


Как аналоговые вычисления в памяти могут решить проблемы энергопотребления периферийного вывода ИИ
Машинное обучение и глубокое обучение уже стали неотъемлемой частью нашей жизни. Приложения искусственного интеллекта (AI) с помощью обработки естественного языка (NLP), классификации изображений и обнаружения объектов глубоко встроены во многие из используемых нами устройств. Большинство приложений ИИ обслуживаются с помощью облачных механизмов, которые хорошо работают для того, для чего они используются, например для получения подсказок слов при вводе ответа по электронной почте в Gmail.
Несмотря на то, что мы пользуемся преимуществами этих приложений искусственного интеллекта, этот подход создает проблемы с конфиденциальностью, рассеиванием мощности, задержкой и стоимостью. Эти проблемы можно решить, если имеется локальная машина обработки, способная выполнять частичные или полные вычисления (логический вывод) в источнике самих данных. Это было сложно сделать с помощью традиционных реализаций цифровых нейронных сетей, в которых память становится узким местом, требующим энергоемкости. Проблема может быть решена с помощью многоуровневой памяти и использования аналогового метода вычислений в памяти, который вместе позволяет процессорам обработки удовлетворять гораздо более низкие требования к мощности, от милливатт (мВт) до микроватт (мкВт) для выполнения логического вывода ИИ на край сети.
Проблемы облачных вычислений
Когда приложения ИИ обслуживаются с помощью облачных механизмов, пользователь должен загрузить некоторые данные (добровольно или невольно) в облака, где вычислительные механизмы обрабатывают данные, предоставляют прогнозы и отправляют прогнозы ниже по потоку пользователю для использования.

Рисунок 1. Передача данных из пограничного режима в облако. (Источник:Microchip Technology)
Проблемы, связанные с этим процессом, описаны ниже:
- Вопросы конфиденциальности и безопасности: В случае постоянно включенных устройств, всегда в курсе, есть опасения, что личные данные (и / или конфиденциальная информация) могут быть использованы не по назначению либо во время загрузки, либо в течение срока их хранения в центрах обработки данных.
- Излишнее рассеивание мощности: Если каждый бит данных переходит в облако, он потребляет энергию оборудования, радио, передачи и, возможно, нежелательных вычислений в облаке.
- Задержка для небольших выводов: Иногда для получения ответа от облачной системы может потребоваться секунда или больше, если данные исходят на границе. Для человеческого восприятия задержка более 100 миллисекунд (мс) заметна и может раздражать.
- Экономия данных должна иметь смысл: Датчики есть везде, и они очень доступны по цене; однако они производят много данных. Выгружать каждый бит данных в облако и обрабатывать его неэкономично.
Чтобы решить эти проблемы с использованием локального механизма обработки, модель нейронной сети, которая будет выполнять операции вывода, должна сначала быть обучена с заданным набором данных для желаемого варианта использования. Как правило, это требует больших вычислительных ресурсов (и памяти) и арифметических операций с плавающей запятой. В результате обучающая часть решения для машинного обучения по-прежнему должна выполняться в общедоступных или частных облаках (или локальном графическом процессоре, процессоре, ферме FPGA) с набором данных для создания оптимальной модели нейронной сети. После того, как модель нейронной сети будет готова, модель может быть дополнительно оптимизирована для локального оборудования с небольшим вычислительным механизмом, поскольку модели нейронной сети не требуется обратное распространение для операции вывода. Механизму вывода обычно требуется море механизмов Multiply-Accumulate (MAC), за которым следует уровень активации, такой как выпрямленный линейный блок (ReLU), сигмоид или tanh, в зависимости от сложности модели нейронной сети и уровень объединения между уровнями.
Большинство моделей нейронных сетей требуют огромного количества операций MAC. Например, даже сравнительно небольшая модель «1.0 MobileNet-224» имеет 4,2 миллиона параметров (весов) и требует 569 миллионов операций MAC для выполнения логического вывода. Поскольку в большинстве моделей преобладают операции MAC, основное внимание здесь будет уделено этой части вычислений машинного обучения - и изучению возможности создания лучшего решения. Простая, полностью связанная двухуровневая сеть проиллюстрирована ниже на рисунке 2.
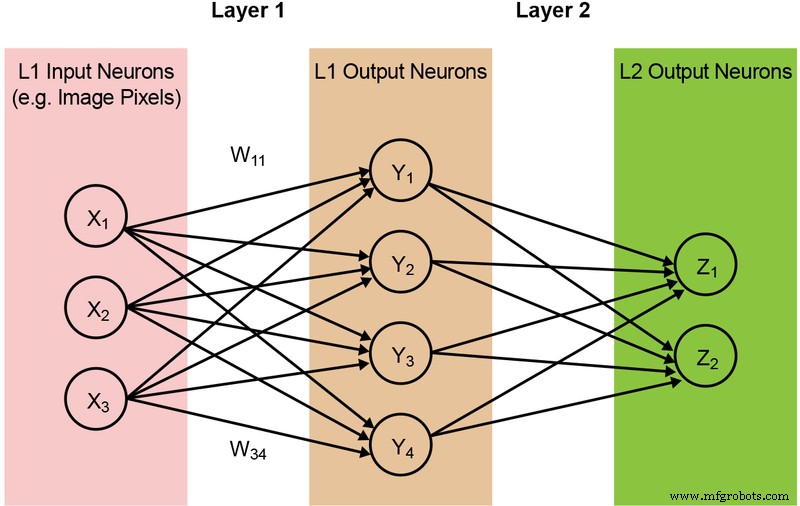
Рис. 2. Полностью подключенная двухуровневая нейронная сеть. (Источник:Microchip Technology)
Входные нейроны (данные) обрабатываются с первым слоем весов. Выходные нейроны из первых слоев затем обрабатываются вторым слоем весов и предоставляют прогнозы (скажем, смогла ли модель найти морду кошки на заданном изображении). Эти модели нейронных сетей используют «скалярное произведение» для вычисления каждого нейрона в каждом слое, что проиллюстрировано следующим уравнением (без члена «смещения» в уравнении для упрощения):
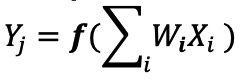
Память Узкое место в цифровых вычислениях
В реализации цифровой нейронной сети веса и входные данные хранятся в DRAM / SRAM. Веса и входные данные необходимо переместить в механизм MAC для вывода. Как показано на рисунке 3 ниже, этот подход приводит к тому, что большая часть мощности рассеивается на выборку параметров модели и входных данных в ALU, где происходит фактическая операция MAC.
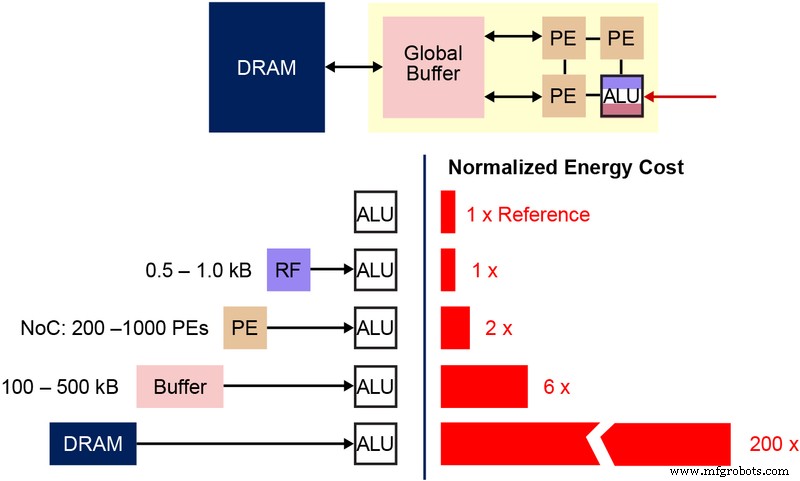
Рис. 3. Узкое место памяти в вычислениях с машинным обучением. (Источник:Я.-Х. Чен, Дж. Эмер и В. Сзе, «Eyeriss:Пространственная архитектура для энергоэффективного потока данных для сверточных нейронных сетей», в ISCA, 2016.)
Чтобы представить вещи в энергетической перспективе, типичная операция MAC с использованием цифровых логических вентилей потребляет ~ 250 фемтоджоулей (фДж, или 10 −15 джоулей) энергии, но энергия, рассеиваемая во время передачи данных, более чем на два порядка величины, чем само вычисление, находится в диапазоне 50 пикоджоулей (пДж, или 10 −12 джоулей) до 100 пДж. Честно говоря, существует множество методов проектирования, позволяющих минимизировать передачу данных из памяти в ALU; однако вся цифровая схема по-прежнему ограничена архитектурой фон Неймана, так что это дает большие возможности для сокращения потерь энергии. Что, если энергия для выполнения операции MAC может быть уменьшена с ~ 100 пДж до долей пДж?
Устранение узких мест с памятью с помощью аналоговых вычислений в памяти
Выполнение операций вывода на границе становится энергоэффективным, когда сама память может использоваться для уменьшения мощности, необходимой для вычислений. Использование метода вычислений в памяти сводит к минимуму объем данных, которые необходимо переместить. Это, в свою очередь, исключает потери энергии при передаче данных. Рассеивание энергии дополнительно сводится к минимуму за счет использования ячеек флэш-памяти, которые могут работать со сверхнизким рассеиваемым активным энергопотреблением и почти без рассеивания энергии в режиме ожидания.
Примером такого подхода является технология memBrain ™ от Silicon Storage Technology (SST), компании Microchip Technology. На основе SST's SuperFlash ® Технология памяти, решение включает в себя вычислительную архитектуру в памяти, которая позволяет выполнять вычисления там, где хранятся веса модели логического вывода. Это устраняет узкое место памяти при вычислении MAC, поскольку нет перемещения данных для весов - только входные данные должны перемещаться от датчика ввода, такого как камера или микрофон, в массив памяти.
Эта концепция памяти основана на двух принципах:(a) Аналоговый отклик на электрический ток транзистора основан на его пороговом напряжении (Vt) и входных данных, и (b) закон Кирхгофа по току, который гласит, что алгебраическая сумма токов в сеть проводников, встречающихся в одной точке, равна нулю.
Также важно понимать фундаментальную битовую ячейку энергонезависимой памяти (NVM), которая используется в этой многоуровневой архитектуре памяти. На диаграмме ниже (Рисунок 4) показано сечение двух ESF3 (Embedded SuperFlash 3 rd генерации) битовых ячеек с общим шлюзом стирания (EG) и исходной линией (SL). Каждая битовая ячейка имеет пять терминалов:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) и Bitline (BL). Операция стирания битовой ячейки выполняется путем подачи высокого напряжения на EG. Операция программирования выполняется путем подачи сигналов смещения высокого / низкого напряжения на WL, CG, BL и SL. Операция чтения выполняется путем подачи сигналов смещения низкого напряжения на WL, CG, BL и SL.
Рис. 4. Ячейка SuperFlash ESF3. (Источник:Microchip Technology)
С этой архитектурой памяти пользователь может программировать битовые ячейки памяти на различных уровнях Vt с помощью операции детального программирования. Технология памяти использует интеллектуальный алгоритм для настройки Vt с плавающим затвором (FG) ячейки памяти для достижения определенного отклика электрического тока от входного напряжения. В зависимости от требований конечного приложения ячейки могут быть запрограммированы либо в линейной, либо в подпороговой рабочей области.
На рисунке 5 показана возможность хранения и чтения нескольких уровней ячейки памяти. Допустим, мы пытаемся сохранить 2-битное целое число в ячейке памяти. Для этого сценария нам нужно запрограммировать каждую ячейку в массиве памяти с одним из четырех возможных значений 2-битных целочисленных значений (00, 01, 10, 11). Четыре нижеприведенные кривые представляют собой ВАХ для каждого из четырех возможных состояний, а реакция электрического тока ячейки будет зависеть от напряжения, приложенного к ЦТ.
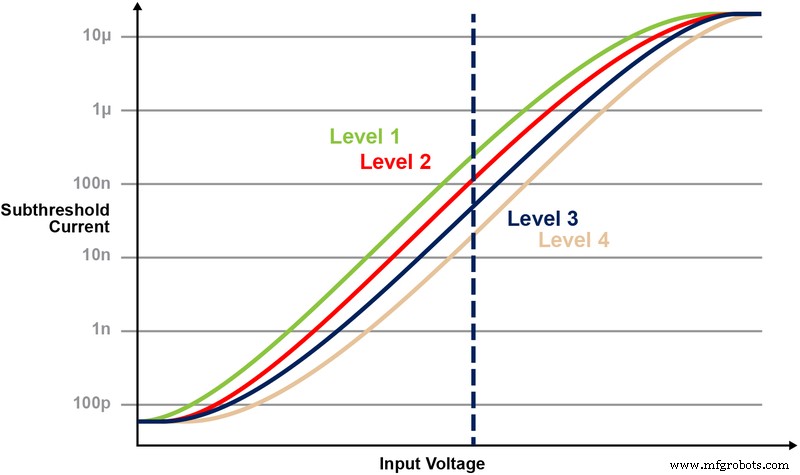
Рисунок 5:Программирование уровней Vt в ячейке ESF3. (Источник:Microchip Technology)
Операция умножения-накопления с вычислениями в памяти
Каждую ячейку ESF3 можно моделировать как переменную проводимость (g m ). Проводимость ячейки ESF3 зависит от плавающего затвора Vt запрограммированной ячейки. Вес из обученной модели запрограммирован как плавающий вентиль Vt ячейки памяти, поэтому g m ячейки представляет собой вес обученной модели. Когда на ячейку ESF3 подается входное напряжение (Vin), выходной ток (Iout) будет определяться уравнением Iout =g m * Vin - операция умножения входного напряжения и веса, хранящегося в ячейке ESF3.
На рисунке 6 ниже показана концепция умножения-накопления в конфигурации небольшого массива (массив 2 × 2), в которой операция накопления выполняется путем сложения выходных токов (из ячеек (из операции умножения), подключенных к тому же столбцу (например, I1 =I11 + I21). В зависимости от приложения функция активации может выполняться либо в блоке АЦП, либо в цифровой реализации вне блока памяти.
щелкните, чтобы увеличить изображение
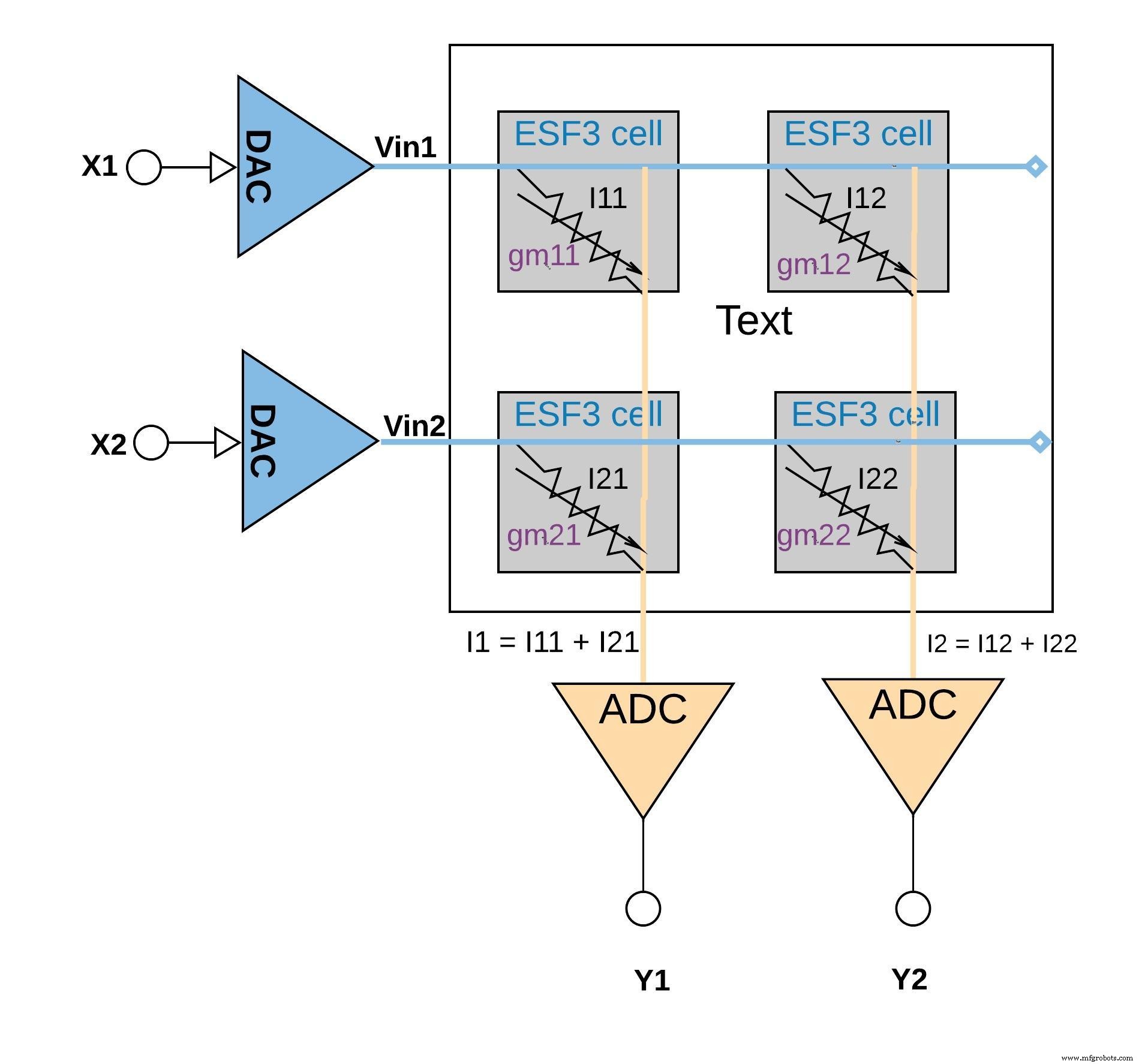
Рисунок 6:операция умножения-накопления с массивом ESF3 (2 × 2). (Источник:Microchip Technology)
Для дальнейшей иллюстрации концепции на более высоком уровне; отдельные веса из обученной модели запрограммированы как плавающий вентиль Vt ячейки памяти, поэтому все веса из каждого слоя обученной модели (скажем, полностью связанного слоя) могут быть запрограммированы в массиве памяти, который физически выглядит как матрица весов , как показано на рисунке 7.
щелкните, чтобы увеличить изображение
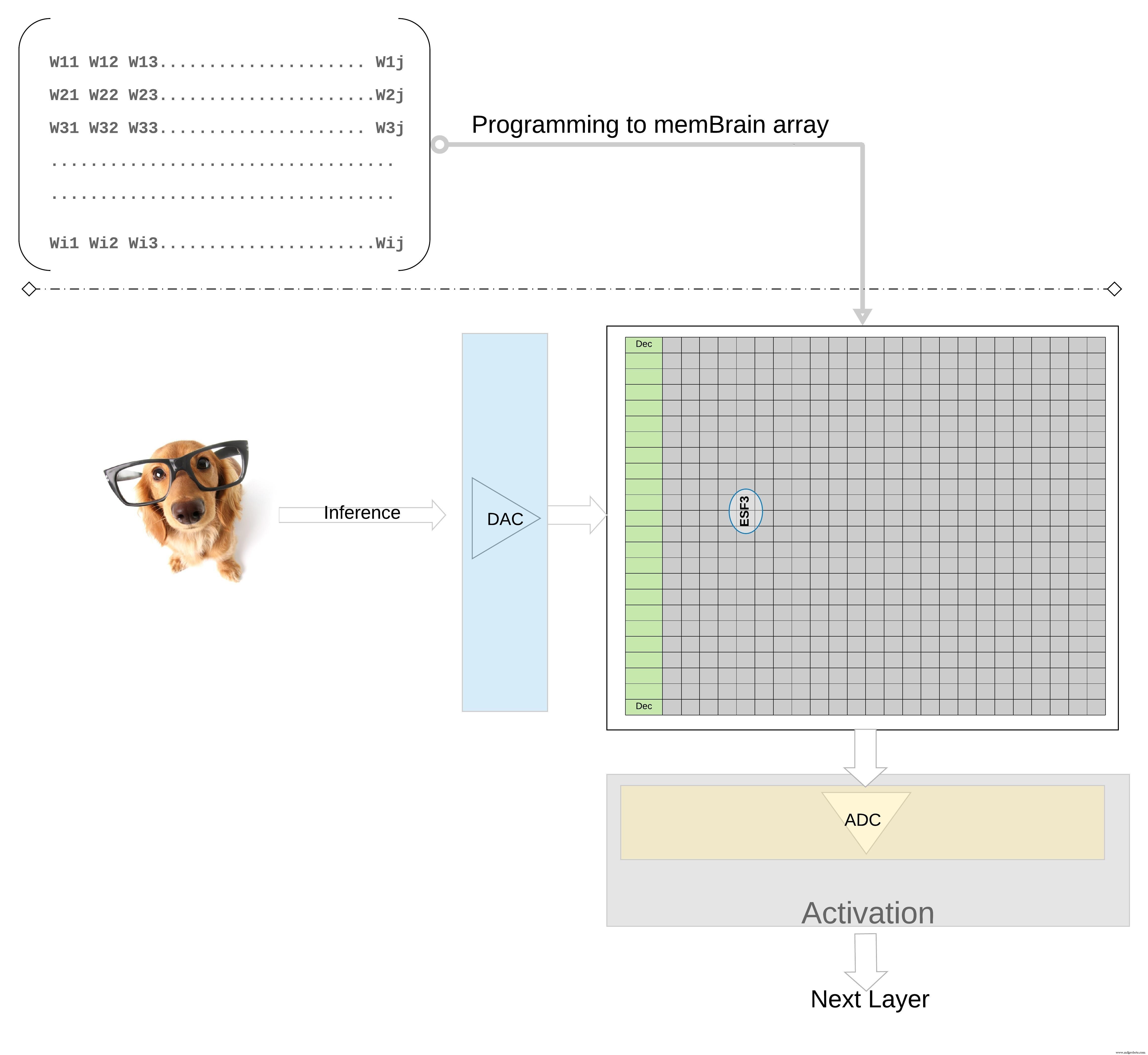
Рис. 7. Массив памяти матрицы весов для вывода. (Источник:Microchip Technology)
Для операции логического вывода цифровой вход, скажем, пиксели изображения, сначала преобразуется в аналоговый сигнал с помощью цифро-аналогового преобразователя (ЦАП) и применяется к массиву памяти. Затем массив выполняет тысячи операций MAC параллельно для данного входного вектора и выдает выходной сигнал, который может перейти на этап активации соответствующих нейронов, который затем может быть преобразован обратно в цифровые сигналы с помощью аналого-цифрового преобразователя (АЦП). Затем цифровые сигналы обрабатываются для объединения перед переходом на следующий уровень.
Этот тип архитектуры памяти очень модульный и гибкий. Многие плитки memBrain можно сшить вместе, чтобы построить множество больших моделей с сочетанием весовых матриц и нейронов, как показано на рисунке 8. В этом примере конфигурация плитки 3 × 4 сшивается вместе с аналоговой и цифровой связью между плитки, а данные можно перемещать с одной плитки на другую по общей шине.
щелкните, чтобы увеличить изображение
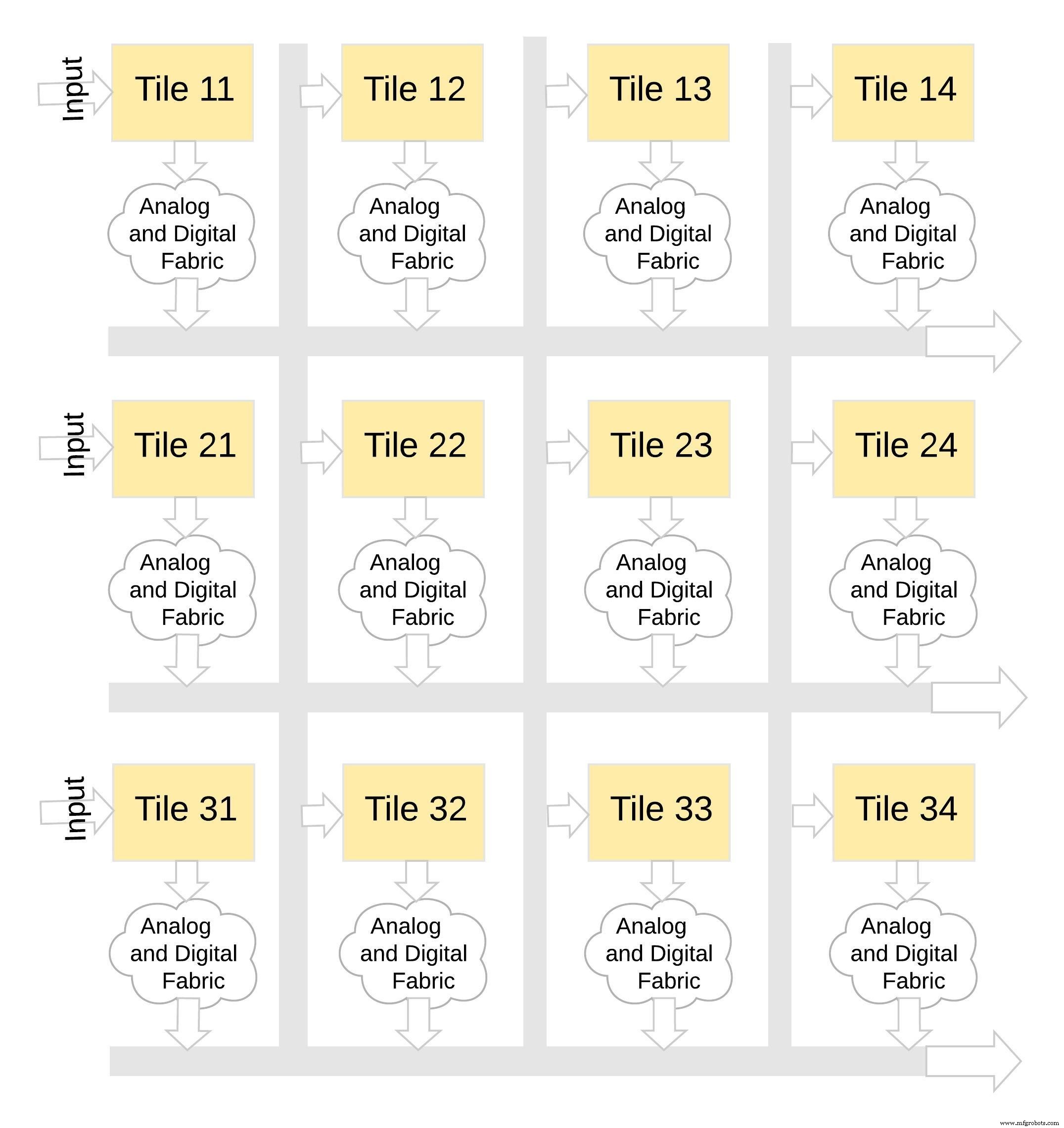
Рисунок 8:memBrain ™ является модульным. (Источник:Microchip Technology)
До сих пор мы в основном обсуждали кремниевую реализацию этой архитектуры. Наличие пакета разработки программного обеспечения (SDK) (рисунок 9) помогает при развертывании решения. Помимо микросхемы, SDK упрощает развертывание механизма вывода.
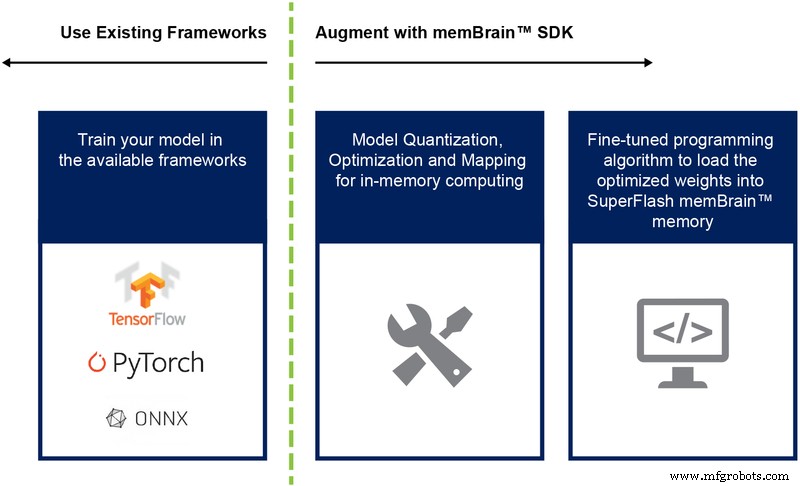
Рисунок 9:поток SDK memBrain ™. (Источник:Microchip Technology)
Поток SDK не зависит от структуры обучения. Пользователь может создать модель нейронной сети в любой из доступных сред, таких как TensorFlow, PyTorch или других, используя вычисления с плавающей запятой по желанию. После создания модели SDK помогает квантовать обученную модель нейронной сети и сопоставить ее с массивом памяти, где вектор-матричное умножение может быть выполнено с входным вектором, поступающим с датчика или компьютера.
Заключение
Преимущества этого подхода с многоуровневой памятью с его вычислительными возможностями в памяти включают:
- Чрезвычайно низкое энергопотребление: Технология предназначена для приложений с низким энергопотреблением. Преимущество мощности первого уровня проистекает из того факта, что решение представляет собой вычисления в памяти, поэтому энергия не тратится впустую на передачу данных и весов из SRAM / DRAM во время вычислений. Второе энергетическое преимущество проистекает из того факта, что флэш-ячейки работают в подпороговом режиме с очень низкими значениями тока, поэтому рассеиваемая активная мощность очень мала. Третье преимущество заключается в том, что в режиме ожидания практически отсутствует рассеивание энергии, поскольку энергонезависимой ячейке памяти не требуется питание для хранения данных для постоянно включенного устройства. Этот подход также хорошо подходит для использования разреженности весов и входных данных. Битовая ячейка памяти не активируется, если входные данные или вес равны нулю.
- Уменьшение занимаемой площади упаковки: Технология использует архитектуру ячейки с разделенным затвором (1.5T), тогда как ячейка SRAM в цифровой реализации основана на архитектуре 6T. Кроме того, ячейка представляет собой битовую ячейку гораздо меньшего размера по сравнению с ячейкой SRAM 6T. Кроме того, одна ячейка может хранить все 4-битное целое число, в отличие от ячейки SRAM, которой для этого требуется 4 * 6 =24 транзистора. Это обеспечивает существенно меньшую занимаемую площадь на кристалле.
- Более низкая стоимость разработки: Из-за узких мест в производительности памяти и ограничений архитектуры фон Неймана многие специализированные устройства (например, Jetsen от Nvidia или TPU от Google), как правило, используют меньшую геометрию для увеличения производительности на ватт, что является дорогостоящим способом решения задачи периферийных вычислений ИИ. При многоуровневом подходе к памяти с использованием аналоговых методов вычислений в памяти вычисления выполняются на кристалле во флеш-ячейках, поэтому можно использовать большую геометрию и сократить затраты на маску и время выполнения.
Приложения для пограничных вычислений выглядят очень многообещающими. Тем не менее, до того, как периферийные вычисления начнут развиваться, необходимо решить проблемы с энергопотреблением и стоимостью. Основное препятствие можно устранить, используя подход памяти, который выполняет вычисления на кристалле во флэш-ячейках. В этом подходе используется проверенное в производстве, де-факто стандартное решение для многоуровневой памяти, оптимизированное для приложений машинного обучения.
Встроенный
- Как периферийные вычисления могут помочь корпоративным ИТ
- Как облачные вычисления могут принести пользу ИТ-персоналу?
- Введение в периферийные вычисления и примеры использования
- Периферийные вычисления:5 потенциальных ловушек
- Как данные IIoT могут повысить прибыльность в бережливом производстве
- Ближе к краю:как периферийные вычисления будут способствовать развитию Индустрии 4.0
- Как отключение электроэнергии может повредить ваши источники питания
- 6 веских причин для внедрения граничных вычислений
- Edge Computing и 5G масштабируют предприятие
- Как небольшие магазины могут стать цифровыми — экономически выгодно!