


Что стоит за переходом на настраиваемые голосовые агенты?
Автоматизация - путь в будущее. Мы живем в эпоху настоящего, желая, чтобы на все ответили, достигли и получили все как можно быстрее. Несмотря на этот фундаментальный сдвиг, многие люди не принимают технологии. Для некоторых это связано с образом жизни:крупные компании могут быть слишком неуклюжими, чтобы преобразовать свою систему, а отдельные люди могут застрять на своем пути, не желая научиться пользоваться сенсорным экраном. Однако для большинства все сводится к данным - кому они принадлежат и как обеспечить их безопасность.
Решение? Это так же просто, как голос. Технология голосового управления может удовлетворить потребность в автоматизации, сохраняя при этом данные, и это то, что мы используем каждый день, независимо от места или платформы. Поскольку цифровая трансформация продолжает влиять на все больше и больше приложений, голосовые агенты - это ответ. Все больше компаний изучают возможность создания пользовательских голосовых платформ, встроенных в технологию, помимо популярных имен голосовых агентов, таких как Alexa и Google Voice. Уникальные голосовые платформы станут шагом вперед для компаний, которые хотят хранить и контролировать свои собственные данные.
За срывом стоит автоматизация
По мере того, как Интернет вещей (IoT) строится на основе искусственного интеллекта (AI), мы начинаем осознавать необходимость роста автоматизации. Когда Интернет вещей взаимодействует с ИИ, это улучшает контроль пользователей над огромными коллекциями интернет-устройств. Мы начинаем видеть, как возможности голоса расширяются в домашних условиях и за его пределами, взаимодействуя через такие платформы, как Google Voice, Amazon Alexa, Microsoft Cortana или уникальные платформы. В Harman Embedded Audio мы работали с каждым голосовым движком на планете и из первых рук понимаем широту рынка. Мы видим, что все больше компаний хотят создавать свои продукты с поддержкой голоса на своих собственных платформах голосовых помощников, чтобы иметь возможность контролировать данные.
Спрос на голосовое управление растет
Это одна из самых популярных тенденций в области аудио. Следующая важная вещь в пользовательском интерфейсе, теперь, когда такие функции, как сенсорные экраны, стали почти повсеместными, - это возможность разговаривать с устройством. Голос возглавляет новое поколение человеческого сотрудничества. Подумайте об обработке естественного языка на компьютере:голос обрабатывается таким образом, который соответствует тому, что машина предпочитает слышать, но если вы воспроизведете тот же обработанный файл, это будет механически и неестественно. То же самое и с разговором по телефону:он не производит такого же впечатления, как нахождение в комнате с кем-то. Вот где должна быть голосовая связь, и за ней последуют упомянутые выше уникальные голосовые платформы.
Как выглядят настраиваемые голосовые агенты и что участвует в сборке
Хотя каждое голосовое решение индивидуально, важно, чтобы все решения были достаточно гибкими, чтобы адаптироваться к необходимым требованиям их варианта использования, при этом собирая и защищая пользовательские данные. Для этого в сборке и интеграции любого голосового агента задействованы три основных элемента.
Первый - это алгоритмы дальнего поля. Используйте алгоритм высшего уровня, который улавливает голос в дальней зоне. В моей компании мы используем четыре ключевых программных алгоритма из алгоритмов Sonique:подавление шума, подавление акустического шума, разделение звука и формирование луча, а также обнаружение голосовой активности. Эти алгоритмы специально разработаны для использования в сочетании друг с другом для поддержки голосовых приложений.
Как они работают? Подумайте о сравнении умного динамика с человеком. DSP / SOC действует как «мозг» говорящего, микрофоны - это уши, а динамики - это рот. Для нас, когда кто-то называет наше имя, наш мозг нейтрализует все окружающие нас шумы и направляет всю свою энергию на это ключевое слово. Это то, чего мы добились в умном динамике:при обнаружении ключевого слова микрофон использует различные методы подавления шума и направляет всю свою мощность на источник. В процессе он подавляет большую часть шума вокруг себя. В акустической среде существует множество источников шума, таких как окружающий шум, местные динамики, система отопления, вентиляции и кондиционирования воздуха и др., Которые отражают обратную связь от динамика к микрофону. Каждый из этих источников шума требует индивидуального решения. Алгоритмы Sonique подавляют шумы и улавливают максимально четкую голосовую команду.
Кроме того, решающее значение имеет создание механизма определения ключевых слов (KWS). KWS определяет такие ключевые слова, как «Алекса» или «Окей, Google», чтобы начать разговор. Я работал почти со всеми поставщиками движков KWS, и каждый из них основан на глубоких нейронных сетях - настраиваемых, всегда прослушивающих, легких и встроенных. Важнейшим компонентом отличного качества обслуживания клиентов в удаленном голосовом приложении является коэффициент ложного принятия и ложного отклонения. В реальных условиях очень сложно поддерживать низкий уровень ложного отклонения, поскольку существует множество внешних шумов, таких как телевизоры, бытовая техника, душ и т. Д., Которые вызывают неполное отключение воспроизведения звука. Опытные разработчики настраивают механизм KWS, чтобы поддерживать низкий уровень ложного принятия.
Наконец, механизм автоматического распознавания речи (ASR) преобразует голос в текст. ASR состоит из основного инструмента преобразования речи в текст (STT) и инструмента распознавания естественного языка (NLU), который преобразует необработанный текст в данные. Механизм также требует навыков или, другими словами, базы знаний, на основе которой могут быть предоставлены ответы, а также инструмента обратного преобразования текста в речь. Мы разработали механизм ASR под названием E-NOVA, например, который предлагает многоплатформенную локальную интеграцию, поддерживает несколько языков (в настоящее время семь языков и их число растет) и включает обучаемые модели, поддержку интеграции сторонних производителей и идентификацию говорящего.
ASR - это первый шаг, который позволяет голосовым технологиям, таким как Amazon Alexa, OK Google, Cortana или клиенту, отвечать на запрос:«Какая погода в Лос-Анджелесе?» Это ключевая часть, которая распознает произносимые звуки, распознает их как слова, сопоставляет их со звуком на данном языке и в конечном итоге определяет слова, которые мы говорим. Благодаря движку ASR разговор кажется естественным. А с современными технологиями большинство механизмов ASR используют преимущества облачных вычислений. Благодаря дополнительным технологиям, таким как NLU, общение между людьми и компьютерами становится умнее и сложнее.
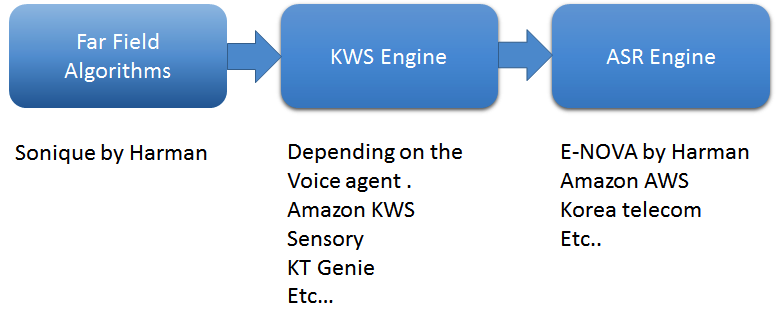
Рис. 1. Основной конвейер обработки в голосовых агентах. (Источник:Harman Embedded Audio)
Однако создание настраиваемых голосовых агентов сопряжено с множеством уникальных проблем. Понимание среды продукта - одна из ключевых задач процесса, и каждое приложение будет отличаться в зависимости от конкретного варианта использования. Например, представьте, что готовите у себя дома, ваши руки заняты и заняты, когда пришло время вскипятить немного воды, все, что вам нужно, - это быстрый запрос к голосовому агенту, подключенному к вашей водопроводной сети:«Нагрейте воду до x градусов». Проблема здесь в том, может ли устройство слышать то, что вы говорите, и какой шум устройство подавит, чтобы получить чистый сигнал и правильно вас услышать. Чтобы гарантировать это, голосовые алгоритмы должны быть настроены на агрессивную среду, расположение микрофонов должно быть отрегулировано так, чтобы они могли улавливать звук, а динамики с низким коэффициентом нелинейных искажений должны использоваться для обеспечения высокого отношения сигнал / шум для микрофонов. Благодаря этому вы получите максимально чистый звук для механизма ASR, который даст правильный ответ на ваши вопросы.
Более того, представьте, что вы на круизном лайнере:шумы вокруг вас совершенно не те, что вы слышите в гостиной или на кухне. Самая большая проблема - это обучение алгоритмов подавления этих шумов и передачи чистого аудиосигнала в систему для точного отклика. При правильной реализации виртуальная система персонального помощника в круизе, подобная той, которую мы разработали для MSC Cruises, может надежно выполнять шаги, показанные на рисунке 2.
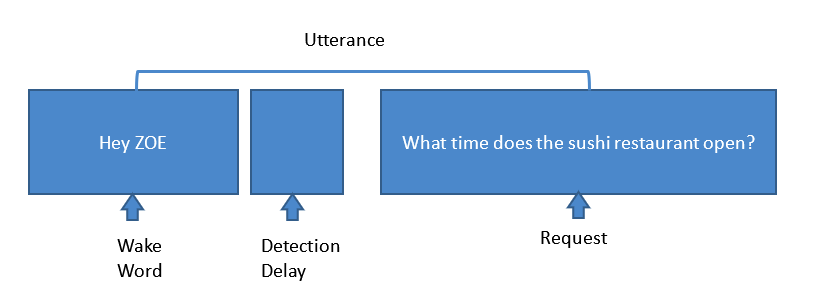
Рис. 2. Шаги, выполняемые при типичном запросе голосового помощника. (Источник:Harman Embedded Audio)
Здесь голосовой помощник в комнате пассажира обнаруживает бодрствующее слово «Привет, Зоя». Затем, когда KWS обнаруживает ключевое слово, весь микрофон на основе алгоритмов подавления шума направляет их энергию в сторону источника и устраняет окружающие шумы, такие как шум переменного тока, ТВ, некоррелированные шумы, шумы пропеллера и двигателя, шумы ветра, AEC и т. д. Алгоритмы Sonique настроены так, чтобы подавлять все эти шумы и получать максимально чистый сигнал в систему. Затем, когда система получает запрос, механизм ASR преобразует этот голос в текст. Затем механизмы NLU преобразуют этот текст в необработанные данные, чтобы получить ответ. Но мы еще не закончили. Чтобы получить ответ, который вы ищете, навык знаний предоставляет ответ на запрос, а механизм ASR преобразует этот текст данных в речь и выводит его через говорящего.
Еще одна проблема связана с отказом от ложной ставки (FRR). Процесс достижения Wake Word FRR, который является одной из контрольных точек, используемых для измерения производительности интеллектуальных динамиков, занимает много времени и дорого. Система используется для проверки того, может ли продукт «просыпаться» должным образом при обнаружении «пробуждающего слова». Для достижения FRR необходимы обученные ключевые слова. По нашему опыту, объединение обученной модели с алгоритмом высшего уровня позволяет командам разработчиков преодолеть проблему и достичь наилучшего возможного FRR. Реакция на слова пробуждения дополнительно проверяется в различных условиях в лаборатории, чтобы убедиться, что система соответствует отраслевым стандартам.
Преимущества использования уникальных голосовых агентов
Голосовые агенты очень полезны для пользователей. Музыка - самый большой и простой вариант использования, но ценность голосовых агентов выходит далеко за рамки удаленного открытия вашей учетной записи Spotify. Голос может включать вещи, взаимодействовать с бытовой техникой, кипятить воду, включать кран - и многое другое! Голос - это мощный инструмент, и агенты много знают о своих пользователях, поэтому компании стремятся получить свои собственные данные - владеть ими, хранить и защищать их.
Решения для голосовой связи имеют широкое применение, но ключевым моментом является использование технологии, которая работает на разных платформах - той, которая актуальна для интеллектуальных динамиков, ноутбуков и смартфонов на Apple, Windows или Android - и использование собранных данных для создания агента, который понимает, постоянно учится и запоминает потребности пользователей. Создание уникального голосового агента обеспечивает такую гибкость использования - и в то же время сохраняет внутренние данные.
Встроенный
- Что такое металлическое стекло?
- В чем разница между массовым и нестандартным производством?
- Что такое повторная платформа в облаке?
- Что мне делать с данными ?!
- Что такое круговая экономика?
- Двигатель постоянного тока и переменного тока:в чем разница?
- Что входит в производственный процесс?
- Что такое полиграфия?
- Что такое лакокрасочная промышленность?
- Что такое упаковочная промышленность?