


Считыватель гибких дисков Arduino Amiga (V1)
Компоненты и расходные материалы
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 |
Приложения и онлайн-сервисы
 |
|
Об этом проекте
- Моя цель: Создать простой, дешевый способ с открытым исходным кодом для восстановления данных с гибких дисков Amiga DD из Windows 10 и других операционных систем.
- Мое решение: Arduino + приложение для Windows
- Почему: Чтобы сохранить данные с этих дисков на будущее. Кроме того, обычный ПК не может читать диски Amiga из-за того, как они написаны.
Веб-сайт проекта:http://amiga.robsmithdev.co.uk/
Это V1 проекта. V2 содержит улучшенные возможности чтения и записи!
Опыт работы с Amiga
Я обязан своей карьерой Amiga, в частности A500 +, который мои родители купили мне на Рождество в возрасте 10 лет. Сначала я играл в игры, но через некоторое время мне стало любопытно, на что еще он способен. Я играл с Deluxe Paint III и узнал о Workbench.
Amiga 500 Plus:

Каждый месяц я покупал популярный журнал Amiga Format. Один месяц у меня была бесплатная копия AMOS. Я вошел в формат Amiga Написать игру в AMOS когда AMOS Professional позже был помещен на закрытый диск, он был одним из 12 (я думаю) победителей с In The Pipe Line . А вот за призами за ними действительно надо было гоняться!
AMOS - Создатель:

Фон
Двигаясь дальше, я использовал его как часть моих проектов GCSE и A-Level (благодаря Highspeed Pascal, который был совместим с Turbo Pascal на ПК)
Как бы то ни было, это было давно, и у меня есть коробки с дисками и A500 +, который больше не работает, поэтому я подумал о том, чтобы скопировать эти диски на свой компьютер, как для сохранения, так и для ностальгии.
На веб-сайте Amiga Forever есть отличный список опций, которые включают оборудование и злоупотребление двумя флоппи-дисководами на ПК - К сожалению, ни один из них не подходил для современного оборудования, а контроллеры KryoFlux / Catweasel слишком дороги. Я был очень удивлен, что по большей части это был закрытый код.
Сильно увлекся электроникой и поиграв с устройствами Atmel ( AT89C4051 ) во время учебы в университете я решил взглянуть на Arduino (кредит GreatScott для вдохновения, показывающего, насколько легко начать работу) Я подумал, возможно ли это.
Итак, я поискал в Google чтение с дисковода Arduino кода, и после пропуска всех проектов, которые злоупотребляли стремление играть музыку, я действительно не нашел никаких решений. Я нашел несколько обсуждений в нескольких группах, предполагающих, что это невозможно. Я нашел проект, основанный на FPGA, который был очень интересным для чтения, но не в том направлении, в котором я хотел двигаться, поэтому единственным вариантом было создать решение самостоятельно.
Исследования
Когда я начинал этот проект, я не имел ни малейшего представления о том, как работает дисковод для гибких дисков, и тем более о том, как на них закодированы данные. Следующие веб-сайты были бесценными для моего понимания того, что происходит и как они работают:
- techtravels.org (и эта страница)
- Часто задаваемые вопросы о формате .ADF (файл Amiga Disk) от Лорана Клеви.
- Amiga Forever
- Википедия - Дисковый файл Amiga
- Английский Amiga Board
- QEEWiki - счетчики на ATmega168 / 328
- Распиновка дисковода гибких дисков
- Список форматов гибких дисков.
Предположения
На основе исследования я теперь теоретически знал, как данные записываются на диск и как он вращается.
Я начал придумывать некоторые числа. В зависимости от скорости вращения диска двойной плотности (300 об / мин) и способа хранения данных (80 дорожек, 11 секторов на дорожку и 512 байтов на сектор, закодированные с использованием MFM), для точного чтения данных мне нужно было иметь возможность выборка данных на частоте 500 кГц; это довольно быстро, если учесть, что Arduino работает только на частоте 16 МГц.
В последующих попытках я буду говорить только о стороне Arduino. Перейти к расшифровке.
Попытка 1:
Сначала мне нужно было собрать оборудование и интерфейс к дисководу для гибких дисков. Флоппи-дисковод, который я взял со старого ПК на работе, и заодно схватил его кабель IDE.
Ниже фото освобожденного дисковод гибких дисков от старого ПК:

Изучая распиновку привода, я понял, что мне нужно всего несколько проводов от него, и, посмотрев на привод, я понял, что он также не использует вход 12 В.
Вращение привода было достигнуто выбором привода и включением двигателя. Двигать головой было просто. Вы устанавливаете / DIR контакт высокий или низкий, а затем импульс / STEP штырь. Вы можете определить, достигла ли голова дорожки 0 (первой дорожки), отслеживая / TRK00 штырь.
Мне было интересно узнать о / INDEX штырь. Это пульсирует один раз при каждом обороте. Поскольку Amiga не использует это для поиска начала трека, мне это не нужно, и я могу его проигнорировать. После этого остается только выбрать, с какой стороны диска читать ( / SIDE1 ) и подключение / RDATA .
Из-за требований к высокой скорости передачи данных моей первой мыслью было найти способ уменьшить эту проблему, попытавшись снизить требования к этой скорости.
Планировалось использовать два 8-битных регистра сдвига ( SN74HC594N ), чтобы уменьшить требуемую частоту дискретизации в 8 раз. Я использовал то, что Ebay назвало Pro Mini atmega328 Board 5V 16M Arduino Compatible Nano (так что я не знаю, что это официально, но это работает на Uno!) для буферизации этого параллельного данные и отправьте их на ПК, используя его последовательный / USART интерфейс. Я знал, что это должно быть быстрее, чем 500 Кбод (со всеми дополнительными расходами на последовательный порт).
sn74hc594.pdfОтказавшись от стандартной последовательной библиотеки Arduino, я был очень рад обнаружить, что могу настроить USART на Arduino со скоростью передачи 2 Мбод и с одной из этих коммутационных плат F2DI (eBay назвал ее Базовая коммутационная плата для FTDI FT232RL USB - последовательный порт для Arduino - см. ниже). Я мог бы с радостью отправлять и получать данные с такой скоростью (62,5 кГц), но мне нужно было делать это точно.
Atmel-42735-8-bit-AVR-Microcontroller-ATmega328-328P_Datasheet.pdfКоммутационная плата FTDI, которая идеально подходит для интерфейса на плате Arduino:

Во-первых, я использовал Arduino для установки из 8-битных регистров сдвига только один из 8-ми битов с высокой тактовой частотой. Другой получал сигнал прямо с дисковода гибких дисков (что обеспечивало преобразование из последовательного в параллельный).
Вот безумная картина макета, на котором я построил это в то время:

Я использовал один из таймеров Arduinos для генерации сигнала 500 кГц на одном из его выходных контактов, и поскольку аппаратное обеспечение управляет этим, он очень точен! - Ну, мой мультиметр все равно замерил ровно 500 кГц.
Код работал, я обработал полные 8 бит данных на 62,5 кГц, в результате чего процессор Arduino почти не использовался. Однако я не получил ничего значимого. В этот момент я понял, что мне нужно внимательнее взглянуть на фактические данные, поступающие с флоппи-дисковода. Поэтому я купил дешевый старый осциллограф на eBay (Gould OS300 20Mhz Oscilloscope), чтобы проверить, что происходит.
В ожидании осциллографа я решил попробовать что-нибудь еще.
Фрагмент кода, используемого для чтения данных из регистров сдвига:
void readTrackData () {byte op; for (int a =0; a <5632; a ++) {// Мы будем ждать маркера начала "байта" while (digitalRead (PIN_BYTE_READ_SIGNAL) ==LOW) {}; // Считываем байт op =0; если (digitalRead (DATA_LOWER_NIBBLE_PB0) ==HIGH) op | =1; если (digitalRead (DATA_LOWER_NIBBLE_PB1) ==HIGH) op | =2; если (digitalRead (DATA_LOWER_NIBBLE_PB2) ==HIGH) op | =4; если (digitalRead (DATA_LOWER_NIBBLE_PB3) ==HIGH) op | =8; если (digitalRead (DATA_UPPER_NIBBLE_A0) ==HIGH) op | =16; если (digitalRead (DATA_UPPER_NIBBLE_A1) ==HIGH) op | =32; если (digitalRead (DATA_UPPER_NIBBLE_A2) ==HIGH) op | =64; если (digitalRead (DATA_UPPER_NIBBLE_A3) ==HIGH) op | =128; writeByteToUART (оп); // Ждем, пока максимум снова не упадет while (digitalRead (PIN_BYTE_READ_SIGNAL) ==HIGH) {}; }}
Попытка 2:
Я решил, что сдвиговые регистры, хотя и хорошая идея, наверное, не помогают. Я мог легко прочитать 8 бит за один раз, но мне пришло в голову, что я не могу быть уверен, что все биты были правильно синхронизированы с самого начала. Читая документацию, он предположил, что данные были скорее короткими импульсами, чем максимумами и минимумами.
Я удалил регистры сдвига и задался вопросом, что произойдет, если я попытаюсь проверить наличие импульса от привода в прерывании (ISR), используя ранее настроенный сигнал 500 кГц. Я перенастроил Arduino для генерации ISR, и после того, как я решил, что проблемы с библиотеками Arduino мешают (используя ISR, который мне нужен), я перешел на Timer 2.
Я написал короткую ISR, которая сдвигала бы влево один глобальный байт на один бит, а затем, если бы вывод, подключенный к линии данных флоппи-дисковода, был LOW (импульсы слабые) Я бы поставил на него ИЛИ 1. Каждые 8 раз я записывал завершенный байт в USART.
Все пошло не так, как ожидалось! Arduino начала вести себя очень хаотично и странно. Вскоре я понял, что выполнение ISR занимает больше времени, чем время между обращениями к нему. Я мог получать импульс каждые 2 мкс и в зависимости от скорости Arduino, делая дикое предположение, что каждая инструкция C переведено в 1 цикл машинного кода тактовой частоты Я понял, что у меня может быть не более 32 инструкций. К сожалению, в большинстве случаев было бы более одной инструкции, и после поиска в Google я понял, что накладные расходы на запуск ISR в любом случае были огромными; не говоря уже о том, что функции digitalRead очень медленные.
Я отказался от digitalRead функция в пользу прямого доступа к контактам порта! Это по-прежнему не помогло и было недостаточно быстрым. Не готовый сдаваться, я отложил этот подход и решил пойти дальше и попробовать что-нибудь еще.
В этот момент прибыл осциллограф, который я купил, и он заработал! Прочный старый осциллограф, который, вероятно, был старше меня! Но все равно справился со своей задачей на отлично. (Если вы не знаете, что такое осциллограф, ознакомьтесь с EEVblog # 926 - Introduction To The Oscilloscope, а если вы увлекаетесь электроникой, то я предлагаю посмотреть еще несколько и просмотреть веб-сайт EEVBlog.
Мой недавно приобретенный твердый старый осциллограф (Gould OS300 20Mhz):

После подключения сигнала 500 кГц к одному каналу и выхода с дисковода гибких дисков к другому стало очевидно, что что-то не так. Сигнал 500 кГц представлял собой идеальную прямоугольную волну, использующую его в качестве триггера, данные с дискет были повсюду. Я мог видеть импульсы, но это было больше размыто. Точно так же, если я запускал сигнал от дисковода гибких дисков, прямоугольный сигнал 500 кГц был повсюду и не синхронизировался с ним.
Фотографии кривых срабатывания осциллографа по двум каналам. Вы не совсем видите это, но на канале нет срабатывают тысячи слабых призрачных линий:

По отдельности я мог измерять импульсы обоих сигналов на частоте 500 кГц, что не имело смысла, как если бы они оба работали с одинаковой скоростью, но не запускались, чтобы вы могли правильно видеть оба сигнала, значит, что-то не так.
После долгой игры с уровнями триггеров мне удалось понять, что происходит. Мой сигнал был идеальным 500 кГц, но, глядя на сигнал дисковода гибких дисков, хорошо, что они были расположены правильно, но не всегда. Между группами импульсов произошел дрейф ошибок, а также пропуски в данных, из-за которых сигнал полностью рассинхронизировался.
Вспоминая предыдущие исследования, предполагалось, что привод должен вращаться со скоростью 300 об / мин, но на самом деле это могло не быть точно 300 об / мин, плюс привод, записавший данные, мог также не иметь точно 300 об / мин. Затем есть промежутки между секторами и промежутки между секторами. Очевидно, возникла проблема с синхронизацией, и синхронизация сигнала 500 кГц с дисководом гибких дисков в начале чтения не сработала.
Я также обнаружил, что импульс от дисковода для гибких дисков был очень коротким, хотя вы можете изменить это, изменив подтягивающий резистор, и если время было не совсем правильным, то Arduino может вообще пропустить импульс.
Когда я учился в университете (University of Leicester), я взял модуль под названием встраиваемая система. Мы изучали микроконтроллеры Atmel 8051. Один из проектов заключался в подсчете импульсов от моделируемой метеостанции (энкодера). Тогда я через определенные промежутки времени брал образцы булавки, но это было не очень точно.
Лектор модуля, Проф Понт предложил использовать аппаратный счетчик особенности устройства (я даже не знал, что он был один раз.)
Я проверил техническое описание ATMega328 и убедился, что каждый из трех таймеров может быть настроен на подсчет импульсов, запускаемых с внешнего входа. Это означало, что скорость больше не была проблемой. Все, что мне на самом деле нужно было знать, это то, возник ли импульс в пределах временного окна 2 мкс.
Попытка 3:
Я настроил скетч Arduino для сброса таймера 500 кГц, когда был обнаружен первый импульс, и время выхода таймера 500 кГц переполнено. Я проверил значение счетчика, чтобы увидеть, был ли обнаружен импульс. Затем я выполнил ту же последовательность битового сдвига и каждые 8 бит записал байт в USART.
Поступали данные, и я начал анализировать их на ПК. В данных я начал видеть то, что выглядело как достоверные данные. Появится нечетное слово синхронизации или группы последовательностей 0xAAAA, но ничего надежного. Я знал, что что-то нахожу, но все равно чего-то не хватало.
Попытка 4:
Я понял, что при чтении данных данные с привода, вероятно, не синхронизировались / не совпадали по фазе с моим сигналом 500 кГц. Я подтвердил это, просто прочитав 20 байт каждый раз, когда начал читать.
Читая о том, как справиться с этой проблемой синхронизации, я наткнулся на фразу Phase Locked Loop или PLL. Проще говоря, для того, что мы делаем, контур фазовой автоподстройки частоты будет динамически регулировать тактовую частоту (500 кГц), чтобы компенсировать дрейф частоты и дисперсию сигнала.
Разрешение таймера было недостаточно высоким, чтобы изменять его на достаточно маленькие значения (например, 444 кГц, 470 кГц, 500 кГц, 533 кГц, 571 кГц и т. Д.), И для правильного выполнения этого мне, вероятно, понадобится код, который работал бы намного быстрее.
Таймеры Arduino работают, считая до заранее определенного числа ( в данном случае 16 для 500 кГц ), затем они устанавливают регистр переполнения и снова начинают с нуля. Фактическое значение счетчика может быть прочитано и записано в любой момент.
Я настроил эскиз так, чтобы он ждал в цикле, пока таймер не переполнится, а когда он переполнился, я проверил пульс, как и раньше. На этот раз разница заключалась в том, что когда внутри цикла был обнаружен импульс, я сбрасываю значение счетчика таймера на заранее заданную фазу положение, эффективно повторно синхронизируя таймер с каждым импульсом.
Я выбрал значение, записанное в счетчик таймера, так, чтобы он переполнялся через 1 мксек от импульса обнаружения (на полпути), так что в следующий раз, когда таймер переполнится, импульс будет на расстоянии 2 мксек.
Это сработало! Теперь я читал с диска почти идеальные данные. Я все еще получал много ошибок контрольной суммы, что меня раздражало. Я решил большинство из них, постоянно перечитывая одну и ту же дорожку на диске, пока у меня не были все 11 секторов с действительными заголовками и контрольными суммами данных.
Мне было любопытно в этот момент, поэтому я снова подключил все это к осциллографу, чтобы увидеть, что сейчас происходит, и, как я догадался, теперь я мог видеть обе кривые, поскольку они оба оставались синхронизированными друг с другом:

Мне бы хотелось, чтобы это стало немного яснее. Если кто-то захочет подарить мне прекрасный цифровой осциллограф высшего класса (например, один из таких осциллографов Keysight!), Я был бы очень признателен!
Попытка 5:
Я подумал, смогу ли я улучшить это. Глядя на код, в частности на внутренний цикл чтения (см. Ниже), у меня был цикл while, ожидающий переполнения, а затем внутренний if ищу импульс для синхронизации.
Фрагмент кода, используемый для чтения данных и синхронизации с ними:
register bool done =false; // Ждем переполнения 500 кГц while (! (TIFR2 &_BV (TOV2))) {// обнаружен спад фронта при ожидании импульса 500 кГц. if ((TCNT0) &&(! done)) {// обнаружен импульс, сбрасываем счетчик таймера для синхронизации с импульсом TCNT2 =phase; // Подождите, пока пульс снова не станет высоким, пока (! (PIN_RAW_FLOPPYDATA_PORT &PIN_RAW_FLOPPYDATA_MASK)) {}; сделано =правда; }} // Сбрасываем флаг переполнения TIFR2 | =_BV (TOV2); // Обнаружили ли мы импульс от привода? If (TCNT0) {DataOutputByte | =1; TCNT0 =0;}
Я понял, что в зависимости от того, какая инструкция выполнялась в вышеуказанных циклах, время между обнаружением импульса и записью TCNT2 =phase; может измениться за время, необходимое для выполнения нескольких инструкций.
Понимая, что это может вызывать некоторые ошибки / дрожание в данных, а также с указанным выше циклом, возможно, я действительно пропустил импульс от привода (таким образом, пропущен бит повторной синхронизации), я решил воспользоваться одной из своих более ранних попытки, ISR (прерывание).
Я подключил импульс данных ко второму выводу на Arduino. Данные были теперь подключены к триггеру COUNTER0, а теперь также к выводу INT0. INT0 является одним из наивысших приоритетов прерывания, поэтому следует минимизировать задержки между триггером и вызываемым ISR, и поскольку это единственное прерывание, которое меня действительно интересует, все остальные отключены.
Все, что требовалось для прерывания, - это выполнить приведенный выше код повторной синхронизации, это изменило код, чтобы он выглядел следующим образом:
// Ждем переполнения 500 кГц while (! (TIFR2 &_BV (TOV2))) {} // Сбрасываем флаг переполнения TIFR2 | =_BV (TOV2); // Обнаружили ли мы импульс от привода? If (TCNT0) {DataOutputByte | =1; TCNT0 =0;} ISR выглядела так:(обратите внимание, что я не использовал attachInterrupt, так как это также увеличивает накладные расходы на вызов).
изменчивый байт targetPhase; ISR (INT0_vect) {TCNT2 =targetPhase;} При компиляции получилось слишком много кода, чтобы его можно было выполнить достаточно быстро. Собственно разборка вышеперечисленного произведена:
push r1push r0in r0, 0x3f; 63push r0eor r1, r1push r24 lds r24, 0x0102; 0x800102 sts 0x00B2, r24; 0x8000b2 pop r24pop r0out 0x3f, r0; 63pop r0pop r1reti Анализируя код, я понял, что на самом деле мне нужно всего несколько инструкций. Заметив, что компилятор будет отслеживать все регистры, которые я нарушил, я изменил ISR следующим образом:
изменчивый байт targetPhase asm ("targetPhase"); ISR (INT0_vect) {asm volatile ("lds __tmp_reg__, targetPhase"); asm volatile ("sts% 0, __tmp_reg__"::"M" (_SFR_MEM_ADDR (TCNT2)));} Которую разобрал, выдал такую инструкцию:
push r1push r0in r0, 0x3f; 63push r0eor r1, r1lds r0, 0x0102; 0x800102 sts 0x00B2, r0; 0x8000b2 pop r0out 0x3f, r0; 63pop r0pop r1reti По-прежнему слишком много инструкций. Я заметил, что компилятор добавлял много дополнительных инструкций, которые для моего приложения действительно не требовались. Итак, я поискал ISR () и наткнулся на второй параметр ISR_NAKED. Добавление этого помешает компилятору добавить какой-либо специальный код, но тогда я буду нести ответственность за правильное обслуживание регистров, стека и возврат из прерывания. Мне также нужно было бы поддерживать регистр SREG, но, поскольку ни одна из команд, которые мне нужно было вызвать, не изменила его, мне не нужно было об этом беспокоиться.
Это изменило код ISR на:
ISR (INT0_vect, ISR_NAKED) {asm volatile ("push __tmp_reg__"); // Сохранение tmp_register asm volatile ("lds __tmp_reg__, targetPhase"); // Копируем значение фазы в tmp_register asm volatile ("sts% 0, __tmp_reg__"::"M" (_SFR_MEM_ADDR (TCNT2))); // Копируем tmp_register в то место памяти, где TCNT2 является asm volatile ("pop __tmp_reg__"); // Восстанавливаем tmp_register asm volatile ("reti"); // И выходим из ISR} В какой компилятор преобразовал:
push r0lds r0, 0x0102; 0x800102 sts 0x00B2, r0; 0x8000b2 pop r0reti Пять инструкций! Идеально, или, по крайней мере, так быстро, как должно было быть, теоретически для выполнения требуется 0,3125 мксек! Теперь это должно означать, что повторная синхронизация должна происходить через определенные промежутки времени после импульса. Ниже представлена временная диаграмма происходящего. Вот как вы восстанавливаете данные из последовательного канала данных, у которого нет тактового сигнала:
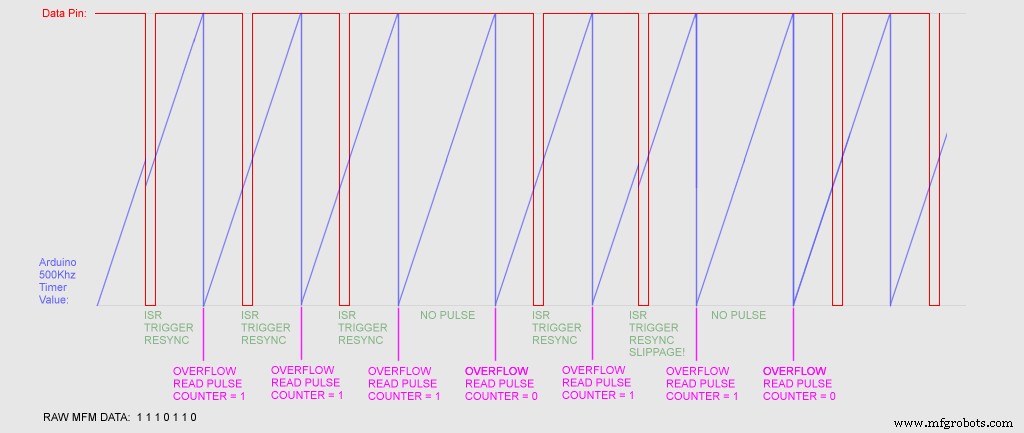
Это немного улучшило результаты. Это все еще не идеально. Некоторые диски прекрасно читаются каждый раз, некоторые диски требуют времени и повторных попыток. Я не уверен, что это из-за того, что некоторые диски так долго сидели там, что магнетизм упал до такого низкого уровня, что усилители привода не могут с этим справиться. Мне стало интересно, связано ли это с дисководом для гибких дисков на ПК, поэтому я подключил его к внешнему дисководу для гибких дисков Amiga, который у меня был, но результаты были идентичными.
Попытка 6:
Я задавался вопросом, можно ли еще что-нибудь сделать. Возможно, сигнал от привода был более шумным, чем я думал. Прочитав дополнительную информацию, я обнаружил, что подтягивающий резистор 1 кОм был нормой, подаваемой на триггер Шмитта.
После установки шестигранного триггера Шмитта SN74HCT14N и перенастройки скетча для срабатывания по нарастающим фронтам, а не по спадающим, я попробовал, но на самом деле это не дало заметной разницы. Я полагаю, поскольку я искал один или несколько импульсов каждый раз, когда это, вероятно, поглощено в любом случае шум. Так что воткнем метод Attempt 5!
sn74hct14.pdfМое последнее макетное решение выглядело так:

Обратите внимание, что схема выше немного отличается от схемы в реальном времени. Я повторно заказал некоторые контакты Arduino, чтобы упростить принципиальную схему.
Попытка 7:
Я был немного недоволен некоторыми дисками, которые не читал. Иногда диски просто неправильно вставлялись в дисковод. Думаю, пружина на ставне не помогла.
Я начал искать, есть ли какие-либо ошибки в фактических данных MFM, полученных с диска.
Из правил того, как работает кодирование MFM, я понял, что можно применить несколько простых правил следующим образом:
- Не может быть двух битов "1" рядом друг с другом.
- Рядом не может быть более трех битов "0".
Во-первых, при декодировании данных MFM я посмотрел, есть ли две единицы подряд. Если бы это было так, я бы предположил, что данные со временем стали немного размытыми, и проигнорировал вторую «1».
При применении этого правила есть буквально три ситуации по 5 бит, когда ошибки остаются. Это была бы новая область, в которой я мог бы улучшить данные.
Но в основном я был удивлен, что ошибок MFM обнаружено не так уж и много. Меня немного смущает, почему некоторые диски не читаются, если ошибок не обнаружено.
Это область для дальнейшего исследования.
Расшифровка
Прочитав, как работает MFM, я не совсем понял, как он правильно выровнен.
Сначала я подумал, что привод выводит единицы и нули для битов включения и выключения. Это было не так. Привод выдает импульс для каждого фазового перехода, то есть:каждый раз, когда данные меняются от 0 до 1 или от 1 до 0.
Прочитав это, я подумал, нужно ли мне преобразовать это обратно в единицы и нули, введя их в триггер, или прочитать данные, выполнить поиск секторов, и, если ничего не было найдено, инвертируйте данные и попробуйте снова!
Оказывается, дело обстоит не так и все намного проще. Импульсы на самом деле являются данными RAW MFM и могут быть поданы прямо в алгоритмы декодирования. Теперь, когда я понял это, я начал писать код для сканирования буфера с диска и поиска слова синхронизации 0x4489. На удивление я его нашел!
Из проведенного мной исследования я понял, что мне действительно нужно искать 0xAAAAAAAA44894489 (в примечании к исследованию также говорится, что в раннем коде Amiga были некоторые ошибки, из-за которых указанная выше последовательность не была найдена. Поэтому вместо этого я поискал 0x2AAAAAAA44894489 после операции И с данными с помощью 0x7FFFFFFFFFFFFFFF ).
Как и ожидалось, я обнаружил до 11 таких на каждой дорожке, соответствующих фактическому началу 11 секторов Amiga. Затем я начал читать следующие байты, чтобы посмотреть, могу ли я расшифровать информацию о секторе.
Я взял фрагмент кода из одной из приведенных выше ссылок, чтобы помочь с декодированием MFM. Нет смысла изобретать колесо заново, а?
Прочитав заголовок и данные, я попытался записать их на диск в виде файла ADF. Стандартный формат файла ADF очень прост. Буквально это всего лишь 512 байтов из каждого сектора (с обеих сторон диска), записанные по порядку. После его написания и попытки открыть его с помощью ADFOpus и получили неоднозначные результаты, иногда он открывал файл, иногда - сбой. В данных явно были ошибки. Я начал смотреть на поля контрольной суммы в заголовке, отклоняя сектора с недопустимыми контрольными суммами и повторяя чтение, пока у меня не будет 11 действительных.
Для некоторых дисков это было все 11 при первом чтении, для некоторых потребовалось несколько попыток и разные значения фазы.
Наконец, мне удалось написать допустимые файлы ADF. Некоторые диски потребуют времени, некоторые буквально со скоростью, с которой их прочитала бы Амига. Поскольку у меня больше не было работающей Amiga, я не мог проверить, нормально ли читаются эти диски, они годами хранились в ящике на чердаке, так что вполне могли испортиться.
Итак, что дальше?
Следующее уже произошло - Версия 2 доступна здесь и улучшена поддержка чтения и письма!
Ну, во-первых, я сделал весь проект бесплатным и с открытым исходным кодом под GNU General Public License V3. Если мы хотим иметь хоть какую-то надежду на сохранение Amiga, тогда мы не должны грабить друг друга за эту привилегию, и, кроме того, я хочу вернуть лучшую платформу, над которой я когда-либо работал. Я также надеюсь, что люди разовьют эту идею, пойдут дальше и продолжат делиться.
Далее я хочу посмотреть на другие форматы. Файлы ADF хороши, но они работают только с дисками, отформатированными AmigaDOS. Есть много заголовков с настраиваемой защитой от копирования и нестандартными форматами секторов, которые просто не поддерживаются этим форматом.
Согласно Википедии, существует еще один формат дисковых файлов - формат FDI. Универсальный формат, хорошо задокументированный. Преимущество этого формата в том, что он пытается сохранить данные трека как можно ближе к оригиналу, поэтому мы надеемся, что это решит указанные выше проблемы!
Я также наткнулся на Общество сохранения программного обеспечения, в частности CAPS (формально Classic Amiga Preservation Society ) и их формат IPF. После небольшого чтения я был очень разочарован, все было закрыто, и мне показалось, что они просто использовали этот формат для продажи своего оборудования для чтения дисков.
Так что мое внимание будет сосредоточено на ПИИ! формат. Меня беспокоит только целостность данных. Мне не нужно будет проверять контрольные суммы, чтобы убедиться, что чтение было правильным, но у меня есть несколько идей, чтобы решить эту проблему!
И, наконец, я также буду искать его, добавив опцию записи на диск (возможно, с поддержкой FDI, а также ADF), так как это действительно не должно быть так сложно добавить.
Код
Репозиторий GitHub
Эскиз Arduino и исходный код Windows https://github.com/RobSmithDev/ArduinoFloppyDiskReaderСхема
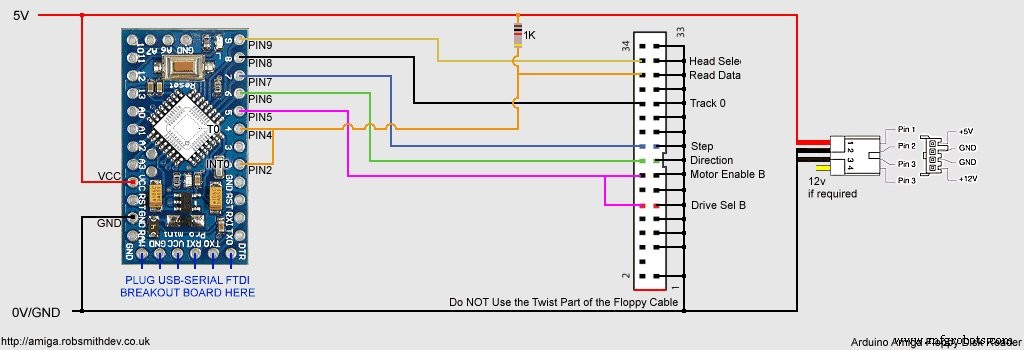
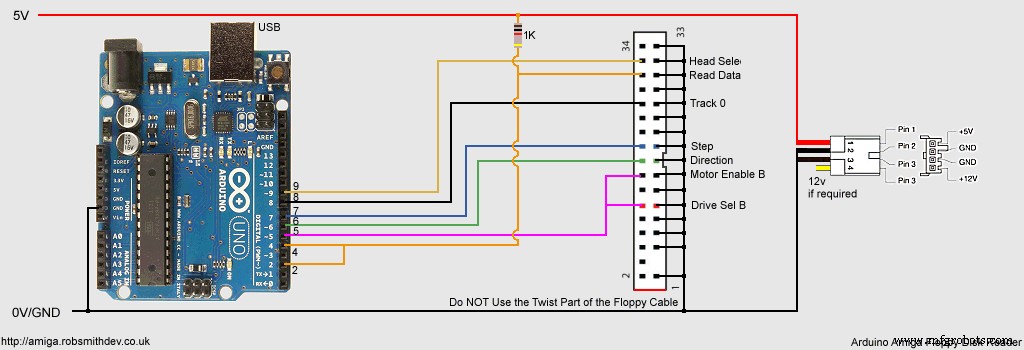
Производственный процесс