


Облачные и периферийные вычисления для Интернета вещей:краткая история
Пограничные вычисления становятся все более популярными в сфере Интернета вещей. В 2018 году это была одна из главных технологических тенденций, заложивших основу для следующего поколения цифрового бизнеса. Параллельно с этим, учитывая огромные объемы данных и необходимость оптимизации вычислительных ресурсов, мы также наблюдаем растущую тенденцию к отправке данных в облако.
Хотя пограничные и облачные вычисления часто рассматриваются как взаимоисключающие подходы, для более крупных проектов Интернета вещей часто требуется сочетание обоих. Чтобы понять сегодняшнее видение Интернета вещей и дополнительных характеристик периферийных и облачных вычислений, мы хотим вернуться во времени и взглянуть на их эволюцию за последние десятилетия.
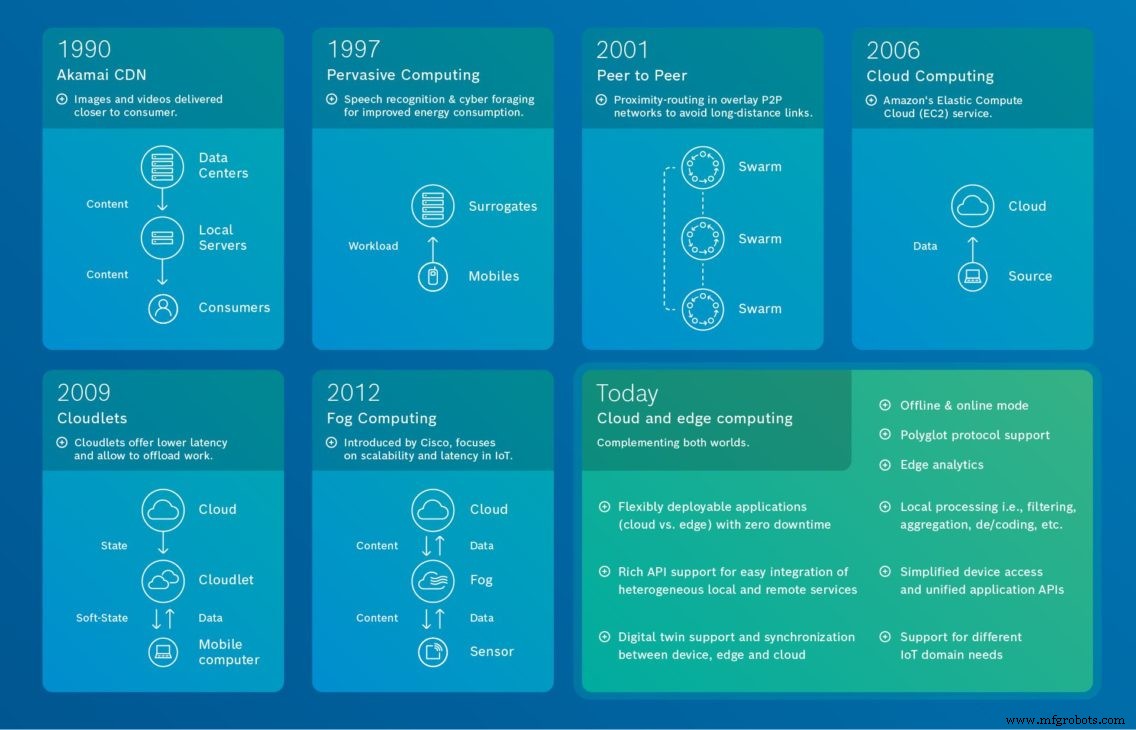 Источник:Bosch.IO Взгляд на историю коммуникационных и распределенных систем показывает, что периферийные вычисления как таковые не новость. Наш рисунок показывает эволюцию периферийных вычислений и заканчивается нашим видением того, как пограничные и облачные вычисления могут быть объединены для обеспечения максимальной отдачи.
Источник:Bosch.IO Взгляд на историю коммуникационных и распределенных систем показывает, что периферийные вычисления как таковые не новость. Наш рисунок показывает эволюцию периферийных вычислений и заканчивается нашим видением того, как пограничные и облачные вычисления могут быть объединены для обеспечения максимальной отдачи. Начало децентрализованных вычислений
Истоки периферийных вычислений восходят к 1990-м годам . , когда Akamai запустила свою сеть доставки контента (CDN) . Тогда идея заключалась в том, чтобы ввести узлы в местах, географически ближе к конечному пользователю, для доставки кэшированного контента, такого как изображения и видео.
В 1997 году , в своей работе «Гибкая адаптация к приложениям для мобильности», Нобель и др. продемонстрировали, как различные типы приложений (веб-браузеры, распознавание видео и речи), работающие на мобильных устройствах с ограниченными ресурсами, могут переносить определенные задачи на мощные серверы (суррогаты). Целью было снизить нагрузку на вычислительные ресурсы. И, как было предложено в более поздней работе, для увеличения времени автономной работы мобильных устройств. Сегодня, например, подобным образом работают сервисы распознавания речи от Google, Apple и Amazon. В 2001 в отношении повсеместных вычислений , Satyanarayanan et al. обобщили этот подход в своей статье «Распространенные вычисления:видение и проблемы».
В 2001 масштабируемые и децентрализованные распределенные приложения используют, как предлагается, различные одноранговые (так называемые распределенные хеш-таблицы) оверлейные сети. Эти самоорганизующиеся оверлейные сети обеспечивают эффективную и отказоустойчивую маршрутизацию, определение местоположения объектов и балансировку нагрузки. Более того, эти системы также позволяют использовать сетевую близость основных физических соединений в Интернете, тем самым избегая междугородных соединений между одноранговыми узлами. Это не только снижает общую нагрузку на сеть, но и сокращает время ожидания приложений.
Облачные вычисления
Облачные вычисления является важным фактором в истории периферийных вычислений и поэтому заслуживает особого упоминания. Особое внимание он привлек в 2006 г. Год, когда Amazon впервые представила свое «Эластичное вычислительное облако». Это открыло множество новых возможностей с точки зрения вычислений, визуализации и емкости памяти.
Тем не менее облачные вычисления как таковые не были решением для всех случаев использования. С появлением беспилотных автомобилей и (промышленного) Интернета вещей, например, все большее внимание уделялось локальной обработке информации, чтобы обеспечить возможность мгновенного принятия решений.
Cloudlets и туманные вычисления
В 2009 , Satyanarayanan et al. ввел термин облачко в своей статье «Пример использования облачных вычислений на основе виртуальных машин в мобильных вычислениях». В этой работе основное внимание уделяется задержке. В частности, в статье предлагается двухуровневая архитектура. Первый уровень известен как облако (высокая задержка), а второй - как облака (более низкая задержка). Последние представляют собой децентрализованные и широко рассредоточенные компоненты интернет-инфраструктуры. Их вычислительные циклы и ресурсы хранения могут использоваться находящимися поблизости мобильными компьютерами. Более того, облачко хранит только мягкое состояние, такое как кэшированные копии данных.
В 2012 , Cisco ввела термин туманные вычисления для распределенных облачных инфраструктур. Цель состояла в том, чтобы способствовать масштабируемости IoT, то есть обрабатывать огромное количество устройств IoT и большие объемы данных для приложений с низкой задержкой в реальном времени.
Облачные и периферийные вычисления для крупномасштабных приложений Интернета вещей
Сегодня , решение IoT должно удовлетворять гораздо более широкий круг требований. Мы видим, что в большинстве случаев организации выбирают сочетание облачных и периферийных вычислений для сложных решений IoT. Облачные вычисления обычно вступают в игру, когда организациям требуется хранилище и вычислительная мощность для выполнения определенных приложений и процессов, а также для визуализации данных телеметрии из любого места. С другой стороны, пограничные вычисления - это правильный выбор в случаях с низкой задержкой, локальными автономными действиями, уменьшенным внутренним трафиком и когда задействованы конфиденциальные данные.
Хотите узнать больше о том, какую выгоду компании получают от облачных и периферийных вычислений при внедрении решений Интернета вещей? Прочтите наше руководство «Edge computing for IoT».
Скачать информационный документИнтернет вещей
- Советы и рекомендации по облачным вычислениям
- Шаблоны программирования и инструменты для облачных вычислений
- Облачные вычисления для малого и среднего бизнеса
- 10 правил, которые следует и нельзя делать для успешной карьеры в области облачных вычислений
- Как гибридное облако обеспечивает основу для пограничных вычислений
- Почему периферийные вычисления для Интернета вещей?
- Использование данных Интернета вещей от края до облака и обратно
- Экономика Интернета вещей - уроки для поставщиков услуг и предприятий
- Являются ли Интернет вещей и облачные вычисления будущим данных?
- Преимущества граничных вычислений для ИИ Кристаллизация