


Отключение облака:почему и как это происходит?
Чем больше ИТ-отдел полагается на облачные сервисы, тем выше вероятность простоя и потери доходов из-за сбоя в работе облака. Более 60 % организаций, использующих общедоступное облако, сообщают об убытках в 2022 году из-за этих инцидентов, поэтому сбои в работе не являются чем-то необычным, с чем компании вряд ли столкнутся.
Но достаточно ли сбоев в работе для того, чтобы навсегда покинуть облако? Или вам следует придерживаться этого типа инфраструктуры, несмотря на риск случайных простоев?
В этой статье рассказывается все, что вам нужно знать о сбоях в работе облачных служб. . Мы расскажем об их основных причинах, изучим поучительную статистику, покажем, как свести к минимуму последствия простоя облака, и рассмотрим самые серьезные сбои, произошедшие за последние годы.

Что такое облачный сбой?
Облачный сбой — это период времени, в течение которого услуги облачного провайдера недоступны для конечных пользователей. Инфраструктура поставщика выходит из строя (из-за ошибки, сбоя питания и т. д.), и клиенты теряют доступ к облачным ресурсам до тех пор, пока поставщик не устранит проблему.
С точки зрения воздействия нет никакой разницы между выходом из строя локального центра обработки данных и отключением облака. В обоих случаях вы теряете доступ к ИТ-активам, но подход к облачным вычислениям, основанный на невмешательстве, добавляет несколько уникальных соображений:
- Сбои в работе облачных служб практически не видны, поэтому пользователи обычно не знают, что пошло не так.
- Команда провайдера несет ответственность за исправление ошибки, поэтому клиенты не участвуют в процессе восстановления.
- Поскольку вы не видите и не контролируете проблему, вы не можете узнать, когда сервисы снова станут доступными.
Как и в случае с локальным оборудованием, существует два типа сбоев в работе:
- Запланировано (обычно происходит из-за планового обслуживания).
- Незапланированные (происходит, когда поставщик сталкивается с непредвиденной ошибкой и должен принять меры по восстановлению).
Недавние исследования показывают, что незапланированные простои обходятся на 35 % дороже, чем запланированные простои (как локально, так и в облаке). Разница в цене возникает из-за того, что для выявления и устранения неожиданных инцидентов требуется больше времени, и чем дольше длится сбой, тем больше ущерб.
По сравнению с локальным оборудованием облачная инфраструктура приводит к более частым простоям, но с меньшей серьезностью. . Поскольку ни одна хостинговая система не обеспечивает 100% безотказной работы, клиенты готовы мириться с периодическими сбоями в обмен на преимущества облачных вычислений. Эта готовность проявляется и в росте рынка:в 2024 году на облачные технологии будет приходиться 14,2 % от общих мировых расходов на ИТ (по сравнению с 9,1 % в 2020 году).
Причины сбоя в облаке
Сбои в облаке возникают по ряду причин, находящихся как внутри, так и вне контроля провайдера. Вот список наиболее распространенных:
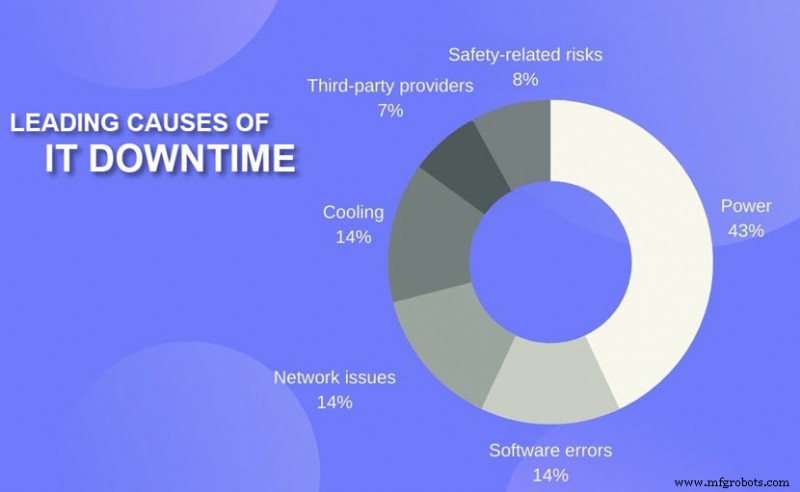
- Отключение электроэнергии: Проблемы, связанные с питанием, являются причиной 43% всех отключений облачных вычислений со значительными простоями и финансовыми потерями. Отказы источников бесперебойного питания (ИБП) являются основной причиной аварий с электропитанием.
- Кибербезопасность: Кибератаки, такие как распределенный отказ в обслуживании (DDoS), перегружают центры обработки данных входящим трафиком. В этом случае конечные пользователи не могут получить доступ к услуге через ту же сетевую инфраструктуру. Другие угрозы (такие как программа-вымогатель или внедрение кода SQL) могут вынудить поставщика отключить службы и устранить проблему в автономном режиме.
- Человеческая ошибка: Одна неверная команда или ошибка с кабелем могут вывести из строя всю ИТ-инфраструктуру. Человеческие ошибки вызывают как физические, так и программные проблемы, которые приводят к сбоям в работе.
- Технические проблемы: Облачные сервисы зависят от сложной системы аппаратных технологий, поэтому ошибка, которая остается незамеченной достаточно долго, может привести к сбою в работе облака.
- Ошибки программного обеспечения: Глюки и ошибки распространены в облачных центрах обработки данных. Обычно виновниками проблем являются ошибки формата данных, ошибки, связанные с ошибками, ошибки синхронизации и ошибки постоянных значений.
- Проблемы с сетью: Проблемы, связанные с сетевой связью и сторонними партнерами по телекоммуникациям, – еще одна распространенная причина сбоев в работе облака.
- Техническое обслуживание: Плановое техническое обслуживание и обновления системы иногда приводят к сбоям, хотя конечные пользователи обычно знают об этих событиях заранее.
- Причины, связанные с окружающей средой: Такие события, как ураганы, пожары, грозы и землетрясения, также вызывают простои облака, подвергая объект опасности или нанося ущерб электросети региона.
- Более сложные развертывания: Более сложные модели развертывания (например, гибридные, распределенные и мультиоблачные) усложняют работу центра обработки данных, создавая больше возможностей для ошибок.
Что происходит, когда облако отключается?
В лучшем случае сбой в облаке длится всего несколько минут и влияет на небольшое количество пользователей или служб. В худшем случае сбой парализует бизнес клиента на полдня и более. Компания теряет доступ ко всем облачным ресурсам и остается отключенной до окончания сбоя.
Несмотря на угрозу, ошибки сторонних поставщиков стали причиной «лишь» 7 % серьезных сбоев в 2021 году. . Серьезный сбой должен включать одно (или несколько) из следующего:
- Значительные финансовые потери.
- Ущерб репутации.
- Нарушения нормативных требований.
- Смерть.
Хотя есть и более насущные проблемы (как показано на кольцевой диаграмме ниже), помните, что средняя минута простоя стоит 5600 долларов США. (эта цифра в минуту доходит до 9000 долларов для предприятий). Если вы не готовы (т. е. у вас нет резервных копий данных, аварийного восстановления и т. д.), сбой в облаке может привести к полной остановке службы и серьезному снижению прибыли.
Компания, которая держит небольшой сегмент операций в облаке, менее уязвима для сбоев. Например, если вы размещаете только электронную почту в облаке, даже однодневное отключение не является катастрофическим. Вы можете переждать инцидент или запустить приложения с ограниченной функциональностью — стратегия, которая не работает, если вы используете облако для запуска платформы IoT или обработки платежей.
В некоторых случаях выход из строя облака приводит к безвозвратной потере данных (объем потерянных данных зависит от частоты резервного копирования). Кроме того, клиенты в строгих отраслях несут ответственность за юридические штрафы, если сбой приводит к нарушению данных или утечке, поэтому будьте осторожны при принятии решения о том, что вы храните в облачном хранилище.
Что могут делать пользователи?
Вот что делают компании, чтобы смягчить последствия сбоев в работе облачных служб:
- Устранение единых точек отказа: Подготовьте резервную копию каждого критически важного ИТ-компонента либо в локальной серверной, либо у вторичного поставщика. Если облако выходит из строя, вы выполняете отработку отказа (процесс переключения на резервный сервер, аппаратный компонент, сеть и т. д.), чтобы обеспечить непрерывность бизнеса.
- Составьте план на случай непредвиденных обстоятельств: План аварийного восстановления описывает пошаговую стратегию действий команды в случае сбоя. Этот план содержит инструкции по защите данных, выполнению аварийного переключения, обеспечению непрерывности бизнеса и восстановлению операций. Своевременное планирование сбоя в облаке позволяет не тратить время на оценку наилучшего плана действий во время простоя.
- Инвестируйте в соглашение об уровне обслуживания с более высокой доступностью: Если ваши критически важные бизнес-задачи не могут позволить себе длительные простои в облаке, ищите соглашение об уровне обслуживания (SLA) с более высокой доступностью, например, которое гарантирует 99,999% времени безотказной работы (максимум 5,25 минут простоя в год). Эти контракты обходятся дороже, но для поставщика облачных услуг приоритетной задачей становится сохранение ваших сервисов в сети.
- Выполняйте регулярное резервное копирование данных: Резервное копирование гарантирует, что ваша команда сможет восстановить последнюю версию файлов, если сбой в облаке повредит или удалит базу данных. В идеале резервное копирование должно выполняться автоматически и от одного раза в час до одного раза в день (в зависимости от важности задачи).
- Как можно скорее обнаруживать сбои: Любые дополнительные возможности облачного мониторинга, которые настраивает ваша команда, помогают выявлять сбои в режиме реального времени, не дожидаясь уведомления поставщика. Вот список лучших инструментов облачного мониторинга, позволяющих улучшить обнаружение простоев и обеспечить своевременную отработку отказа.
Крупнейшие недавние сбои в облаке
Сбои в облаке неизбежны при использовании облака, и даже самые популярные поставщики (такие как Azure, AWS и Google Cloud) не застрахованы от простоев. Давайте рассмотрим некоторые из наиболее значительных сбоев в работе облачных служб в новейшей истории.
Отключение Azure (октябрь 2021 г.)
В октябре 2021 года в Microsoft Azure произошел сбой, из-за которого службы виртуальных машин были отключены на шесть часов. . Во время сбоя многие пользователи не смогли развернуть новые виртуальные машины или обновить расширения. Базовые операции управления службами (такие как запуск, создание и удаление) также приводили к ошибкам.
Причиной сбоя в облаке стала невозможность запросов ВМ для получения требуемых данных о версии артефакта. Отчет после восстановления показал, что программная ошибка произошла, когда Microsoft перенесла одну из своих архитектур виртуальных машин.
Отключение Google Cloud (ноябрь 2021 г.)
Google Cloud отключился примерно на два часа в середине ноября прошлого года, что затронуло:
- Хоум Склад.
- Снэпчат.
- Этси.
- Раздор.
- Спотифай.
На затронутых веб-сайтах отображалась ошибка 404, когда посетители пытались получить к ним доступ. Google сообщил, что причиной сбоя в работе облака стал сбой в конфигурации сети, отвечающей за балансировку нагрузки.
Отключение AWS (декабрь 2021 г.)
Большой всплеск активности подключений перегрузил сетевые устройства в одном из флагманских объектов AWS, затронув различные веб-сайты и приложения. Некоторыми из наиболее заметных «жертв» были:
- Веб-сайт Amazon.
- Основное видео.
- Нетфликс.
- IMDb.
- Сеть PlayStation.
Проблема с центром обработки данных вызвала серьезную задержку во внутренних сетях AWS. Приложения клиентов почувствовали волновой эффект, страдая от задержек трафика или полного отключения примерно на семь часов. .
Два последующих отключения IBM (январь 2022 г.)
Проблема с инфраструктурой IBM влияла на облачные сервисы в регионе Даллас более пяти часов. . Собственная команда решила проблему, но случайно вызвала дополнительную часовую проблему с виртуальным частным облаком. Вторая проблема затронула пользователей по всему миру, включая США, Японию, Канаду и Германию.
Отключение AWS/Slack (февраль 2022 г.)
В феврале в Slack произошел сбой в работе облачных ресурсов AWS, из-за чего нормальное использование коммуникационной платформы было невозможно в течение пяти часов. . Более 11 000 зарегистрированных пользователей не смогли:
- Отправлять и получать сообщения.
- Загрузить файлы.
- Присоединяйтесь к каналам.
- Запустите настольное приложение.
Команда Slack так и не сообщила причину сбоя в облаке и попросила всех затронутых пользователей перезапустить приложение и очистить кеш после восстановления.
Отключение iCloud (март 2022 г.)
Пятнадцать основных сервисов Apple были отключены на четыре часа. в марте из-за сбоя в облаке, в том числе:
- Магазин приложений.
- Карты Apple.
- Apple TV.
Корпоративные и розничные системы Apple также вышли из строя. Позже компания сообщила, что основной причиной была проблема, связанная с системой доменных имен (DNS) компании.
Отключение Google Cloud (март 2022 г.)
8 марта 2022 г. пользователи Google Cloud страдали от служебных ошибок в течение двух с половиной часов. . Spotify и Discord были среди тех, кто пострадал от сбоя.
Изменение кода Traffic Director для обработки конфигураций вызвало ошибку. Согласно отчету после восстановления, при изменении неправильного кода игнорировались переносы форматов данных конфигурации, поэтому платформа непреднамеренно удалила программу пользователя.
Отключение Atlassian (апрель 2022 г.)
Крупнейший в году сбой Atlassian начался 5 апреля и закончился 18 апреля (хотя некоторые пользователи начали восстанавливать сервисы к 8 апреля). Компания объяснила, что сбой произошел из-за неадекватного взаимодействия команды и плохо спланированного плана реагирования на инциденты.
Хотя этот облачный сбой длился почти две недели для некоторых пользователей не было сообщений о значительных потерях клиентских данных. Однако эта проблема затронула пользователей обоих флагманских продуктов Atlassian, Trello и Jira.
Отключение Microsoft Azure (июнь 2022 г.)
7 июня клиенты Azure не смогли подключиться к ресурсам, размещенным в регионе Восток США 2 (в основном Вирджиния). Отключение длилось около двенадцати часов. и не повлияло на потребителей, полагающихся на зонально-избыточную инфраструктуру. Скомпрометированные сервисы включают:
- Статистика приложений.
- Аналитика журналов.
- Служба управляемой идентификации.
- Медиа-сервисы.
- Файлы NetApp.
Виновником стал внезапный скачок напряжения в одном из местных центров обработки данных, что привело к отключению вентиляционных установок (AHU).
Отключение Cloudflare (июнь 2022 г.)
В июне случайное отключение Cloudflare вызвало серьезные сбои, которые длились полтора часа. , закрывая такие популярные сайты, как:
- Раздор.
- Shopify.
- Фитбит.
- Пелотон.
Поставщик из Сан-Франциско объяснил, что незапланированный простой был вызван изменением конфигурации сети в 19 его центрах обработки данных.
Не упускайте из виду ценность планирования сбоев в облаке
Примеры сбоев в работе облачных служб в последние годы ясно показывают:хотя облачные технологии меняют правила игры в сфере ИТ, эта технология не является надежной. . Компании, которые заботятся о конечных пользователях и доступности приложений, должны быть готовы к периодическим простоям, что делает резервное копирование и аварийное восстановление (BDR) неотъемлемой частью использования облачных ресурсов.
Облачные вычисления
- Что такое трансферное формование и как оно работает?
- Как (и зачем) оценивать производительность общедоступного облака
- Что такое облачная безопасность и почему она требуется?
- Облако и как оно меняет мир ИТ
- Безагентные и агентные архитектуры:почему это важно?
- Что такое скрытый сервер Vpn и как он работает
- Как работает облачное хранилище Google?
- Зачем и как проводить вакуумный аудит
- Что такое промышленное сцепление и как оно работает?
- Проверка кранов:когда, зачем и как?