


Озеро данных против больших данных для промышленных приложений
Озеро данных и большие данные - два современных термина, которые часто неправильно понимают и используют неправильно. Из-за предполагаемых больших объемов данных эти термины иногда используются как синонимы. Однако озеро данных и большие данные различаются, даже если их текущие определения еще не полностью определены.

Рисунок 1. Современные данные могут поступать из многих источников и относиться к разным типам. Изображение предоставлено Analytics Vidhya
Давайте сначала посмотрим на краткий исторический контекст. В конце 2000-х годов, когда произошел взрывной рост платформ социальных сетей, таких как Facebook и Twitter, многие специалисты по данным начали осознавать потенциал таких платформ для генерации больших объемов ценных личных данных. Следовательно, были разработаны новые программные приложения для облегчения обработки и анализа данных. Одним из ярких примеров является Apache Hadoop, по сути, набор приложений с открытым исходным кодом, которые могут обрабатывать большие объемы данных.
В следующем десятилетии на сцену вышел Интернет вещей (IoT). Это открыло двери для миллионов дополнительных источников данных, которые могут дать представление о предпочтениях и закономерностях человека, а также отправить информацию о самом продукте.
В то же время машинное обучение добилось важных успехов и нашло более практическое применение в промышленной сфере. Это привело к увеличению потребности в обработке больших объемов данных в отраслях, особенно в автоматизированных процессах.
Все прогнозы показывают, что общий объем данных, доступных в мире, будет продолжать расти ускоренными темпами в ближайшие годы. Для справки, в 2016 году мир преодолел рубеж в 1 зеттабайт ежегодного генерируемого интернет-трафика. Один зеттабайт равен 1 триллиону гигабайт.
Ожидается, что в 2021 году годовой интернет-трафик превысит 3 зеттабайта. Эти прогнозы, наряду с расширенными возможностями облачных вычислений, указывают на то, что ценность и использование больших данных (и озер данных), возможно, только начинается.
Что такое большие данные?
Если смотреть на это просто с точки зрения объема, определение больших данных - это подвижная цель. По мере того, как объем данных и доступное пространство для хранения продолжают расти, растет и эталон того, что считается большим объемом информации.
Сегодня хранилище данных размером 100 терабайт или более обычно считается большим объемом данных. Размер больших хранилищ данных, например, из социальных сетей, может составлять несколько петабайт.
Еще одна ссылка, используемая для определения больших данных, - это когда объем информации не может быть обработан традиционными компьютерными инструментами, такими как SQL. Например, сегодня размер баз данных нередко достигает 1 терабайта в год. Но по мере того, как приложения SQL становятся все более мощными, такой размер базы данных все еще можно контролировать; поэтому они обычно не считаются большими данными.
Модель 4V больших данных
До сих пор мы рассматривали определение больших данных с точки зрения объема. Следует учитывать еще три важных фактора:скорость, разнообразие и достоверность. Вместе с объемом они образуют модель 4V.
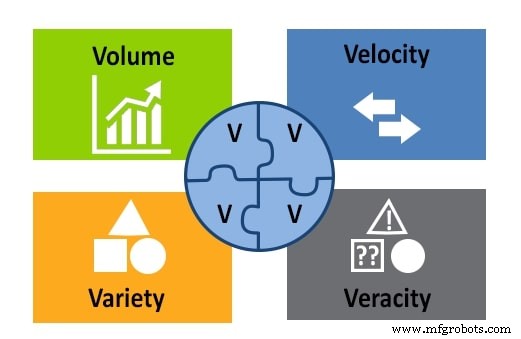
Рисунок 2. Модель больших данных 4V:объем, скорость, разнообразие и достоверность. Изображение предоставлено APSense
Под разнообразием понимаются все различные типы данных, хранящиеся в репозитории больших данных:текст, изображения, звук, видео и т. Д. Это также относится к тому факту, что данные могут поступать из нескольких источников.
Скорость - важный фактор в больших данных, потому что информация поступает постоянно. Скорость связана со скоростью, с которой данные собираются, генерируются и распространяются.
Достоверность измеряет точность и качество данных, чтобы оценить, может ли специалист по обработке данных использовать их для анализа и для получения на их основе выводов.
Теперь, когда мы понимаем большие данные, давайте рассмотрим озера данных, прежде чем углубляться в то, как их использовать в системе управления.
Что такое озеро данных?
Озера данных - это централизованные хранилища больших объемов необработанных данных, которые представляют собой информацию, которая может быть или не быть ценной в будущем и цель которой еще не известна на 100%. Озера данных могут хранить реляционные и нереляционные базы данных вместе с другими типами файлов и сущностей.
Хотя информация в озере данных не обрабатывается и не упорядочивается, она структурирована таким образом, что все входные и выходные данные рассматриваются для создания хорошей архитектуры.
Озеро данных против больших данных
Озеро данных - это экземпляр приложения для больших данных. Они следуют критериям, описанным в модели 4V, с некоторыми дополнительными особенностями. С точки зрения объема озера данных в среднем находятся около нижнего предела того, что считается большими данными.
Информация в озерах данных разнообразна, но при условии, что это только необработанные необработанные данные. Скорость ввода и вывода так же актуальна, как и в любой современной системе, а оценка качества данных выполняется в хорошо спроектированном озере данных.
Промышленные приложения для данных
Передовая автоматизация приводит к быстрому увеличению объема информации, обрабатываемой в производственном цехе. Благодаря этому производственные и другие производственные процессы теперь входят в сферу больших данных, а в некоторых сферах деятельности теперь используются такие инструменты, как озера данных.
Ярким примером является профилактическое обслуживание. Возможность прогнозирования механического или электрического отказа очень важна и может обеспечить значительную экономию затрат на ремонт. Озера данных - полезные инструменты, которые могут собирать информацию, поступающую из файлов журналов, нескольких датчиков и устройств ввода, которые можно использовать для понимания тенденций и прогнозирования проблем.
Машинное обучение - это концепция, при которой роботам предоставляется информация, которая может помочь им адаптироваться к изменяющимся внешним условиям. Сбор информации аналогичен профилактическому обслуживанию, с дополнительным этапом, на котором оценки и изменения процесса автоматически передаются в системный контроллер. Данные машинного обучения можно хранить в озере структурированных данных.
Рисунок 3. У машинного обучения есть несколько стратегий, каждая из которых требует больших объемов данных. Изображение предоставлено WordStream
В заключение, озеро данных - это экземпляр приложения для работы с большими данными. Эти два способа просмотра данных могут работать вместе. Используя как большие данные, так и озеро данных, инженер по управлению может прогнозировать сбои, создавать процедуры обслуживания, расширять цифровую трансформацию предприятия и многое другое.
Для чего вы используете большие данные и озера данных в своей работе?
Интернет вещей
- Датчики и процессоры объединяются для промышленного применения
- Cervoz:выбор подходящего флеш-хранилища для промышленных приложений
- GE представляет облачный сервис для промышленных данных, аналитики
- Перспективы развития промышленного Интернета вещей
- Четыре большие проблемы для промышленного Интернета вещей
- Шесть основных принципов для успешных приложений с сенсорной информацией
- Как разобраться в больших данных:RTU и приложения для управления процессами
- Подготовка почвы к успеху в области науки о промышленных данных
- Для реального понимания промышленного Интернета:не просто собирайте данные, используйте их
- Могут ли большие данные стать панацеей от скудных бюджетов здравоохранения?