


Как обширные цепочки обработки сигналов заставляют голосовых помощников "просто работать"
Умные колонки и устройства с голосовым управлением становятся все более популярными, а голосовые помощники, такие как Amazon Alexa и помощник Google, все лучше и лучше понимают наши запросы.
Одно из главных преимуществ такого интерфейса - то, что он «просто работает» - нет пользовательского интерфейса, который нужно изучать, и мы все чаще можем разговаривать с гаджетом на естественном языке, как если бы это был человек, и получать полезный ответ. Но для достижения этой возможности необходимо выполнить огромное количество сложных операций.
В этой статье мы рассмотрим архитектуру решений с голосовым управлением, обсудим, что происходит внутри, а также необходимое оборудование и программное обеспечение.
Поток сигналов и архитектура
Хотя существует много типов устройств с голосовым управлением, основные принципы и поток сигналов схожи. Давайте рассмотрим умный динамик, такой как Amazon Echo, и рассмотрим основные задействованные подсистемы и модули обработки сигналов.
На рисунке 1 показана общая сигнальная цепочка умного динамика.
щелкните, чтобы увеличить изображение
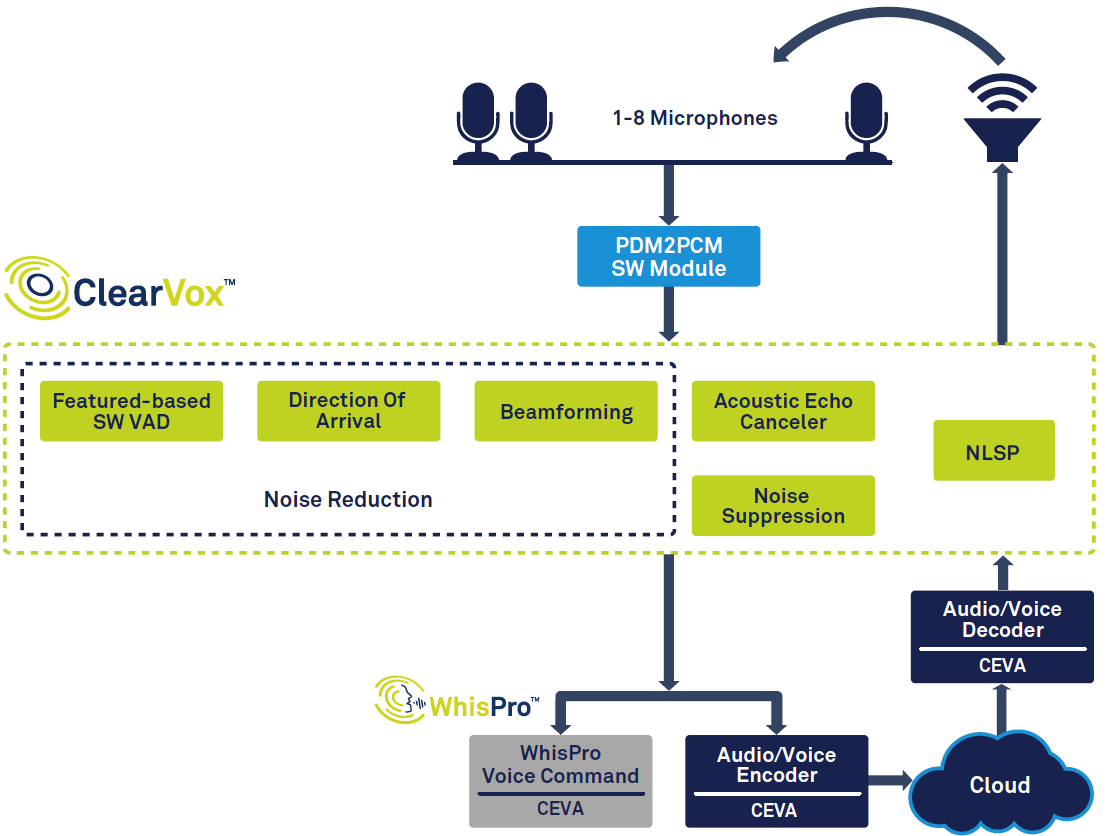
Рис. 1. Цепочка сигналов для голосового помощника на основе CEVA ClearVox и WhisPro. (Источник:CEVA)
Начиная с левой стороны диаграммы, вы можете видеть, что после того, как голос обнаружен с помощью функции обнаружения голосовой активности (VAD), он оцифровывается и проходит через несколько этапов обработки сигнала, чтобы улучшить четкость голоса от голоса желаемого основного говорящего. направление прибытия. Оцифрованные обработанные голосовые данные затем передаются на серверную обработку речи, которая может происходить частично на периферии (на устройстве), а частично в облаке. Наконец, при необходимости создается ответ, который выводится динамиком, для чего требуется декодирование и цифро-аналоговое преобразование.
Для других приложений могут быть некоторые различия и разные приоритеты - например, голосовой интерфейс в автомобиле необходимо оптимизировать для обработки типичного фонового шума в автомобилях. Также наблюдается общая тенденция к снижению энергопотребления и снижению затрат, что обусловлено спросом на устройства меньшего размера, такие как наушники-вкладыши и недорогую бытовую технику.
Внешняя обработка сигналов
После того, как голос был обнаружен и оцифрован, необходимо выполнить несколько задач по обработке сигнала. Помимо внешнего шума, нам также необходимо учитывать звуки, создаваемые подслушивающим устройством, например, интеллектуальным динамиком, воспроизводящим музыку, или разговором с человеком, говорящим на другом конце линии. Чтобы подавить эти звуки, устройство использует акустическое эхоподавление (AEC), поэтому пользователь может вмешаться и прервать умный динамик, даже если он уже воспроизводит музыку или разговаривает. После удаления этих эхо-сигналов для устранения внешнего шума используются алгоритмы шумоподавления.
Хотя существует множество различных приложений, мы можем разделить их на две группы для устройств с голосовым управлением:прием голоса в ближнем и дальнем поле. Устройства ближнего поля, такие как гарнитуры, наушники, наушники и носимые устройства, держат или носят возле рта пользователя, в то время как устройства дальнего поля, такие как интеллектуальные колонки и телевизоры, предназначены для прослушивания голоса пользователя из другого конца комнаты.
Устройства ближнего поля обычно используют один или два микрофона, но устройства дальнего поля часто используют от трех до восьми. Причина этого в том, что устройство дальнего поля сталкивается с большим количеством проблем, чем устройство ближнего поля:по мере того, как пользователь удаляется, его голос, доходящий до микрофонов, становится все тише, а фоновый шум остается на том же уровне. В то же время устройство также должно отделять прямой голосовой сигнал от отражений от стен и других поверхностей, то есть реверберации.
Чтобы справиться с этими проблемами, устройства дальнего поля используют метод, называемый формированием луча. При этом используются несколько микрофонов и вычисляется направление источника звука на основе разницы во времени между звуковыми сигналами, поступающими на каждый микрофон. Это позволяет устройству игнорировать отражения и другие звуки и просто слушать пользователя, а также отслеживать его движение и увеличивать масштаб для правильного голоса там, где разговаривают несколько человек.
Для умных динамиков еще одна ключевая задача - распознать «триггерное» слово, такое как «Алекса». Поскольку говорящий всегда слушает, это распознавание триггера вызывает проблемы с конфиденциальностью - если звук пользователя всегда загружается в облако, даже когда он не произносит триггерное слово, чувствуют ли они себя комфортно, когда Amazon или Google слышат все их разговоры? Вместо этого может быть предпочтительнее обрабатывать распознавание триггера, а также многие популярные команды, такие как «увеличение громкости» локально на самом интеллектуальном динамике, при этом звук отправляется в облако только после того, как пользователь запустил более сложную команду.
Наконец, образец чистого голоса должен быть закодирован перед отправкой в облачный сервер для дальнейшей обработки.
Специализированные решения
Из приведенного выше описания ясно, что интерфейсная обработка голоса должна уметь обрабатывать множество задач. Он должен делать это быстро и точно, а для устройств с батарейным питанием потребление энергии должно быть сведено к минимуму - даже когда устройство всегда ожидает триггерного слова.
Для удовлетворения этих требований универсальные процессоры цифровых сигналов (DSP) или микропроцессоры вряд ли будут соответствовать задаче - с точки зрения стоимости, производительности обработки, размера и энергопотребления. Вместо этого лучшим решением, вероятно, будет DSP для конкретного приложения со специальными функциями обработки звука и оптимизированным программным обеспечением. Выбор аппаратного / программного решения, которое уже оптимизировано для задач голосового ввода, также снизит затраты на разработку и существенно сократит время вывода на рынок, а также снизит общие затраты.
Например, ClearVox CEVA - это программный набор алгоритмов обработки голосового ввода, который может справляться с различными акустическими сценариями и конфигурациями микрофона, включая направление голоса говорящего, формирование луча с помощью нескольких микрофонов, подавление шума и подавление акустического эха. ClearVox оптимизирован для эффективной работы на звуковых DSP CEVA, чтобы обеспечить экономичное решение с низким энергопотреблением.
Помимо обработки голоса, пограничному устройству потребуется способность обрабатывать обнаружение триггерного слова. Специализированное решение, такое как CEVA WhisPro, является отличным способом добиться необходимой точности и низкого энергопотребления (см. Рисунок 2). WhisPro - это программный пакет для распознавания речи на основе нейронной сети, доступный исключительно для DSP CEVA, который позволяет OEM-производителям добавлять голосовую активацию в свои продукты с поддержкой голоса. Он может обрабатывать постоянно включенное прослушивание, в то время как основной процессор остается в спящем режиме до тех пор, пока он не понадобится, что значительно снижает общее энергопотребление системы.
щелкните, чтобы увеличить изображение
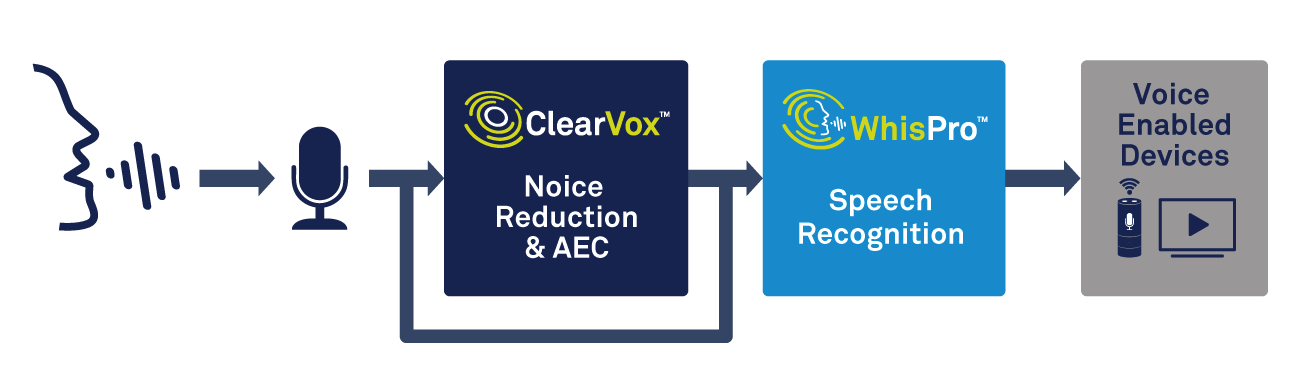
Рисунок 2:использование обработки голоса и распознавания речи для голосовой активации. (Источник:CEVA)
WhisPro может достигать уровня распознавания более 95% и может поддерживать несколько триггерных фраз, а также настраиваемые триггерные слова. Любой, кто использовал умный динамик, может засвидетельствовать, что заставить его надежно реагировать на пробуждающее слово - даже в шумной обстановке - иногда может быть неприятно. Правильное использование этой функции может существенно повлиять на восприятие потребителями качества продукта с голосовым управлением.
Распознавание речи:локальное или облачное
После того, как голос был оцифрован и обработан, нам понадобится функция автоматического распознавания речи (ASR). Существует широкий спектр технологий ASR, начиная от простого определения ключевых слов, требующего от пользователя произносить определенные ключевые слова, до сложной обработки естественного языка (NLP), когда пользователь может разговаривать нормально, как если бы обращался к другому человеку.
Обнаружение ключевых слов имеет множество применений, даже если его словарный запас чрезвычайно ограничен. Например, простое устройство умного дома, такое как выключатель света или термостат, может просто реагировать на несколько команд, таких как «включить», «выключить», «ярче», «диммер» и так далее. Этот уровень ASR можно легко обрабатывать локально, на периферии, без подключения к Интернету, что снижает расходы, обеспечивает быстрое реагирование и позволяет избежать проблем с безопасностью и конфиденциальностью.
Другой пример:многим смартфонам Android можно приказать сделать снимок, сказав «сыр» или «улыбка», тогда как отправка команды в облако займет слишком много времени. И это при условии, что подключение к Интернету доступно, что не всегда будет иметь место для таких устройств, как умные часы или наушники.
С другой стороны, многие приложения требуют NLP. Если вы хотите спросить у своего динамика Echo о погоде или найти отель на ночь, вы можете сформулировать свой вопрос по-разному. Устройство должно уметь понимать возможные нюансы и разговорные выражения в команде, а также надежно определять, о чем просят. Проще говоря, он должен уметь преобразовывать речь в смысл, а не просто речь в текст.
Возьмем, к примеру, наш запрос на гостиницу. Вы можете спросить о множестве возможных факторов:цене, местонахождении, отзывах и многих других. Система НЛП должна интерпретировать всю эту сложность, а также множество разных способов формулировки вопроса и отсутствие ясности в запросе - фраза «найди мне хороший отель в центре» будет означать разные вещи для разных люди. Для получения точных результатов устройство также должно учитывать контекст вопроса и распознавать, когда пользователь задает связанные дополнительные вопросы или запрашивает несколько частей информации в одном запросе.
Это может потребовать огромного объема обработки, обычно с использованием искусственного интеллекта (AI) и нейронных сетей, что в большинстве случаев нецелесообразно для обработки только на границе. Недорогое устройство со встроенным процессором не сможет справиться с поставленными задачами. В этом случае правильный вариант - отправить оцифрованную речь для обработки в облаке. Там его можно интерпретировать и отправить соответствующий ответ обратно на устройство с голосовым управлением.
Вы можете видеть, что существует компромисс между пограничной обработкой на устройстве и удаленной обработкой в облаке. Обработка всего на местном уровне может быть быстрее и не зависит от наличия подключения к Интернету, но будет бороться с более широким кругом вопросов и сбором информации. Это означает, что для устройства общего назначения, такого как умный динамик в доме, необходимо передать хотя бы часть обработки в облако.
Чтобы устранить недостатки облачной обработки, ведутся разработки возможностей локальных процессоров, и в ближайшем будущем мы можем ожидать больших улучшений в NLP и AI на периферийных устройствах. Новые методы сокращают объем требуемой памяти, а процессоры продолжают работать быстрее и потреблять меньше энергии.
Например, семейство маломощных ИИ-процессоров CEVA NeuPro обеспечивает сложные возможности для периферийных устройств. Основываясь на опыте CEVA в области нейронных сетей для компьютерного зрения, это семейство представляет собой гибкое масштабируемое решение для обработки речи на устройстве.
Выводы
Интерфейсы с голосовым управлением быстро становятся важной частью нашей повседневной жизни и в ближайшем будущем будут добавлены во все больше и больше продуктов. Улучшения обусловлены улучшенными возможностями обработки сигналов и распознавания голоса, а также более мощными вычислительными ресурсами как локально, так и в облаке.
Чтобы соответствовать требованиям производителей комплектного оборудования, компоненты, используемые для обработки звука и распознавания речи, должны отвечать ряду сложных задач с точки зрения производительности, стоимости и мощности. Для многих дизайнеров решения, специально оптимизированные для решения поставленных задач, вполне могут оказаться лучшим подходом - удовлетворить потребности конечных клиентов и сократить время вывода продукта на рынок.
Независимо от технологии, на которой они основаны, голосовые интерфейсы станут более точными, и с ними будет легче разговаривать на повседневном языке, а их снижение стоимости сделает их более привлекательными для производителей. Это будет интересное путешествие, чтобы увидеть, для чего они будут использоваться в следующий раз.
Встроенный
- Расширенные технологии ускорят принятие голосовых помощников
- Как сделать стекловолокно
- Как максимально эффективно использовать свою цепочку поставок прямо сейчас
- Как работают системы SCADA?
- Как сделать компас с помощью Arduino и Processing IDE
- Как сделать прототип
- Как работают осушители воздуха?
- Как сделать электронику завтрашнего дня, используя графен для струйной печати
- Как работают электрические тормоза
- Как заставить комплексную программу безопасности работать