делает этот флаг |
|---|---|
| [re.M] | Заставить начало/конец учитывать каждую строку |
| [re.I] | Игнорирует регистр |
| [re.S] | Сделать [ . ] |
| [re.U] | Сделать { \w,\W,\b,\B} в соответствии с правилами Unicode |
| [re.L] | Заставить {\w,\W,\b,\B} следовать языковому стандарту |
| [re.X] | Разрешить комментарии в регулярном выражении |
Пример re.M или многострочных флагов
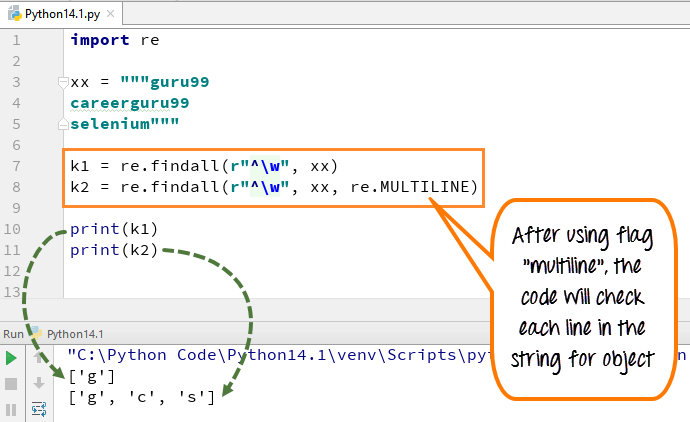
В многострочном режиме символ шаблона [^] соответствует первому символу строки и началу каждой строки (после каждой новой строки). В то время как выражение маленькая «w» используется для обозначения пробела символами. Когда вы запускаете код, первая переменная «k1» выводит только символ «g» для слова guru99, а когда вы добавляете многострочный флаг, она выводит первые символы всех элементов в строке.
Вот код
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- Мы объявили переменную xx для строки «guru99…. Карьерагуру99….селен»
- Запустите код, не используя многострочные флаги, он выдаст на выходе только «g» из строк
- Запустите код с флагом «многострочный», когда вы печатаете «k2», он выводит как «g», «c» и «s»
- Итак, разница, которую мы можем видеть после и до добавления нескольких строк в приведенном выше примере.
Кроме того, вы также можете использовать другие флаги Python, такие как re.U (Unicode), re.L (следить за локалью), re.X (разрешить комментарии) и т. д.
Пример Python 2
Приведенные выше коды являются примерами Python 3. Если вы хотите работать в Python 2, рассмотрите следующий код.
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
Обзор
Регулярное выражение в языке программирования — это специальная текстовая строка, используемая для описания шаблона поиска. Оно включает цифры и знаки препинания, а также все специальные символы, такие как $#@!% и т. д. Выражение может включать литерал
- Сопоставление текста
- Повторение
- Разветвление
- Шаблон-композиция и т. д.
В Python регулярное выражение обозначается как RE (RE, регулярные выражения или шаблон регулярного выражения), встроенные через модуль re Python.
- модуль «re», входящий в состав Python, в основном используется для поиска и обработки строк
- Также часто используется для очистки веб-страницы (извлечение большого объема данных с веб-сайтов).
- Методы регулярных выражений включают re.match(), re.search() и re.findall()
- Другие методы замены Python RegEx — это sub() и subn(), которые используются для замены совпадающих строк в re
- Флаги Python Многие методы регулярных выражений Python и функции регулярных выражений принимают необязательный аргумент под названием «Флаги».
- Эти флаги могут изменить значение заданного шаблона регулярного выражения.
- В методах регулярных выражений используются различные флаги Python:re.M, re.I, re.S и т. д.
Python
- Функция Python String strip() с ПРИМЕРОМ
- Количество строк Python() с ПРИМЕРАМИ
- Python String format() Объясните с ПРИМЕРАМИ
- Длина строки Python | Пример метода len()
- Метод Python String find() с примерами
- Функция Python round() с ПРИМЕРАМИ
- Функция Python map() с ПРИМЕРАМИ
- Python Timeit() с примерами
- Счетчик Python в коллекциях с примером
- Счетчик списка Python() с ПРИМЕРАМИ