


Компиляторы в чужом мире функциональной безопасности
Во всех отраслях мир функциональной безопасности предъявляет новые требования к разработчикам. Функционально безопасный код должен включать защитный код для защиты от неожиданных событий, которые могут возникнуть по разным причинам. Например, повреждение памяти из-за ошибок кодирования или событий космических лучей может привести к выполнению путей кода, которые «невозможны» согласно логике кода. Языки высокого уровня, особенно C и C ++, включают удивительное количество функций, поведение которых не предписано спецификацией языка, которой придерживается код. Такое неопределенное поведение может привести к неожиданным и потенциально катастрофическим результатам, которые были бы неприемлемы для функционально безопасного приложения. По этим причинам стандарты требуют, чтобы применялось защитное кодирование, чтобы код можно было тестировать, чтобы можно было сопоставить адекватное покрытие кода и чтобы код приложения отслеживался в соответствии с требованиями, чтобы гарантировать, что система реализует их полностью и однозначно.
Код также должен обеспечивать высокий уровень покрытия кода, а в некоторых секторах, особенно в автомобильной, для проектирования обычно требуются сложные внешние инструменты диагностики, калибровки и разработки. Возникающая проблема заключается в том, что такие практики, как защитное кодирование и доступ к внешним данным, не являются частью мира, который признают компиляторы. Например, ни C, ни C ++ не допускают повреждения памяти, поэтому, если код, предназначенный для защиты от него, не доступен при отсутствии такого повреждения, его можно просто проигнорировать при оптимизации кода. Следовательно, защитный код должен быть синтаксически и семантически доступным, чтобы его нельзя было «оптимизировать».
Примеры неопределенного поведения также могут вызывать сюрпризы. Легко предположить, что их следует просто избегать, но часто бывает трудно идентифицировать их. Там, где они существуют, не может быть никаких гарантий, что поведение скомпилированного исполняемого кода будет соответствовать намерениям разработчиков. «Черный ход» доступа к данным, используемым инструментами отладки, представляет собой еще одну ситуацию, которую язык не учитывает и которая может иметь неожиданные последствия.
Оптимизация компилятора может иметь большое влияние на все эти области, потому что ни одна из них не входит в компетенцию поставщиков компиляторов. Оптимизация может привести к тому, что очевидно надежный защитный код будет устранен там, где он связан с «невозможностью», то есть там, где он существует на путях, которые не могут быть протестированы и проверены никаким набором возможных входных значений. Еще более тревожно то, что защитный код, показанный во время модульного тестирования, вполне может быть исключен при создании исполняемого файла системы. То, что покрытие защитного кода было достигнуто во время модульного тестирования, не гарантирует его присутствие в завершенной системе.
В этой странной стране функциональной безопасности компилятор может оказаться не в своей тарелке. Вот почему проверка объектного кода (OCV) представляет собой наилучшую практику для любой системы, для которой есть тяжелые последствия, связанные с ошибкой, - и, действительно, для любой системы, где только наилучшая практика достаточно хороша.
До и после компиляции
Практика проверки и валидации, поддерживаемая стандартами функциональной безопасности, защиты и кодирования, такими как IEC 61508, ISO 26262, IEC 62304, MISRA C и C ++, уделяет значительное внимание демонстрации того, какая часть исходного кода приложения выполняется во время тестирования на основе требований.
Опыт показал нам, что, если было продемонстрировано, что код работает правильно, вероятность отказа в полевых условиях значительно ниже. И все же, поскольку в центре внимания этого похвального усилия находится исходный код высокого уровня (независимо от того, на каком языке), такой подход в значительной степени полагается на способность компилятора создавать объектный код, который точно воспроизводит то, что разработчики предназначена. В наиболее важных приложениях это подразумеваемое предположение не может быть оправдано.
Неизбежно, что управление и поток данных объектного кода не будут точным зеркалом исходного кода, из которого он был получен, и поэтому доказательство того, что все пути исходного кода могут быть надежно реализованы, не доказывает то же самое, что и объектный код. . Учитывая, что между объектным кодом и ассемблером существует соотношение 1:1, сравнение между исходным и ассемблерным кодом говорит о многом. Рассмотрим пример, показанный на рисунке 1, где код ассемблера справа был сгенерирован из исходного кода слева (с использованием компилятора TI с отключенной оптимизацией).

Рис. 1. Ассемблерный код справа был сгенерирован из исходного кода слева, что показывает наглядное сравнение исходного и ассемблерного кода. (Источник:LDRA)
Как показано ниже, когда этот исходный код компилируется, потоковый граф для результирующего кода ассемблера сильно отличается от такового для исходного, потому что правила, которым следуют компиляторы C или C ++, позволяют им изменять код любым способом, которым они хотят, при условии, что двоичный код ведет себя «как если бы это было то же самое».
В большинстве случаев этот принцип вполне приемлем, но есть аномалии. Оптимизация компилятора - это в основном математические преобразования, которые применяются к внутреннему представлению кода. Эти преобразования «идут не так», если предположения не выполняются - как это часто бывает, когда кодовая база включает, например, экземпляры неопределенного поведения.
Только DO-178C, используемый в аэрокосмической промышленности, уделяет какое-либо внимание потенциальным опасным несоответствиям между намерениями разработчика и поведением исполняемого файла - и даже в этом случае нетрудно найти сторонников обходных путей с явным потенциалом оставить эти несоответствия незамеченными. Однако такие подходы оправданы, но факт остается фактом:различия между исходным и объектным кодом могут иметь разрушительные последствия для любого важного приложения.
Намерение разработчика и поведение исполняемого файла
Несмотря на явные различия между потоком исходного и объектного кода, они не являются главной проблемой. Компиляторы, как правило, являются высоконадежными приложениями, и хотя могут быть ошибки, как и в любом другом программном обеспечении, реализация компилятора, как правило, будет соответствовать его проектным требованиям. Проблема в том, что эти требования к конструкции не всегда отражают потребности функционально безопасной системы.
Короче говоря, можно предположить, что компилятор функционально соответствует целям его создателей. Но это может быть не совсем то, что нужно или ожидается, как показано на рисунке 2 ниже с примером, полученным в результате компиляции с помощью компилятора CLANG.

На экране 2 показана компиляция с помощью компилятора CLANG (Источник:LDRA)
Ясно, что защитный вызов функции «error» не был выражен в коде ассемблера.
Объект «состояние» изменяется только при его инициализации и в случаях «S0» и «S1», поэтому компилятор может решить, что единственными значениями, присвоенными «состоянию», являются «S0» и «S1». Компилятор приходит к выводу, что значение «по умолчанию» не требуется, поскольку «состояние» никогда не будет содержать никаких других значений, при условии отсутствия повреждений - и действительно, компилятор делает именно это предположение.
Компилятор также решил, что, поскольку значения фактических объектов (13 и 23) не используются в числовом контексте, он будет просто использовать значения 0 и 1 для переключения между состояниями, а затем использовать исключительное «или» для обновления. государственная ценность. Бинарный файл придерживается обязательства «как если бы», а код быстрый и компактный. В рамках своего технического задания компилятор хорошо поработал.
Такое поведение имеет значение для инструментов «калибровки», которые используют файл карты памяти компоновщика для косвенного доступа к объектам, а также для прямого доступа к памяти через отладчик. Опять же, такие соображения не входят в компетенцию компилятора и поэтому не принимаются во внимание при оптимизации и / или генерации кода.
Теперь предположим, что код остался неизменным, но его контекст в коде, представленном компилятору, немного изменился, как показано на рисунке 3.
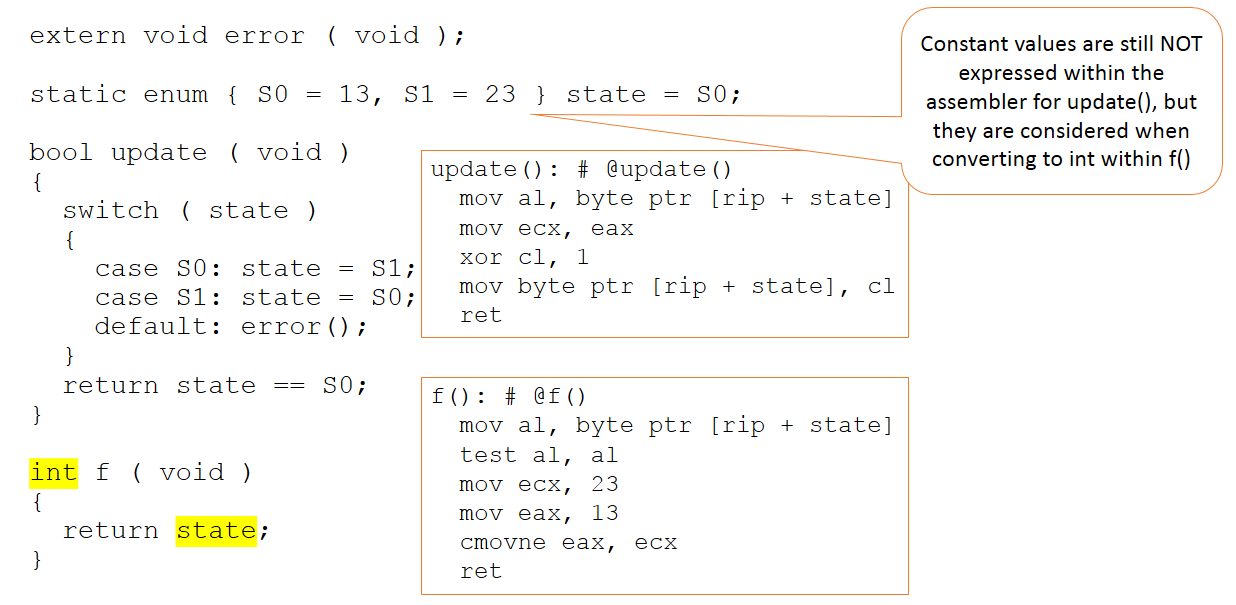
Рисунок 3:Код остается неизменным, но его контекст в коде, представленном компилятору, немного меняется. (Источник:LDRA)
Теперь есть дополнительная функция, которая возвращает значение переменной состояния в виде целого числа. На этот раз в коде, представленном компилятору, имеют значение абсолютные значения 13 и 23. Даже в этом случае эти значения не обрабатываются в функции обновления (которая остается неизменной) и видны только в нашей новой функции «f».
Короче говоря, компилятор продолжает (справедливо) делать оценочные суждения о том, где следует использовать значения 13 и 23 - и они никоим образом не применяются во всех ситуациях, где они могут быть.
Если новая функция изменяется так, чтобы возвращать указатель на нашу переменную состояния, код ассемблера существенно изменяется. Поскольку теперь существует возможность доступа к псевдониму через указатель, компилятор больше не может определить, что происходит с объектом состояния. Как показано на рисунке 4 ниже, нельзя сделать вывод, что значения 13 и 23 не важны, и поэтому они теперь явно выражаются в ассемблере.
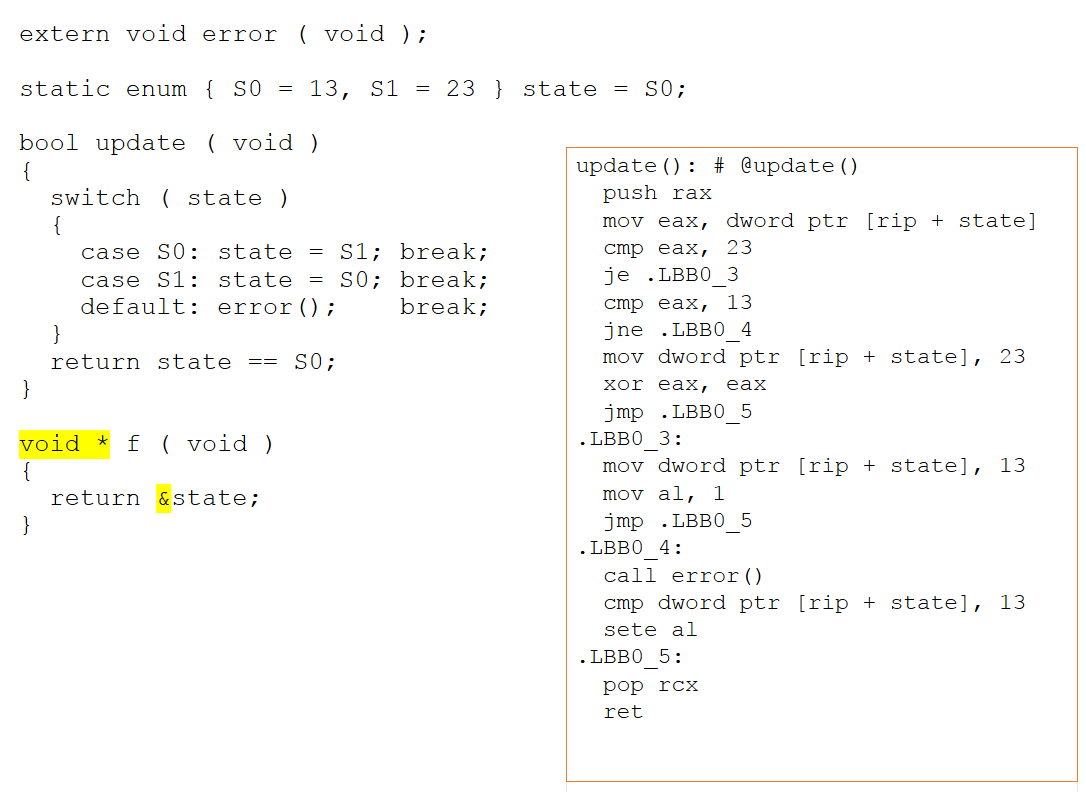
Рисунок 4:Если новая функция изменяется так, чтобы возвращать указатель на нашу переменную состояния, код ассемблера существенно изменяется. Из этого нельзя сделать вывод, что значения 13 и 23 не важны и поэтому теперь они явно выражаются в ассемблере (Источник:LDRA).
Последствия для модульного тестирования исходного кода
Теперь рассмотрим пример в контексте воображаемой обвязки модульного теста. Вследствие необходимости использования жгута для доступа к тестируемому коду значение переменной состояния изменяется, и, как следствие, значение по умолчанию не «оптимизируется». Такой подход полностью оправдан в инструменте тестирования, у которого нет контекста, относящегося к остальной части исходного кода, и который требуется, чтобы сделать все доступным, но в качестве побочного эффекта он может замаскировать законное упущение защитного кода компилятором. / P>
Компилятор распознает, что произвольное значение записывается в переменную состояния через указатель, и, опять же, он не может сделать вывод, что значения 13 и 23 не важны. Следовательно, теперь они явно выражены в ассемблере. В этом случае нельзя сделать вывод, что S0 и S1 представляют единственные возможные значения для переменной состояния, что означает, что путь по умолчанию может быть допустимым. Как показано на рисунке 5, манипулирование переменной состояния достигает своей цели, и теперь вызов функции ошибки очевиден в ассемблере.

Рис. 5. Манипуляция переменной состояния достигает своей цели, и теперь ассемблер видит вызов функции ошибки. (Источник:LDRA)
Однако эта манипуляция не будет присутствовать в коде, который будет поставляться в продукте, и поэтому вызов error () на самом деле отсутствует во всей системе.
Важность проверки объектного кода
Чтобы проиллюстрировать, как проверка объектного кода может помочь решить эту загадку, рассмотрим первый пример фрагмента кода, показанный на рисунке 6:

Рисунок 6:Это иллюстрирует, как проверка объектного кода может помочь решить, почему обращение к ошибке не во всей системе. (Источник:LDRA)
Этот код C может быть продемонстрирован для достижения 100% покрытия исходного кода с помощью одного вызова следующим образом:
f_ while4 (0,3);
Код можно переформатировать для выполнения одной операции на строку и представить на потоковом графе как набор узлов «базового блока», каждый из которых представляет собой последовательность прямолинейного кода. Взаимосвязь между базовыми блоками представлена на рисунке 7 с использованием направленных ребер между узлами.
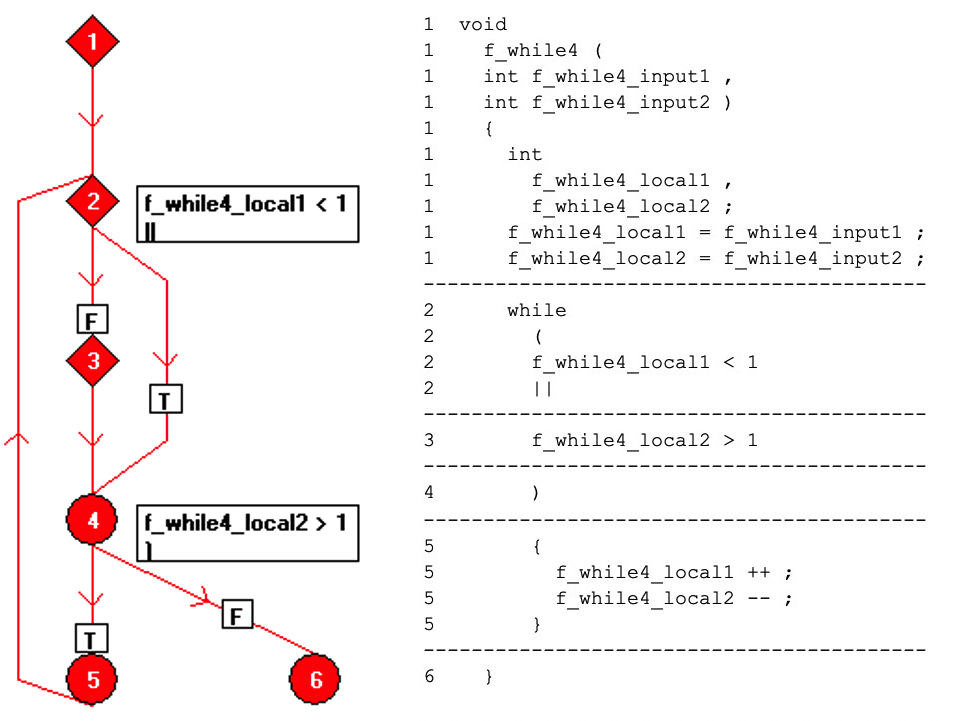
Рисунки 7:Здесь показаны отношения между базовыми блоками с использованием направленных ребер между узлами. (Источник:LDRA)
Когда код скомпилирован, результат будет таким, как показано ниже (рисунок 8). Синие элементы потокового графа представляют код, который не использовался вызовом f_ while4 (0,3).
Используя взаимно-однозначную взаимосвязь между объектным кодом и кодом ассемблера, этот механизм показывает, какие части объектного кода не используются, побуждая тестировщика разработать дополнительные тесты и достичь полного покрытия кода ассемблера - и, следовательно, обеспечить проверку объектного кода.
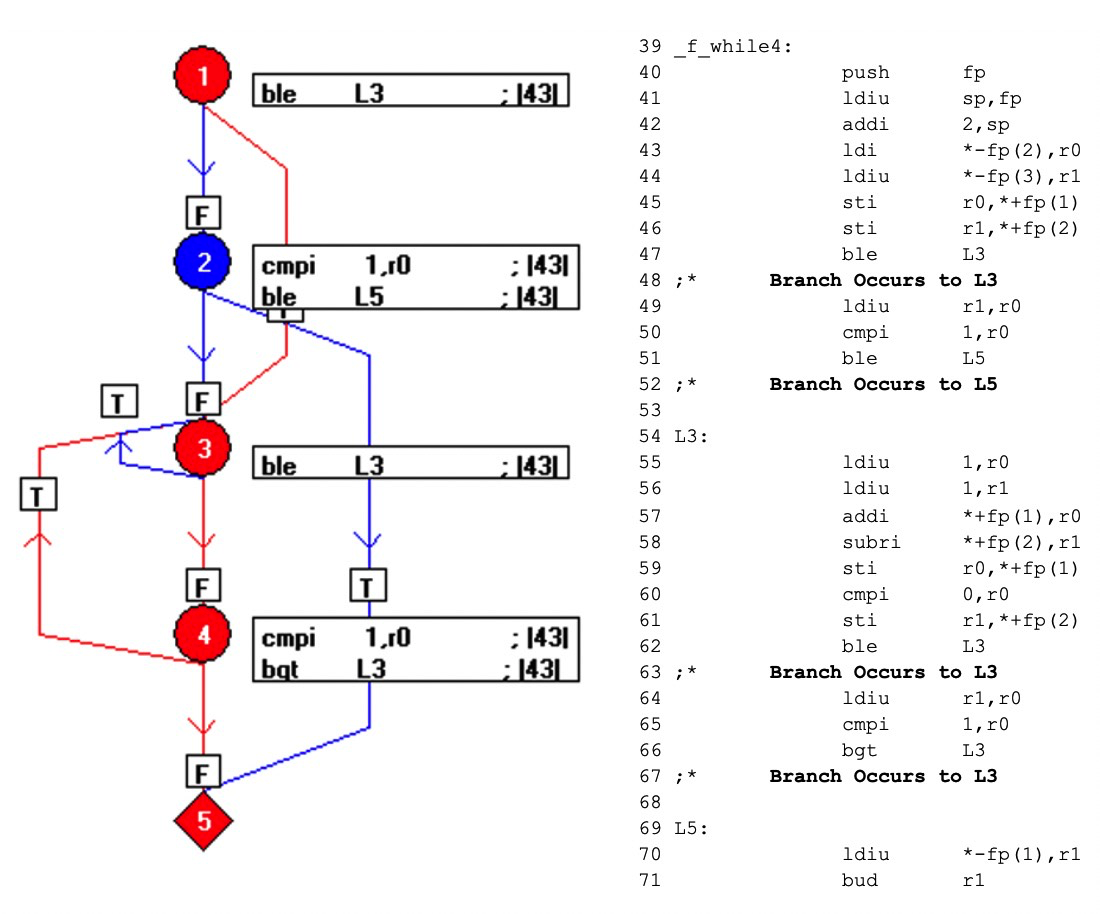
Рисунки 8:Здесь показан результат компиляции кода. Синие элементы потокового графа представляют код, который не выполнялся при вызове f_ while4 (0,3). (Источник:LDRA)
Ясно, что проверка объектного кода не может помешать компилятору следовать его правилам проектирования и непреднамеренно обойти лучшие намерения разработчиков. Но он может привлечь внимание неосторожных к любым подобным несоответствиям.
Теперь рассмотрим этот принцип в контексте предыдущего примера с «призывом к ошибке». Исходный код завершенной системы, конечно, будет идентичен тому, который был проверен на уровне модульного тестирования, и поэтому его сравнение ничего не покажет. Но применение проверки объектного кода к завершенной системе было бы бесценным для обеспечения уверенности в том, что основное поведение выражается так, как задумано разработчиками.
Лучшая практика в любом мире
Если компилятор обрабатывает код в тестовой среде иначе, чем в модульном тесте, то стоит ли покрывать исходный код модульным тестом? Ответ - положительное «да». Многие системы прошли сертификацию на наличие таких артефактов и доказали свою безопасность и надежность в эксплуатации. Но для наиболее важных систем во всех секторах, если процесс разработки должен выдерживать самую тщательную проверку и придерживаться лучших практик, тогда покрытие модульным тестированием исходного уровня должно быть дополнено OCV. Разумно предположить, что он соответствует критериям проектирования, но эти критерии не включают соображения функциональной безопасности. Проверка объектного кода в настоящее время представляет собой наиболее надежный подход к миру функциональной безопасности, когда поведение компилятора соответствует стандартам, но, тем не менее, может иметь значительное негативное влияние.
Встроенный
- Важность электробезопасности
- Мир текстильных красителей
- Применение кислотных красителей в мире тканей
- Взгляд в мир красителей
- Многочисленные варианты использования корзин безопасности
- Быстро развивающийся мир моделирования
- Производственные столицы мира
- 5 самых важных советов по безопасности крана
- Важность фрикционных материалов в системах безопасности
- Безопасность на заводах:источник постоянного улучшения